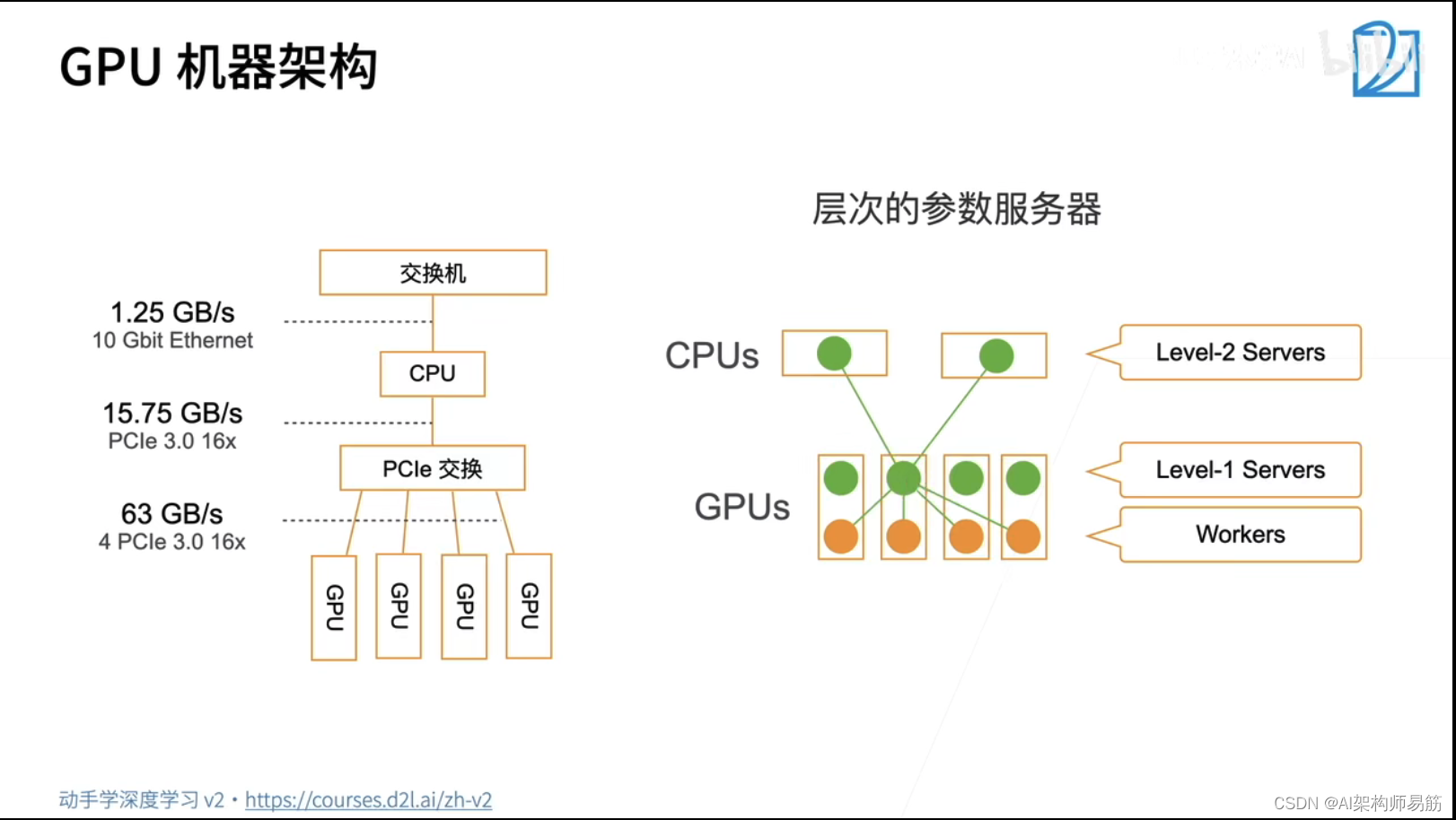
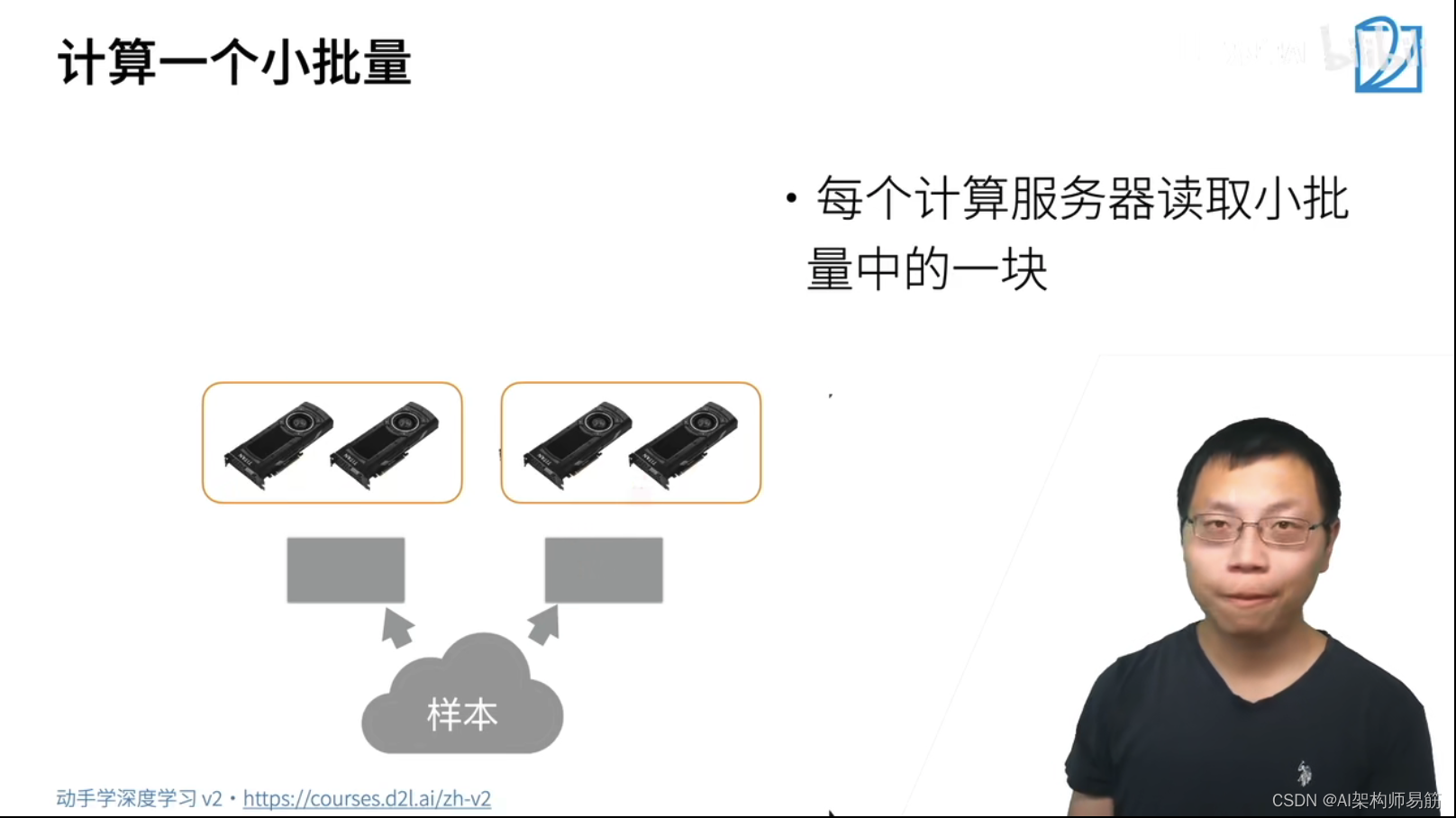
