写在前面的话
我的毕业论文写的是项目进度风险管理,其实基本的路子就是大家都熟悉的,根据项目的生命周期,利用很多方法对风险进行识别---风险评估-- 风险管理监控等等,当然这都不是重点。重点是风险评估,利用什么方法进行评估,以及数据处理。 当然我这边用了dematel、层次分析法与模糊综合评价法。
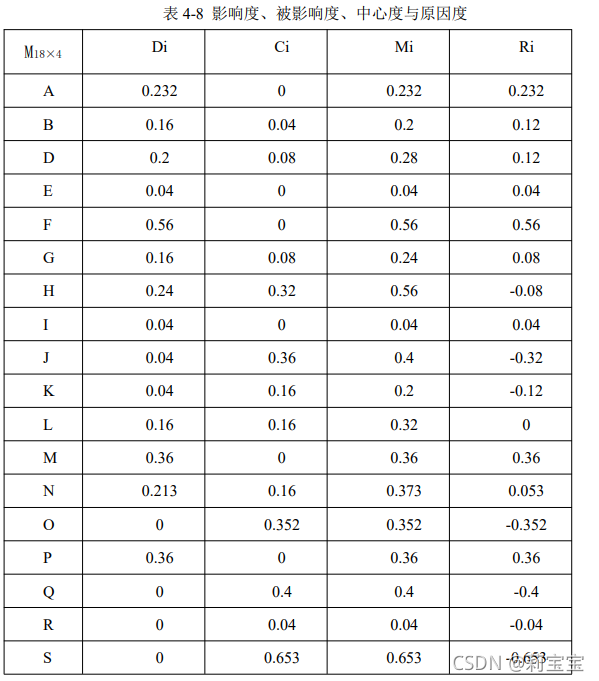
因为我的数据量实在是太大了。让大家看个我一个小小节的数据,这个是结果,但是大家可以看到,这就有18个要素进行分析,实在是很头疼。因此我就想到了用python写代码来实现我的数据分析。今天的文章没有太多的干货,只是我自己觉得有意思,就写一下,我自己也是因为需要学习的,算是一个入门,不精通。写出来一个是让自己有所输入有所输出,其次是希望爱好的同学,大家一起学习,争取能学友所有,为自己平时的工作学习生活带来便利。
一、DEMATEL
下面是百度百科截图的部分解释。
DEMATEL也有翻译成决策与试验评价实验室,或者简称实验室法。由于中文比较拗口,一般情况下,念[de mei tel] 或者念 [di mie tel]。
1971年在日内瓦的一次会议上美国Battelle实验室的学者A. Gabus和E. Fontela提出的为了解现实世界中复杂、困难的问题而提出的方法论,是一种运用图论和矩阵工具的系统分析的方法。
通过系统中各要素之间的逻辑关系和直接影响矩阵,可以计算出每个要素对其它要素的影响度以及被影响度,从而计算出每个要素的原因度与中心度,作为构造模型的依据,从而确定要素间的因果关系和每个要素在系统中的地位。
具体的也可以看我附上的链接 http://www.huaxuejia.cn/ism/DEMATEL_online.php
那么这么多的要素,如何用代码实现呢?
