一.该爬虫用了WebMagic爬虫框架实现
1.WebMagic开发文档:http://webmagic.io/
2.在使用之前,您需要了解正则表达式和XPath,大神请忽略
二.下面是实现代码和分析
2.1添加maven依赖
不知道maven的童鞋请参考https://my.oschina.net/huangyong/blog/194583
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!--爬虫框架-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
2.2.1.实现步骤
首先进入校花网首页,fn+f12进入开发者模式,找到class为title的a标签,下图
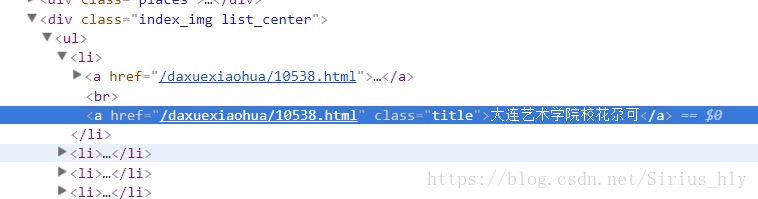
接着XPath得到所有的连接
List<String> detailURL = page.getHtml().xpath("//a[@class=\"title\"]").links().all();
2.2.2接下来,我们可以根据这个连接进入详细页,可以找到点赞数作为筛选的标准
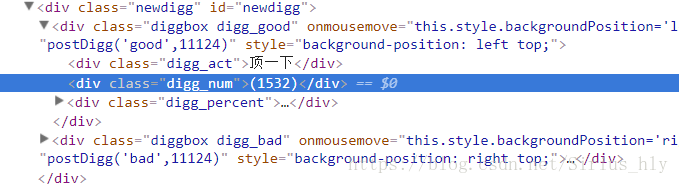
2.2.3.接下来,我们可以得到图片的连接

如下为此步的代码
String diggNum = page.getHtml().xpath("//div[@class='digg_num']/text()").regex("\\d+").toString();
//点赞数要超过300
if (Integer.parseInt(diggNum) > 200) {
//得到照片url
String photoURL = page.getHtml().xpath("//div[@class='picbox']/a").css("img", "src").toString();
System.out.println(photoURL);
//得到名字
String nickname = page.getHtml().xpath("//div[@class='title']/h2/text()").toString();
System.out.println(nickname);
2.3.爬取部分的详细代码如下:
package com.hly.webmagic.Spider;
import com.hly.webmagic.controller.DownloadImage;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.ArrayList;
import java.util.List;
/**
* @author :hly
* @date :2018/6/2
*/
public class SchoolFlower implements PageProcessor {
//页面URL的正则表达式
//.是匹配所有的字符,//.表示只匹配一个,//.?同理
private static String REGEX_PAGE_URL = "http://www\\.521609\\.com/daxuexiaohua/list\\w+.html";
//爬取的页数
public static int PAGE_SIZE = 358;
//下载张数
public static int INDEX_PHOTO =0;
//配置
@Override
public Site getSite() {
return Site.me();
}
@Override
public void process(Page page) {
List<String> targetURL = new ArrayList<String>();
for (int i = 310; i < PAGE_SIZE; i++)
//添加到目标url中
targetURL.add("http://www.521609.com/daxuexiaohua/list" + i + ".html");
//添加url到请求中
page.addTargetRequests(targetURL);
//是图片列表页面
if (page.getUrl().regex(REGEX_PAGE_URL).match()) {
//获得所有详情页的连接
//page.getHtml().xpath("//a[@class=\"title\"]").links().all();
List<String> detailURL = page.getHtml().xpath("//a[@class=\"title\"]").links().all();
System.out.println("size:"+detailURL.size());
for (String str:detailURL)
//输出所有连接
System.out.println(str);
page.addTargetRequests(detailURL);
//如果是详情页
} else {
//当然要按条件筛选啦,丑的图当然不能要
String diggNum = page.getHtml().xpath("//div[@class='digg_num']/text()").regex("\\d+").toString();
//点赞数要超过300
if (Integer.parseInt(diggNum) > 200) {
//得到照片url
String photoURL = page.getHtml().xpath("//div[@class='picbox']/a").css("img", "src").toString();
System.out.println(photoURL);
//得到名字
String nickname = page.getHtml().xpath("//div[@class='title']/h2/text()").toString();
System.out.println(nickname);
try {
// 根据图片URL 下载图片方法
/**
* String 图片URL地址
* String 图片名称
* String 保存路径
*/
DownloadImage.download( "http://www.521609.com"+photoURL, nickname + ".jpg", "F:\\schoolFlowerImage\\");
System.out.println("第"+(INDEX_PHOTO++)+"张");
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public static void main(String[]arv){
//起始URL,开启的线程数为10个
Spider.create(new SchoolFlower()).addUrl("http://www.521609.com/daxuexiaohua/list310.html").thread(10).run();
}
}
2.4接下来是下载的代码
你可以保存到电脑的文件夹
package com.hly.webmagic.download;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
/**
* @author :hly
* @date :2018/6/1
*/
public class SpiderDownload {
public static void download(String urlStr,String filename,String savePath) throws IOException {
URL url = new URL(urlStr);
//打开url连接
URLConnection connection = url.openConnection();
//请求超时时间
connection.setConnectTimeout(5000);
//输入流
InputStream in = connection.getInputStream();
//缓冲数据
byte [] bytes = new byte[1024];
//数据长度
int len;
//文件
File file = new File(savePath);
if(!file.exists())
file.mkdirs();
OutputStream out = new FileOutputStream(file.getPath()+"\\"+filename);
//先读到bytes中
while ((len=in.read(bytes))!=-1){
//再从bytes中写入文件
out.write(bytes,0,len);
}
//关闭IO
out.close();
in.close();
}
}
以上是所有的实现代码
2.5.完成爬取,点赞数超过200的图片一共有50张左右
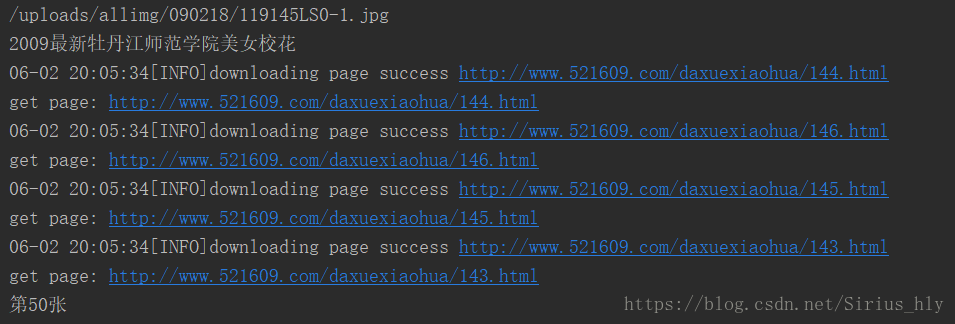
你可以在你的文件夹里面找到了