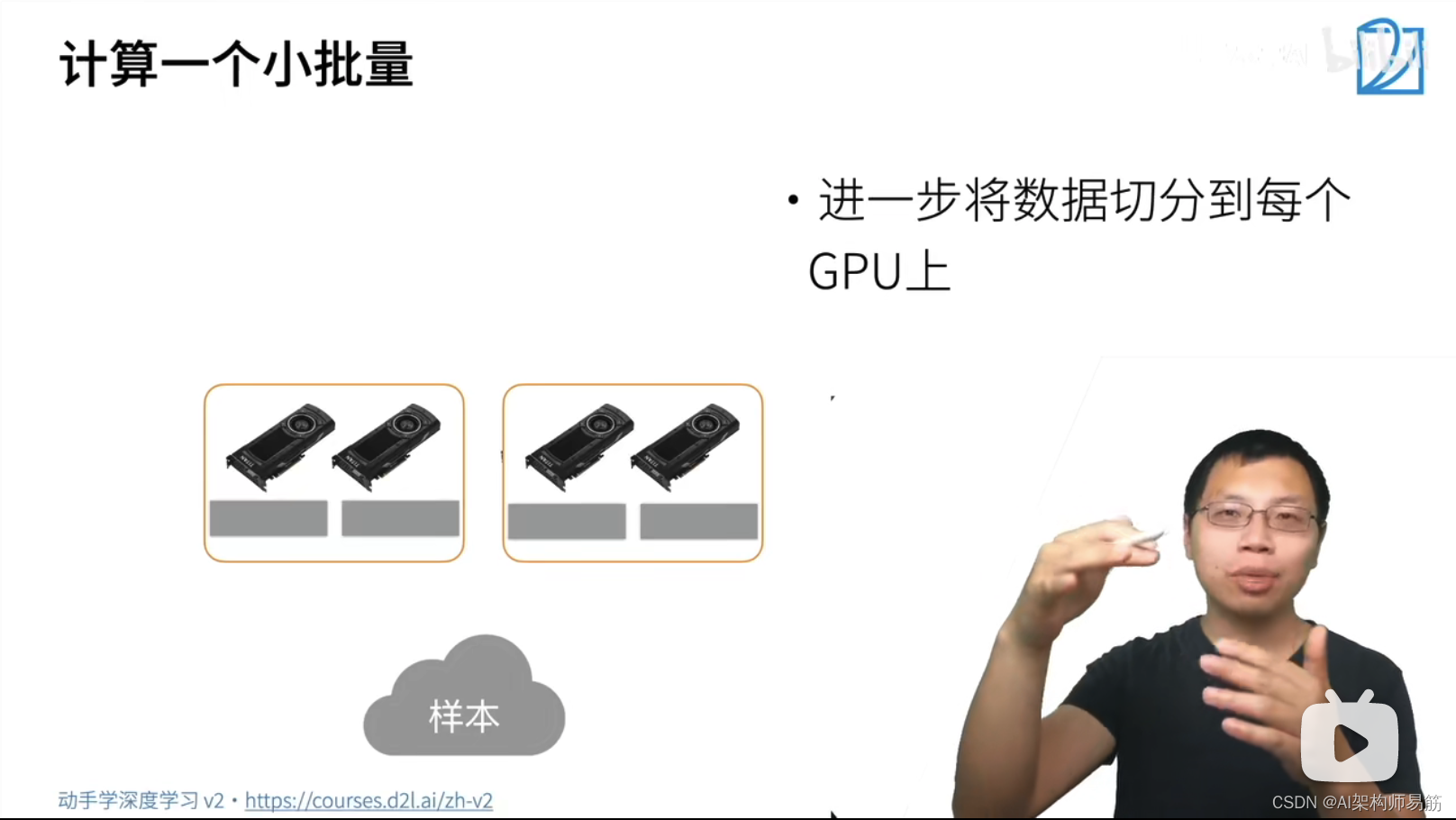
