标题 最新 用Python 批量爬取网上美眉图片
故事是这样的:七月份给室友说,我要开始学习Python了。室友一脸懵,并问我Python是啥?确实对于我这个小城市来说Python之风还没有吹到我们这里来,以至于在我们大学都没有开设这门课!很是尴尬。要不是在网上听说Python很牛我也不会接触到。于是我便给室友说了Python的强大,可是我却遭到了室友的嘲笑。呜呜呜……。“士可杀不可辱。”我立下豪言壮志说:“三个月后我给你做出一个能批量获取网上你最爱图片的程序,给你瞅瞅!”。于是……
当然,关于这方面博客上面有很多例子,但我读了之后发现不是怎么会,不太易懂。在这里我以小白的身份写下了这篇博客,希望可以帮到更多的小白!(毕竟不能丢了咱Python的脸,哈哈哈。)
我目前自学了:Python基础知识,Python爬虫知识(仅限requests库、os库、BeautifulSoup库、re库、正则表达式)
好啦,不废话了,咱们开始!
整理思路
1、从百度找到一个拥有大量美眉图片的网址,我这里用的是 “http://www.win4000.com/meitu.html” 直接一点,进入“美女”那一栏。
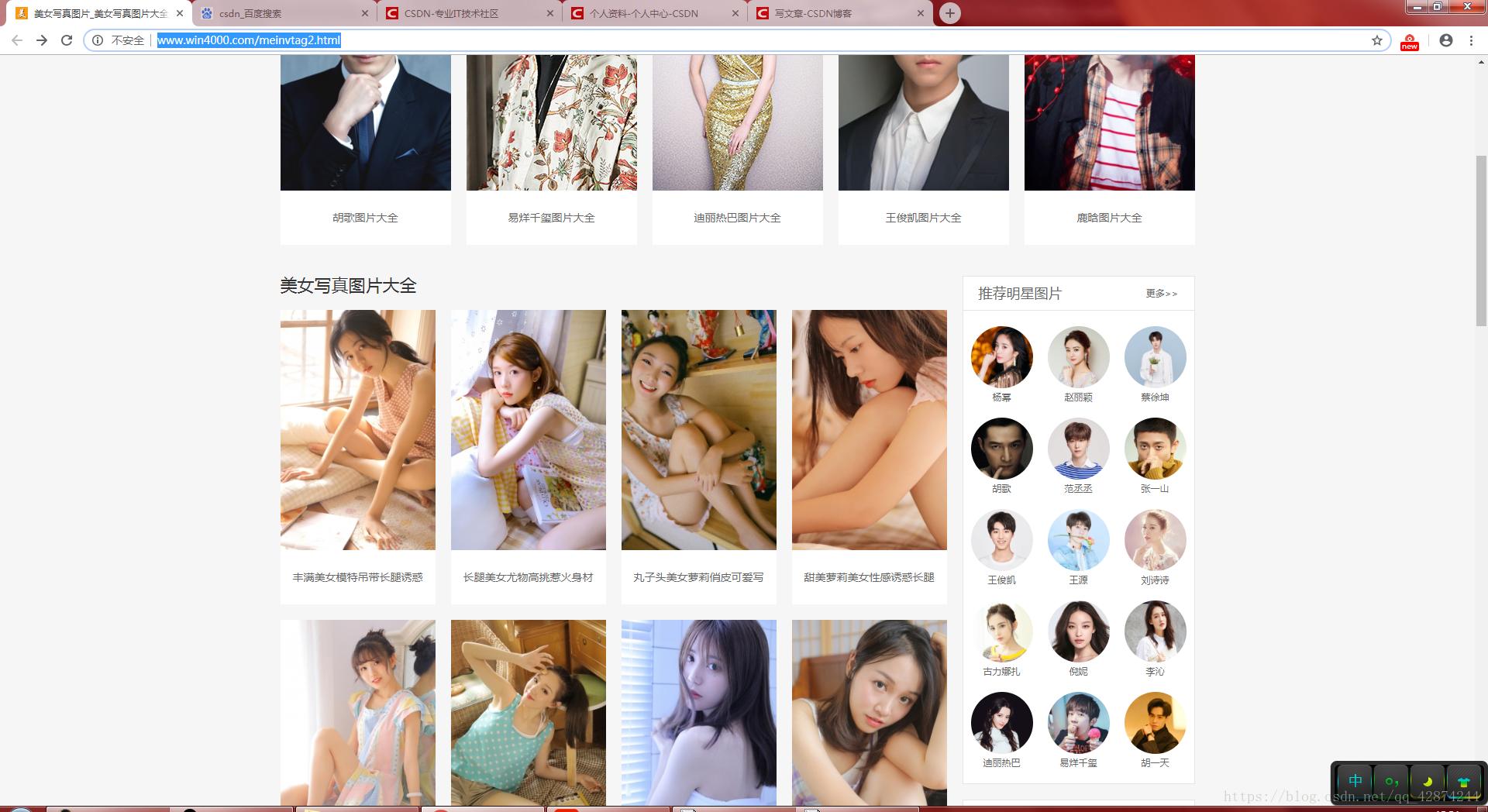
2、找到我们需要的图片中的一个。(这一个保存了,其他的也就简单了,换监事发现规律。)
3、保存图片。
大概就是这样,下面我们开始编写程序。
1.我发现点开一个图片后里面是相册一样可以翻动,有很多子照片,先查看一下子照片的规律
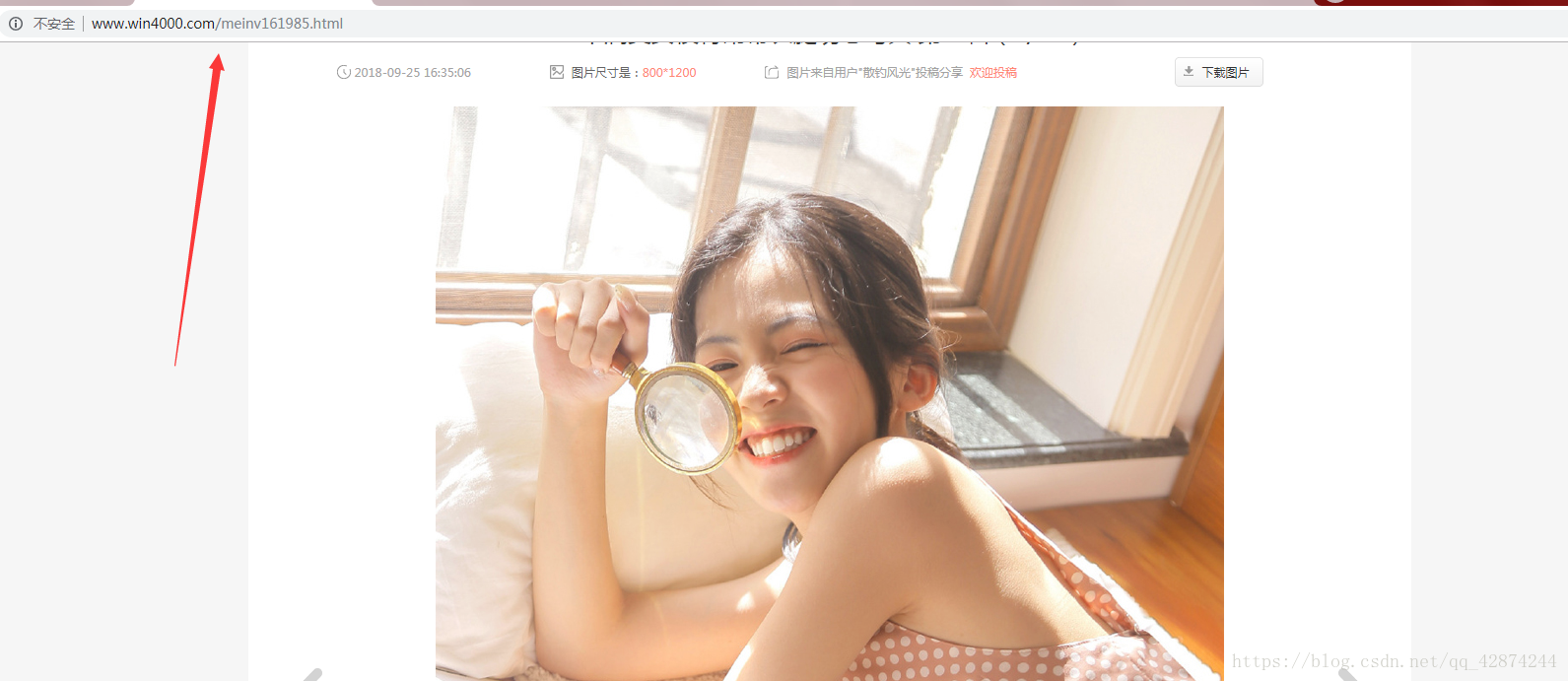
唉,居然有规律,那就舒服了,到时候用一个 for 循环就解决了。舒坦,再来!

