1.爬取最新通知
- 要导入的包:
from urllib.request import Request
from urllib.request import urlopen
import urllib.parse
import datetime
from bs4 import BeautifulSoup
- 定义解析网址的函数
def get_new_notice(website:str):
# 直接使用 urlopen('网址') 返回 404 错误,对方网站设置有反爬虫机制
requst = Request(website)
requst.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)') # 添加请求头,模仿人使用浏览器访问页面
response = urlopen(requst)
# 一、获取该网址的源代码
html = response.read()
# 二、解析源代码
bs = BeautifulSoup(html, 'html.parser') # 爬取该网址的 HTML 源代码
# print(bs)
# 三、使用 find_all 方法找到最新通知所在的标签
nameList = bs.find_all('div', {
'id': 'line_u3_0'}) # 使用 find_all() 方法 id 选择器找到指定的 tr 标签
# print(nameList) # 爬取的的结果存放在列表中,使用时需要加下标,否则会报错
# AttributeError: ResultSet object has no attribute 'find_all'.
print('--------------------------------')
notice_time = nameList[0].span.get_text()
notice_title = nameList[0].a.get_text()
notice_link = 'http://sjxy.whpu.edu.cn/' + nameList[0].a['href'][2:]
print('通知时间:', notice_time)
print('通知标题:', notice_title)
print('链接:', notice_link)
print('-----------分割线----------------')
currdate = datetime.date.today()
currdate = str(currdate).replace('-', '/')
if notice_time == currdate:
return notice_time, notice_title, notice_link
else:
return -1
get_new_notice(网址),返回当天的通知,没有当天没有通知就返回-1
-调用函数
if __name__ == '__main__':
website = 'http://sjxy.whpu.edu.cn/index/tzgg.htm'
res = get_new_notice(website)
if res == -1:
print("No new notice")
else:
print(res)
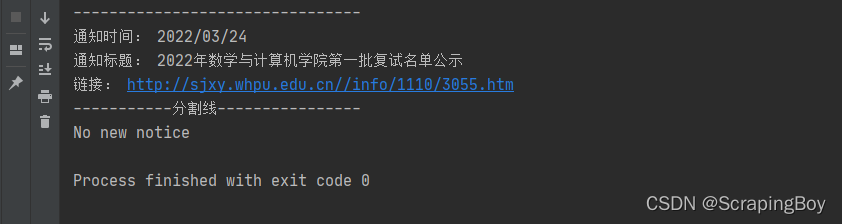
2. 结果