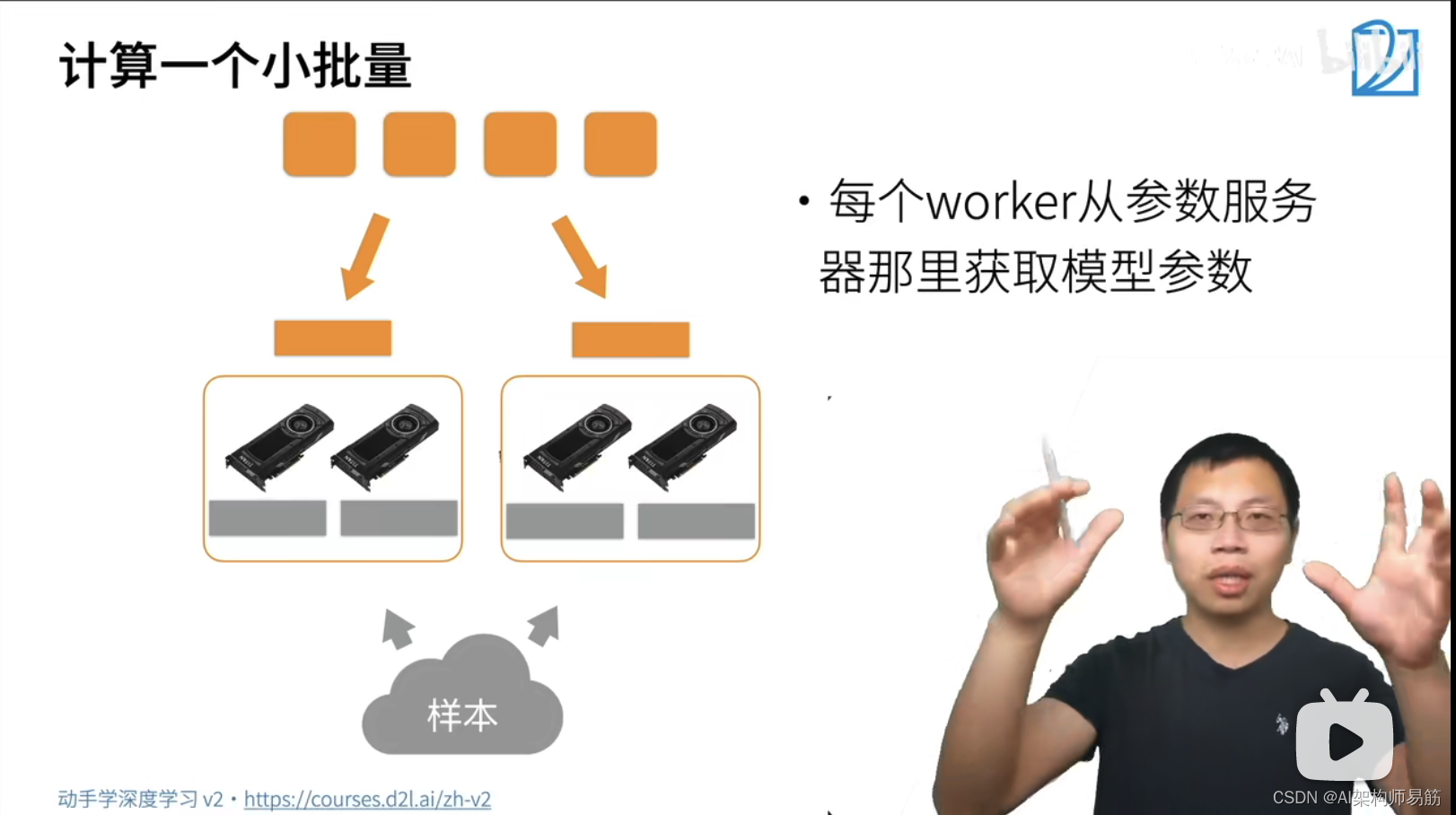
深度神经网络 分布式训练 动手学深度学习v2






猜你喜欢
转载自blog.csdn.net/zgpeace/article/details/124374276
今日推荐
周排行