1、安装numpy以及matplotlib
pip install numpy
pip install matplotlib

2、根据dematel方法实施步骤代码编写
这里就不透露我的原始数据了,我就随机生成几个数据方便下面的计算吧。
2.1 确定初始影响矩阵
各因素的影响矩阵通过随机生成,现在我们生成一个10*10的10阶初始影响矩阵
W = np.random.randint(0,10,(10,10))
print(W)
运行结果:
[[4 7 0 0 0 9 4 1 4 0]
[0 4 4 1 9 2 7 3 5 1]
[4 9 8 9 7 0 7 9 2 3]
[5 8 3 7 3 0 9 4 8 0]
[4 6 3 8 6 0 6 7 8 7]
[0 0 9 3 9 2 7 1 4 4]
[3 2 5 8 2 7 1 4 9 7]
[7 7 8 9 8 5 0 0 2 4]
[7 4 8 7 6 9 2 1 4 5]
[5 9 5 0 6 7 7 5 7 9]]
2.2.规范化初始影响矩阵
1.按行求和
Q1=W.sum(axis=1)
2.矩阵按行除以按行求和的值
公式: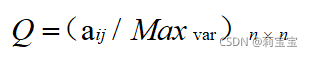
Q = np.zeros(shape=(10,10))
for i in range(10): Q[i] = np.divide(W[i],Q1[i]) print(Q) 运行结果: [[0.29032258 0. 0.19354839 0.25806452 0.12903226 0. 0. 0. 0.12903226 0. ] [0.19047619 0.14285714 0.07142857 0.21428571 0.07142857 0.04761905 0.16666667 0. 0.04761905 0.04761905] [0.04347826 0.10869565 0.06521739 0.04347826 0.15217391 0.17391304 0. 0.19565217 0.15217391 0.06521739][0.1875 0.0625 0.03125 0.09375 0.09375 0.09375 0.15625 0.03125 0.15625 0.09375 ] [0.06122449 0.16326531 0.16326531 0.12244898 0.16326531 0.06122449 0.14285714 0.04081633 0.02040816 0.06122449] [0.06818182 0.09090909 0.20454545 0. 0. 0.18181818 0.18181818 0.13636364 0.09090909 0.04545455] [0.05128205 0.05128205 0.02564103 0.20512821 0.17948718 0.05128205 0.12820513 0.05128205 0.17948718 0.07692308] [0.19565217 0.17391304 0.15217391 0.06521739 0.15217391 0.10869565 0.02173913 0.02173913 0.04347826 0.06521739] [0.03448276 0.24137931 0.06896552 0.03448276 0.10344828 0.24137931 0. 0.17241379 0. 06896552 0.03448276] [0.2195122 0.17073171 0.09756098 0.17073171 0.14634146 0. 0.04878049 0. 0.14634146 0. ]]
2.3计算综合影响矩阵
公式:![]()
I指的是单位矩阵
I=np.identity(10)#单位矩阵
np.linalg.inv(I-Q)#I-Q逆矩阵 T=Q*np.linalg.inv(I-Q)
2.4计算影响度、被影响度、中心度与原因度
C=T.sum(axis=0)#被影响度 D=T.sum(axis=1)#影响度 R=D-C#原因度 M=C+D#中心度
2.5生成图表
import matplotlib.pyplot as plt
l=["A","B","C",'D','E',"F","G","H","I","J","K","L","M","N"]
plt.figure()
plt.rcParams['font.sans-serif']=['SimHei']#plt.title显示中文的问题
plt.rcParams['axes.unicode_minus'] = False
plt.plot(M, R,color='green',linestyle="-",marker='o')
plt.xlabel("中心度")
plt.ylabel("原因度")
plt.title("中心度原因度二维图")
i=0
for a, b in zip(M, R):
str_label = l[i]
i=i+1
plt.text(a, b, str_label, ha='center', va='bottom', fontsize=10)#为每一个点打标签
plt.show()
plt.savefig("easyplot.jpg")#保存生成的二维图
最后生成的图:

二、AHP(层次分析法)
层次分析法也是对照着方法的思路进行编写代码即可.
模糊综合评价也是如此.就不放代码了.思路跟上面的dematel一样.
写在最后:
1.其实还有更好的架包让我们使用,比如pandas等
2.在我写论文的时候,只是觉得数据量太大,需要处理,就百度搜索,一步一步完成的.并不是很完美,但是起码结果出来了.目前准备入坑学习一下这部分.
当然附上numpy的菜鸟链接 https://www.runoob.com/numpy/numpy-tutorial.html
感兴趣的可以学习一番
3.原始数据都会有保留,代码也可以通过读excel的方式,将原始数据拿到进行处理.并将得到的最后结果写入到excel中.