爬虫爬取蜂鸟里的高清壁纸
想要自动下载某个网站的高清壁纸,不能一个个点击下载,所以用爬虫实现自动下载。改代码只针对特定网站,不同网站需要特别分析。

一、分析网站

随便点击一张,发现可以上一页,下一页的翻页,所以可以获取改图之后,获得下一张图片地址,无线循环,下载壁纸。本次为了多功能实现,用到了beautifulsoup和re正则表达式两种搜索方式。

上图中需要的信息,从上到下:改图下载地址,图片名字,下一张图片地址。
二、获取网页
|
1
2
3
4
5
6
7
8
|
def
getHtmlurl(url):
# 获取网址
try
:
r
=
requests.get(url)
r.raise_for_status()
r.encoding
=
r.apparent_encoding
return
r.text
except
:
return
""
|
三、下载图片和获取下一个图片地址
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
def
getpic(html):
# 获取图片地址并下载,再返回下一张图片地址
soup
=
BeautifulSoup(html,
'html.parser'
)
#all_img = soup.find('div', class_='imgBig').find_all('img')
all_img
=
soup.find(
'a'
,
class_
=
'downPic'
)
img_url
=
all_img[
'href'
]
reg
=
r
'<h3 class="title overOneTxt">(.*?)</h3>'
# r'<a\sclass=".*?"\starget=".*?"\shref=".*?">(.*)</a>' # 正则表达式
reg_ques
=
re.
compile
(reg)
# 编译一下正则表达式,运行的更快
image_name
=
reg_ques.findall(html)
# 匹配正则表达式
urlNextHtml
=
soup.find(
'a'
,
class_
=
'right btn'
)
urlNext
=
urlHead
+
urlNextHtml[
'href'
]
print
(
'正在下载:'
+
img_url)
root
=
'D:/pic/'
path
=
root
+
image_name[
0
]
+
'.jpg'
try
:
# 创建或判断路径图片是否存在并下载
if
not
os.path.exists(root):
os.mkdir(root)
if
not
os.path.exists(path):
r
=
requests.get(img_url)
with
open
(path,
'wb'
) as f:
f.write(r.content)
f.close()
print
(
"图片下载成功"
)
else
:
print
(
"文件已存在"
)
except
:
print
(
"爬取失败"
)
return
urlNext
|
四、结果
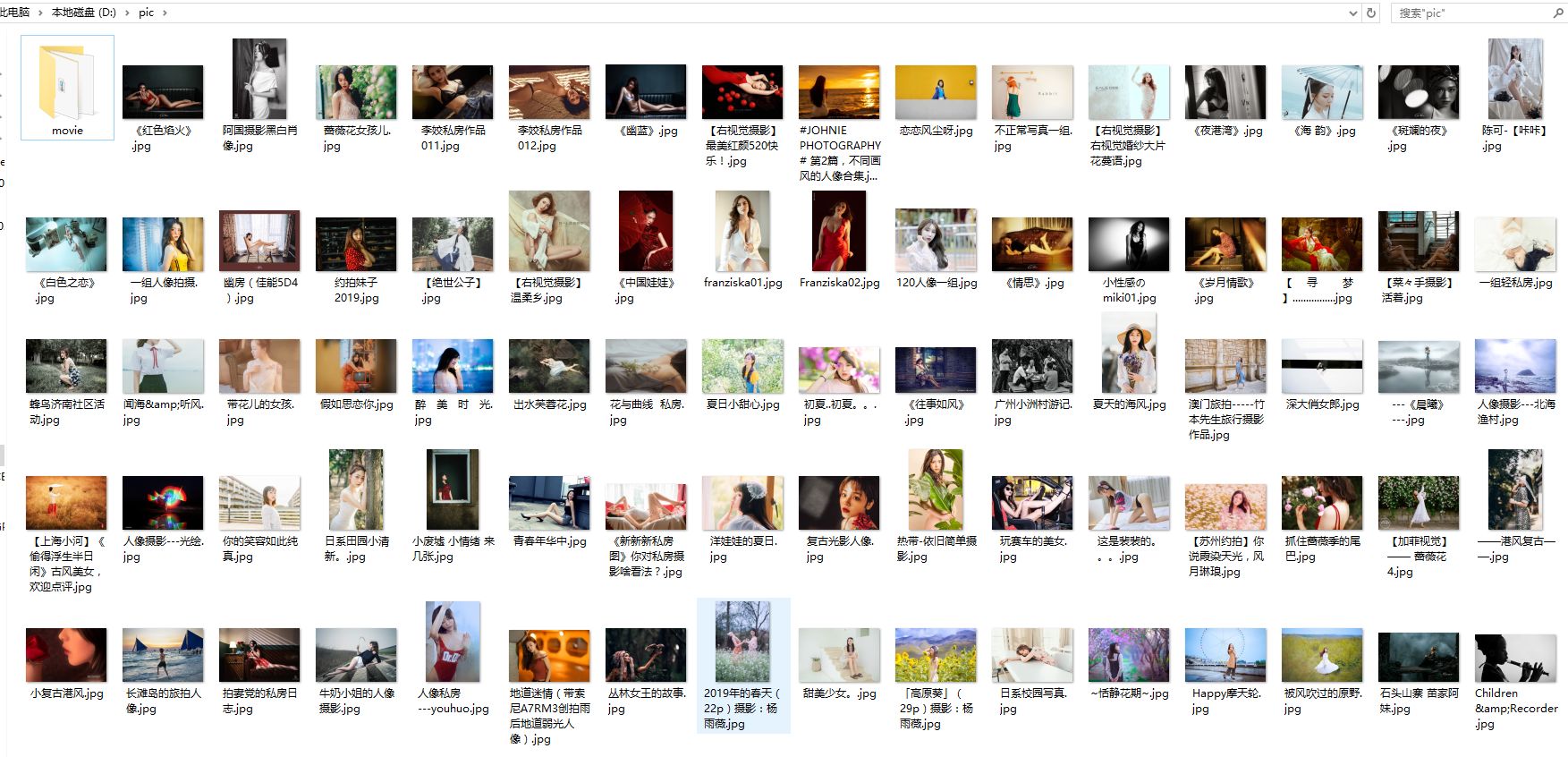
当然,我们也可以下载别的网页上图片,如下图,这就不放大了。

