import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("CIFAR10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 注意dataset中transform参数接收的是个对象,所以要加上括号,还有就是之后使用神经网络进行运算的时候需要的数据类型是tensor类型,所以transforms参数要加上。
dataloader = DataLoader(dataset,batch_size=64)
# 搭建一个简单的网络
class Booze(nn.Module):
# 继承nn.Module的初始化
def __init__(self):
super().__init__()
# 注意这里是创建一个全局变量所以要加上一个self 当out_channels远大于in_channels时需要对原图像进行扩充,也就是padding的值不能设为0了,需要根据公式
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=(3),stride=1,padding=0)
# 重写forward函数
def forward(self,x):
x = self.conv1(x)
return x
# 初始化网络
obj = Booze()
# 查看网络
print(obj)
'''
Booze(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
)
'''
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs,targets = data
output = obj(imgs)
# torch.Size([64, 3, 32, 32]) 64张3通道32X32的图片
print(imgs.shape)
# torch.Size([64, 6, 30, 30]) 64张6通道30X30的图片
print(output.shape)
# 使用tensorboard可视化 注意多张图片是要使用add_images而不是add_image
writer.add_images("input",imgs,step)
# 由于output是6通道数的无法显示,直接可视化会报错,所以我们需要对output进行reshape reshape的第二参数中当一个数未知时,你可以填入-1,他会自动帮你计算,为什么会未知呢?因为就是不知道填多少,填64的话肯定不行吧,然后改变通道数相当于把多余的像素给切出来了
torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step+=1
writer.close()
代码中需要注意和解释的点:
dataset = torchvision.datasets.CIFAR10("CIFAR10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
注意dataset中transform参数接收的是个对象,所以要加上括号,还有就是之后使用神经网络进行运算的时候需要的数据类型是tensor类型,所以transforms参数要加上。
