HDFS
1,基本概念
HDFS(Hadoop Distributed File System)是Hadoop下的一个分布式文件系统,用于对数据的分布式文件存储。
2,特点
-
高容错:提供多副本机制,使得部分数据的丢失不会对数据造成影响。
-
高吞吐:HDFS 的设计初衷是高吞吐量,而不是低时延。
-
大文件支持:HDFS 更适合大数据的存储,规模应该是 GB、TB 级别。
-
简单一致模型:一次写入多次读取 (write-once-read-many) 的访问模型,不支持随机访问和写入。
-
高可靠:HDFS的机架设备可构建在廉价服务器上。
3,设计原理
HDFS 架构:
Namenode:master 角色,管理 namespace 、数据块映射信息、副本策略等,全局唯一;
DataNode:slave 角色,存储元数据,执行读写操作,可以有多个。
有时候,为了更加高可用,可以配置 Sencodary Namenode 作为热备。

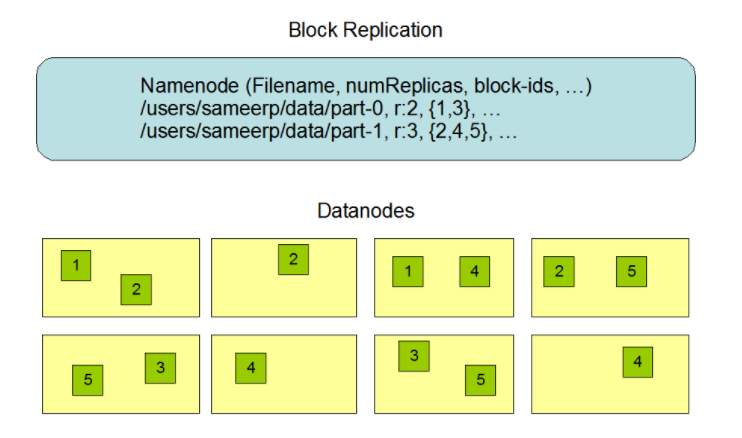
HDFS 高可用在于其副本机制:每个数据块有多个副本,且存储在不同的 DataNode,分布在不同的机架。默认情况下,块大小是128M,复制因子为3。那么数据查询,遵守就近原则,会从最近的 DataNode,最近的机架,最近的数据中心等优先获取数据。
HDFS高可靠在于:
- 心跳机制:DataNode 会定期(3s)向 NameNode 发送心跳消息,timeout 时间内没接收到消息会认为 DataNode 已经死亡,相关请求便不会再流向该节点。后续 NameNode 会以某种机制重新复制数据。
- 数据校验:由于数据是切分再拼接而成的,因此需要对数据完整性进行校验。检验值前后匹配即说明数据完整。
- 磁盘故障:对于可能的磁盘故障,需要进行数据恢复。FsImage 和 EditLog 支持部分恢复。
- 支持快照 Snapshot