一、准备训练数据
下载数据集
数据集结构如下: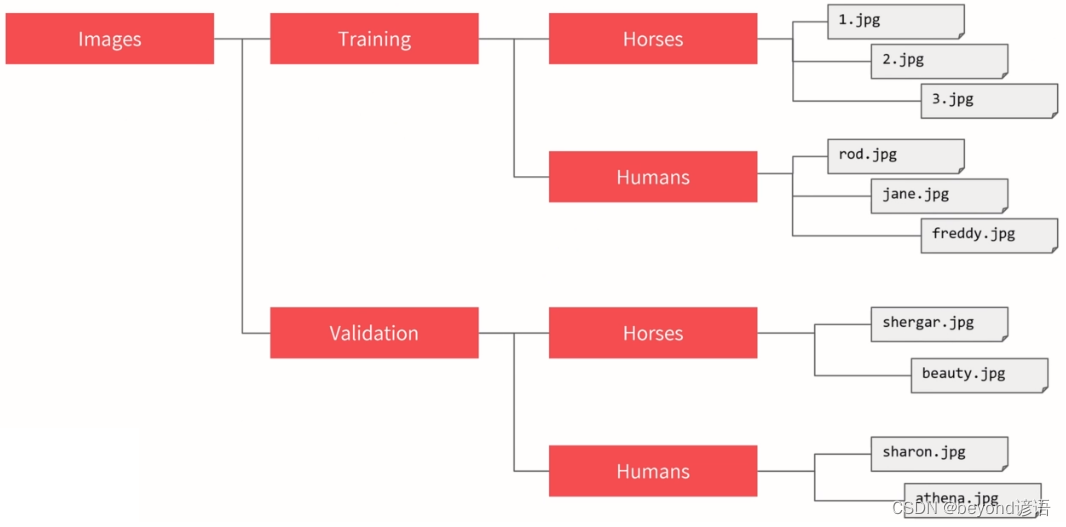
将数据集解压到自己选择的目录下就行
最后的结构效果如下: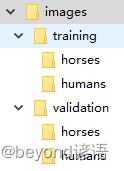
二、构建模型
ImageDataGenerator
真实数据中,往往图片尺寸大小不一,需要裁剪成一样大小,一般为正方形
数据量比较大,不能一下子全部装入内存中
经常需要进行修改参数,比如输出的尺寸,增补图像拉伸等
from tensorflow import keras
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
#创建两个数据生成器,指定scaling范围为0-1
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
#将train_datagen数据生成器指向数据集所在文件夹
train_generator = train_datagen.flow_from_directory(
r'.\images\training',#训练集所在文件夹
target_size=(300,300),#指定输出尺寸
batch_size=32,
class_mode='binary'#指定二分类
)
#Found 1027 images belonging to 2 classes.
#将validation_datagen数据生成器指向数据集所在文件夹
validation_generator = validation_datagen.flow_from_directory(
r'.\images\validation',#验证集所在文件夹
target_size=(300,300),#指定输出尺寸
batch_size=32,
class_mode='binary'#指定二分类
)
#Found 256 images belonging to 2 classes.