# 搭建一个简单的网络
class Booze(nn.Module):
# 继承nn.Module的初始化
def __init__(self):
super().__init__()
# 注意这里是创建一个全局变量所以要加上一个self 当out_channels远大于in_channels时需要对原图像进行扩充,也就是padding的值不能设为0了,需要根据公式
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=(3),stride=1,padding=0)
# 重写forward函数
def forward(self,x):
x = self.conv1(x)
return x
在搭建神经网络继承nn.Module的初始化的时候,创建变量创建的是全局变量,所以在变量前需要加上一个self。
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=(3),stride=1,padding=0)
注意当out_channels远大于in_channels时需要对原图像进行扩充,也就是padding的值不能设为0了,需要根据公式计算,公式如下:

上图中input后面那个元组中四个元素分别代表的意义:
- 第一个元素代表batch_size
- 第二个元素代表图像通道数
- 第三个元素代表图像矩阵高度
- 第四个元素代表图像矩阵宽度
for data in dataloader:
imgs,targets = data
output = obj(imgs)
# torch.Size([64, 3, 32, 32]) 64张3通道32X32的图片
print(imgs.shape)
# torch.Size([64, 6, 30, 30]) 64张6通道30X30的图片
print(output.shape)
# 使用tensorboard可视化 注意多张图片是要使用add_images而不是add_image
writer.add_images("input",imgs,step)
torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step+=1
writer.close()
上述代码中的writer.add_images("output",output,step)运行前需要先将output降低通道数。由于output是6通道数的无法显示,直接可视化会报错,所以我们需要对output进行reshape 。
torch.reshape(output,(-1,3,30,30))reshape的第二参数中当一个数未知时,你可以填入-1,他会自动帮你计算,为什么会未知呢?因为就是不知道填多少,填64的话肯定不行吧,然后改变通道数相当于把多余的像素给切出来了。
上述代码运行完之后使用tensorboard查看效果:
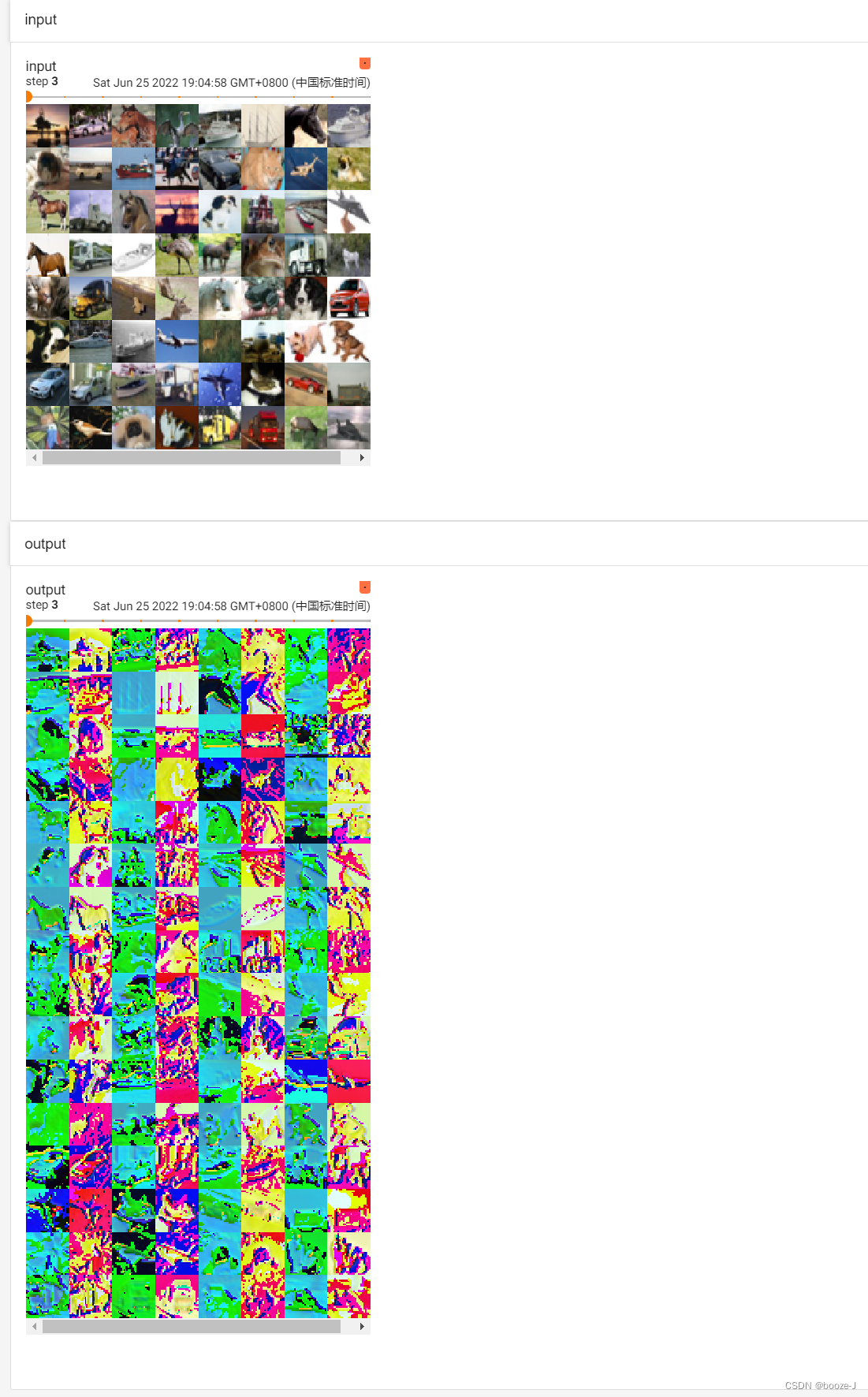
从上面的图片可以看出output每个step的图片数量多于input每个step的图片数量,原因就是由于6通道数图片reshape成3通道数图片导致的batch_size的增加。