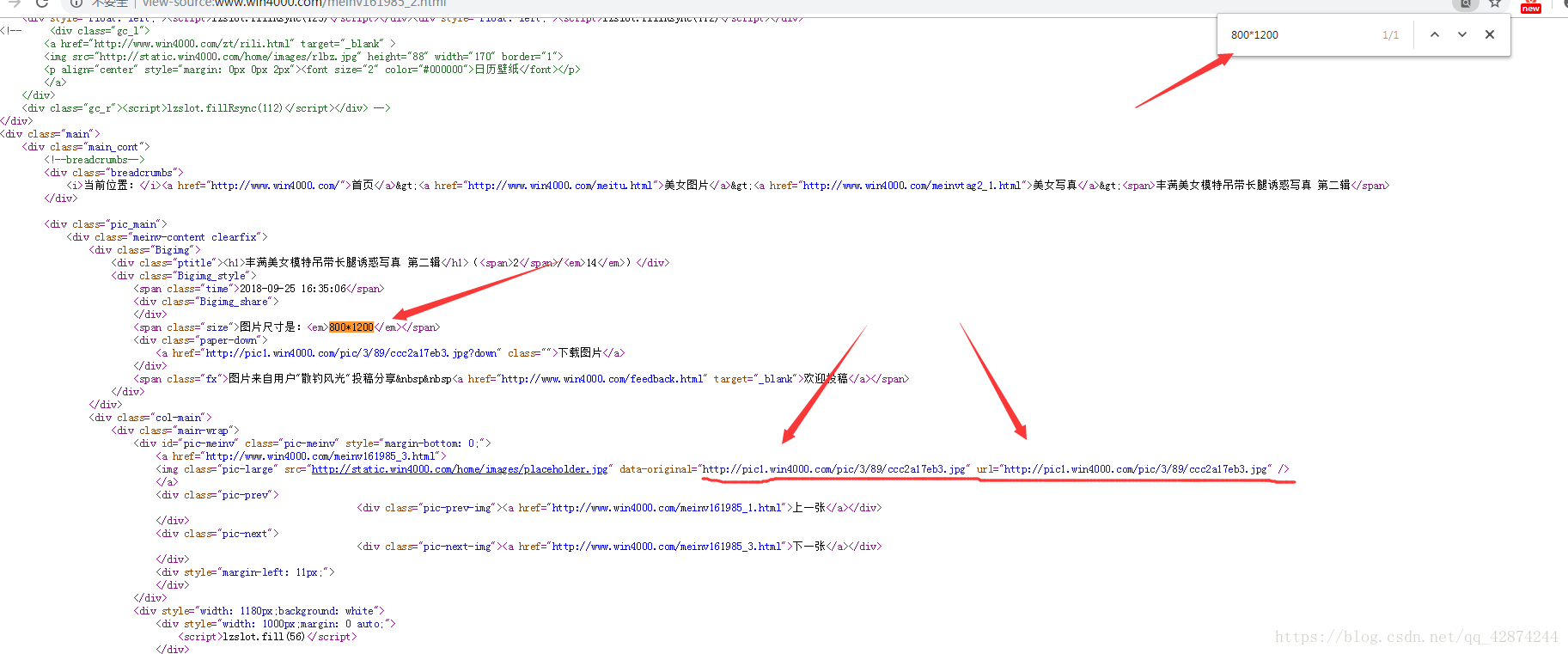
2、要知道,我现在的知识只会把有链接的图片下载下来,所以我得找到每一张图片的链接,随便点开一张图片,在网页上查看源代码。通过关键词找到图片链接。(我这里是通过图片尺寸找的)
通过尺寸为钥匙,然后周围一个链接一个链接的试探,哎呦喂,找到了!就是划线部分,结尾是 .jpg 格式,一打开还真是!舒坦,继续!
3、所以现在我们的任务也就清晰了。获取这个图片的链接就可以了。(可能是自学不到胃只到了喉咙管,一看到前面的 img 就懵圈了,不会提取这个呀,我只会 “a”的提取呀!但是我有CSDN呀,问问大神不就可以了。嘿嘿嘿。)


4、现在万事俱备,啥都不差,开始编程!
import requests
from bs4 import BeautifulSoup
import traceback
import re
import os
import time
#我是新手,先定义的主函数,这样我的头脑清晰一些!
def main():
A_url = "http://www.win4000.com/meinvtag2.html"
B_url = ""
lsM = [] #用来储存目录网址链接的呦!
lsZ = [] #用来储存每张图片连接的呦!
getMULIANJIE(lsM,A_url)
for i in lsM:
for k in range(20): #这里我大概看了一下每一个母相册后面的子照片都没有超过20个的,所以用的20!
if k == 0:
B_url = "http://www.win4000.com/mein" + i + ".html"
else:
B_url = "http://www.win4000.com/mein" + i + "_" + str(k) + ".html"
getPHOTO(B_url,lsZ)
for j in lsZ:
for m in j:
downPHOTO(m)
#解析网页
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#获取网页链接目录
def getMULIANJIE(ls,url):
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
ls.append(re.findall(r"[meinv]\d{6}",href)[0])
except:
continue
#获取照片链接
def getPHOTO(urlb,ls):
ls.clear()
html = getHTMLText(urlb)
ls.append(re.findall('url="(.*?)"',html))
#下载图片
def downPHOTO(url):
root = "D://tupian//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功!")
else:
print("文件已经存在!")
except:
print("爬取失败!")
time.sleep(0)
main()
好啦!一切大功告成,我可以去我室友哪里显摆了!
其实我的代码还可以简写很多的,可是我觉得这样的话小萌新更容易理解!
Python是真的强大,我要继续学习了。
人生苦短,我学Python!