五、源代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
from
bs4
import
BeautifulSoup
import
requests
import
os
import
re
urlHead
=
'https://photo.fengniao.com/'
url
=
'https://photo.fengniao.com/pic_43591143.html'
def
getHtmlurl(url):
# 获取网址
try
:
r
=
requests.get(url)
r.raise_for_status()
r.encoding
=
r.apparent_encoding
return
r.text
except
:
return
""
def
getpic(html):
# 获取图片地址并下载,再返回下一张图片地址
soup
=
BeautifulSoup(html,
'html.parser'
)
#all_img = soup.find('div', class_='imgBig').find_all('img')
all_img
=
soup.find(
'a'
,
class_
=
'downPic'
)
img_url
=
all_img[
'href'
]
reg
=
r
'<h3 class="title overOneTxt">(.*?)</h3>'
# r'<a\sclass=".*?"\starget=".*?"\shref=".*?">(.*)</a>' # 正则表达式
reg_ques
=
re.
compile
(reg)
# 编译一下正则表达式,运行的更快
image_name
=
reg_ques.findall(html)
# 匹配正则表达式
urlNextHtml
=
soup.find(
'a'
,
class_
=
'right btn'
)
urlNext
=
urlHead
+
urlNextHtml[
'href'
]
print
(
'正在下载:'
+
img_url)
root
=
'D:/pic/'
path
=
root
+
image_name[
0
]
+
'.jpg'
try
:
# 创建或判断路径图片是否存在并下载
if
not
os.path.exists(root):
os.mkdir(root)
if
not
os.path.exists(path):
r
=
requests.get(img_url)
with
open
(path,
'wb'
) as f:
f.write(r.content)
f.close()
print
(
"图片下载成功"
)
else
:
print
(
"文件已存在"
)
except
:
print
(
"爬取失败"
)
return
urlNext
def
main():
html
=
(getHtmlurl(url))
print
(html)
return
getpic(html)
if
__name__
=
=
'__main__'
:
for
i
in
range
(
1
,
100
):
url
=
main()
|
下一篇应该是,爬某网站的小视频。
有问题,联系微信:GD5626633