三、训练模型
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(64,(3,3),activation='relu',input_shape=(300,300,3)))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Conv2D(32,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.layers.Dense(1,activation='sigmoid'))
model.compile(optimizer=RMSprop(lr=0.001),loss="binary_crossentropy",metrics=['accuracy'])
model.fit(train_generator,epochs=20,validation_data = validation_generator)
"""
Epoch 1/20
8/8 [==============================] - 8s 996ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 136s 4s/step - loss: 7.4488 - acc: 0.5151 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 2/20
8/8 [==============================] - 8s 968ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 136s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 3/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 141s 4s/step - loss: 7.6964 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 4/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 143s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 5/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 145s 4s/step - loss: 7.5547 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 6/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 144s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 7/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 146s 4s/step - loss: 7.5547 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 8/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 144s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 9/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 144s 4s/step - loss: 7.6964 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 10/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 144s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 11/20
8/8 [==============================] - 8s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 143s 4s/step - loss: 7.6964 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 12/20
8/8 [==============================] - 8s 982ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 138s 4s/step - loss: 7.6964 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 13/20
8/8 [==============================] - 8s 968ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 135s 4s/step - loss: 7.6964 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 14/20
8/8 [==============================] - 8s 974ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 135s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 15/20
8/8 [==============================] - 8s 971ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 135s 4s/step - loss: 7.6964 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 16/20
8/8 [==============================] - 8s 972ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 135s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 17/20
8/8 [==============================] - 8s 983ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 135s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 18/20
8/8 [==============================] - 8s 976ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 136s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 19/20
8/8 [==============================] - 8s 969ms/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 134s 4s/step - loss: 7.8380 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
Epoch 20/20
8/8 [==============================] - 9s 1s/step - loss: 7.9712 - acc: 0.5000
33/33 [==============================] - 137s 4s/step - loss: 7.5547 - acc: 0.5131 - val_loss: 7.9712 - val_acc: 0.5000
"""
四、优化参数
import os
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
from kerastuner.tuners import Hyperband
from kerastuner.engine.hyperparameters import HyperParameters
#创建两个数据生成器,指定scaling范围为0-1
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
#将train_datagen数据生成器指向数据集所在文件夹
train_generator = train_datagen.flow_from_directory(
r'.\images\training',#训练集所在文件夹
target_size=(150,150),#指定输出尺寸
batch_size=32,
class_mode='binary'#指定二分类
)
#将validation_datagen数据生成器指向数据集所在文件夹
validation_generator = validation_datagen.flow_from_directory(
r'.\images\validation',#验证集所在文件夹
target_size=(150,150),#指定输出尺寸
batch_size=32,
class_mode='binary'#指定二分类
)
hp = HyperParameters()
def build_model(hp):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(hp.Choice('num_filters_layer0',values=[16,64],default=16),(3,3),activation='relu',input_shape=(150,150,3))),
model.add(tf.keras.layers.MaxPooling2D(2,2)),
for i in range(hp.Int("num_conv_layers",1,3)):
model.add(tf.keras.layers.Conv2D(hp.Choice(f'num_filters_layer{
i}',values=[16,64],default=16),(3,3),activation='relu')),
model.add(tf.keras.layers.MaxPooling2D(2,2)),
model.add(tf.keras.layers.Conv2D(64,(3,3),activation='relu')),
model.add(tf.keras.layers.MaxPooling2D(2,2)),
model.add(tf.keras.layers.Flatten()),
model.add(tf.keras.layers.Dense(hp.Int("hidden_units",128,512,step=32),activation='relu')),
model.add(tf.keras.layers.Dense(1,activation='sigmoid'))#是否,一个神经元就行
model.compile(optimizer=RMSprop(lr=0.001),loss="binary_crossentropy",metrics=['accuracy'])
return model
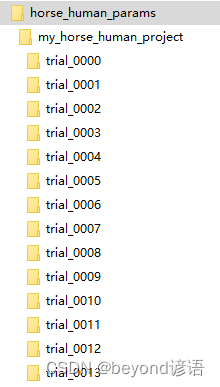
tuner = Hyperband(#将训练好的参数存放起来
build_model,
objective='val_acc',
max_epochs=15,
directory='horse_human_params',
hyperparameters=hp,
project_name='my_horse_human_project'
)
tuner.search(train_generator,epochs=10,validation_data=validation_generator)
"""
Trial 13 Complete [00h 02m 13s]
val_acc: 0.87109375
Best val_acc So Far: 0.890625
Total elapsed time: 00h 14m 22s
Search: Running Trial #14
Value |Best Value So Far |Hyperparameter
16 |64 |num_filters_layer0
5 |2 |tuner/epochs
2 |0 |tuner/initial_epoch
2 |2 |tuner/bracket
1 |0 |tuner/round
0000 |None |tuner/trial_id
"""
best_hps = tuner.get_best_hyperparameters(1)[0]#根据最优,把模型构建出来
print(best_hps.values)
"""
{'num_filters_layer0': 64, 'num_conv_layers': 2, 'hidden_units': 256, 'num_filters_layer1': 16, 'num_filters_layer2': 64, 'tuner/epochs': 2, 'tuner/initial_epoch': 0, 'tuner/bracket': 2, 'tuner/round': 0}
"""
model = tuner.hypermodel.build(best_hps)
model.summary()
"""
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 64) 1792
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 36928
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 16) 9232
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 16) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 64) 9280
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 3136) 0
_________________________________________________________________
dense (Dense) (None, 256) 803072
_________________________________________________________________
dense_1 (Dense) (None, 1) 257
=================================================================
Total params: 860,561
Trainable params: 860,561
Non-trainable params: 0
_________________________________________________________________
"""