模块融合:将一些相邻模块进行融合以提高计算效率,比如conv+relu或者conv+batch normalization+relu,最常提到的BN融合指的是conv+bn通过计算公式将bn的参数融入到weight中,并生成一个bias;

上图详细描述了BN层计算原理以及如何融合卷积层和BN层,这里进行验证:
定义三个模型:
定义模型1 : 一层卷积层和一层BN层网络
import numpy as np
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvWithBn(nn.Module):
def __init__(self, ):
super(ConvWithBn, self).__init__()
self.conv1 = nn.Conv2d(3, 8, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(8)
self._initialize_weights()
def forward(self, x):
x = self.bn1(self.conv1(x))
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(0, 1)
m.bias.data.normal_(0, 1)
m.running_mean.data.normal_(0, 1)
m.running_var.data.uniform_(1, 2)定义模型2 : 一个卷积层网络,和上面卷层配置相同¶
class Conv(nn.Module):
def __init__(self, ):
super(Conv, self).__init__()
self.conv1 = nn.Conv2d(3, 8, kernel_size=3, stride=1, padding=1, bias=False)
def forward(self, x):
x = self.conv1(x)
return x定义模型3 : 一层卷积网络,和模型2卷积核数相同,但Bias不为零
class ConvWithBias(nn.Module):
def __init__(self, ):
super(ConvWithBias, self).__init__()
self.conv1 = nn.Conv2d(3, 8, kernel_size=3, stride=1, padding=1, bias=True)
def forward(self, x):
x = self.conv1(x)
return x注意,在cnn中,如果卷积层之后接Bn层,那么一般设置bias为0,因为bias会在下一层BN归一化时减去均值消掉,徒增计算,这也是为什么我们看到很多时候卷积层设置bias,有时候又不设置。
这里模型1为conv+bn,这里对卷积层和BN层进行了初始化,特别是BN层的移动平均和方差初始化,因为这个数值默认初始化是0,是通过训练迭代出来的;
模型2为conv,并且我们用模型1的卷层权重去初始化模型2;
模型3为conv,这里我们合并模型1的卷层和BN层,然后用合并后的参数初始化模型3;
如果计算没问题的话,那么相同输入情况下,模型2输出手动计算BN后,应该和模型1输出一样,模型1的卷积和bn合并后,用于初始化模型3,模型3输出应该和模型1一样。
定义输入并且计算模型1和模型2输出
Model1 = ConvWithBn()
model1_cpkt = Model1.state_dict()
Model1.eval()
Model2 = Conv()
model2_cpkt = {k:v for k,v in model1_cpkt.items() if k in Model2.state_dict()}
Model2.load_state_dict(model2_cpkt)
Model2.eval()
input = torch.randn(1,3,64,64)
out1 = Model1(input)
out2 = Model2(input)手动计算卷积层
这里手动计算模型2的卷积过程,然后和模型2输出进行对比。

卷积原理如图
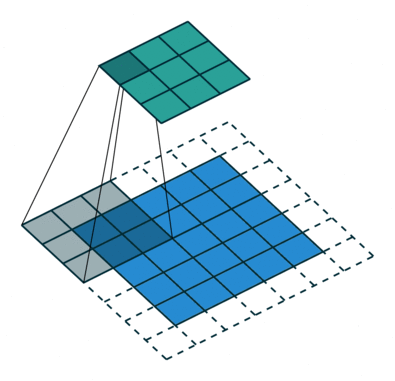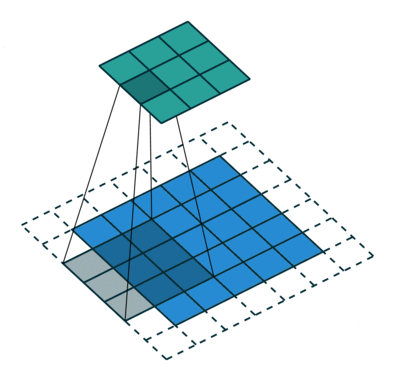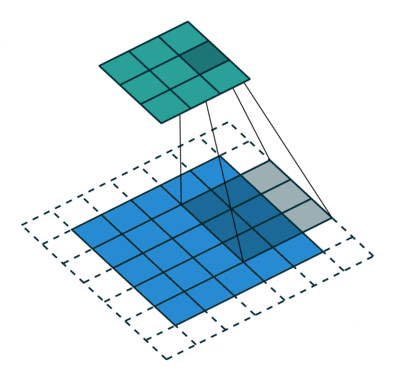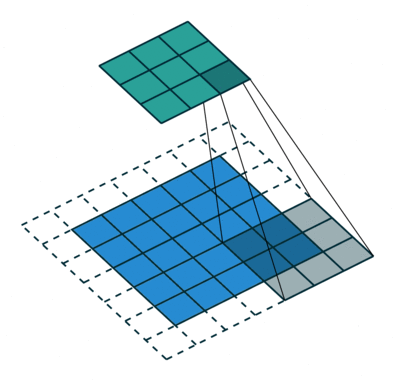
模型2有8个卷积核,每个kernel尺度为(3,3,3)对应待卷积特征图(C,H,W),因为pad=1,stride=1,卷积之后输出特征图尺度为(1,8,64,64),首先对输出进行填充:
input_pad = F.pad(input,(1,1,1,1),"constant",value=0)
print("Pad input size:",input_pad.size())输出为:

然后手动计算卷积:
convout = torch.zeros(1,8,64,64)
kerel_w = model2_cpkt['conv1.weight']
for k in range(8): # kernel
for h in range(64): # H
for w in range(64): # W
convout[0,k,h,w] = torch.sum(input_pad[0,:,h:(h+3),w:(w+3)]*kerel_w[k,:])
# 计算输出和模型2输出误差
print(torch.sum(convout - out2))输出:

ok,输出和模型2输出一样,说明计算没毛病。
手动计算BN层
BN层的具体计算如图:

BN层的输出Y与输入X之间的关系是:Y = (X - running_mean) / sqrt(running_var + eps) * gamma + beta
这里我们在模型2的输出基础上,还原BN层计算,如果没问题,那么输出应该和模型1输出一样,首先获取模型1的BN层参数:
bnw = model1_cpkt['bn1.weight']
bnb = model1_cpkt['bn1.bias']
mean = model1_cpkt['bn1.running_mean']
var = model1_cpkt['bn1.running_var']主要注意的是var是方差,不是标准差。
Pytorch计算需要注意Tensor维度,这里转为一致:
bnwexp = bnw.unsqueeze(0).unsqueeze(2).unsqueeze(3)
bnbexp = bnb.unsqueeze(0).unsqueeze(2).unsqueeze(3)
meanexp = mean.unsqueeze(0).unsqueeze(2).unsqueeze(3)
varexp = var.unsqueeze(0).unsqueeze(2).unsqueeze(3)套用公式计算:
bnout = bnwexp*((out2 - meanexp)/torch.sqrt(varexp+1e-5)) +bnbexp
torch.sum(bnout - out1)输出:

可以换看到模型2输出经过模型1的BN层后,输出和模型1输出一样,误差可以忽略。
合并Conv和BN层
在开头图中详细说明了如何合并卷积和BN层,这里把模型1的两层合并为一层,也就是模型3.
Model3 = ConvWithBias()
# 提取模型1每一层参数
conv1w = model1_cpkt['conv1.weight']
bnw = model1_cpkt['bn1.weight']
bnb = model1_cpkt['bn1.bias']
bnmean = model1_cpkt['bn1.running_mean']
bnvar = model1_cpkt['bn1.running_var']
# 维度扩展
bnwexp = bnw.unsqueeze(1).unsqueeze(2).unsqueeze(3)
bnvarexp = bnvar.unsqueeze(1).unsqueeze(2).unsqueeze(3)
# 合并卷积BN层
new_conv1w = (bnwexp*conv1w)/(torch.sqrt(bnvarexp+1e-5))
new_conv2b = (bnb - bnw*bnmean/(torch.sqrt(bnvar+1e-5)))
merge_state_dict = {}
merge_state_dict['conv1.weight'] = new_conv1w
merge_state_dict['conv1.bias'] = new_conv2b
Model3.load_state_dict(merge_state_dict)
Model3.eval()
out3 = Model3(input)
print("Bias of merged ConvBn : ",torch.sum(out3 - out1))
输出:

可以看到合并ConvBn带来的误差可以忽略。