目录
一、索引的本质
- 索引是帮助MySQL高效获取数据的排好序的数据结构。
- 索引数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree
1、简单说明
下面图,如果查询col2列值为89的数据,可以顺序遍历所有记录查询。如果基于col2列创建的索引结构是一个二叉树,如果我们有查询select * from t where t.col2 = 89; 那我们查询时按照索引结构查询节点89,索引中如果存储了数据在磁盘的地址,就可以直接获取到数据。
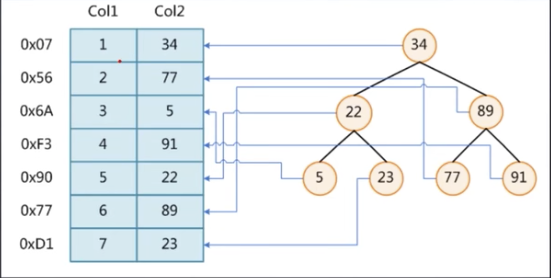
2、二叉树:
mysql不用二叉树做索引结构。
按照二叉树,对于上图的col1列创建索引,会形成下面的结构,层级很高,查询效率极低。
我们要查询006节点,需要检索6次。
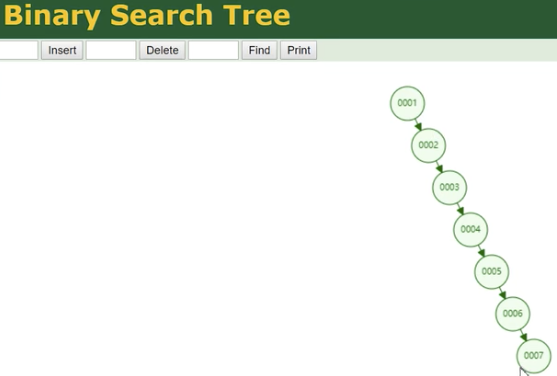
3、红黑树
mysql不用红黑树做索引结构。
红黑树的本质,是一个可以自动平衡的二叉树,全称就叫“二叉平衡树”。
我们要查询006节点,需要检索3次。
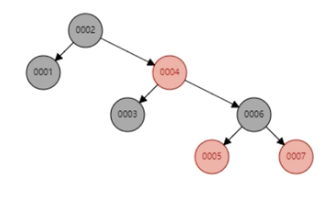
为什么不用红黑树存储索引? 因为红黑树在大数量的时候(几十万、几百万条记录)它的高度不可控,高度太高那么查询效率会非常低。比如有500万条记录,高度可能20层,查询数据正好在叶子节点,那么可能就要检索20次。
为了改进存储结构,我们可以希望每个节点上面不仅仅存一个数据,而是很多,这样树的层级就少了。下面就看看B树。
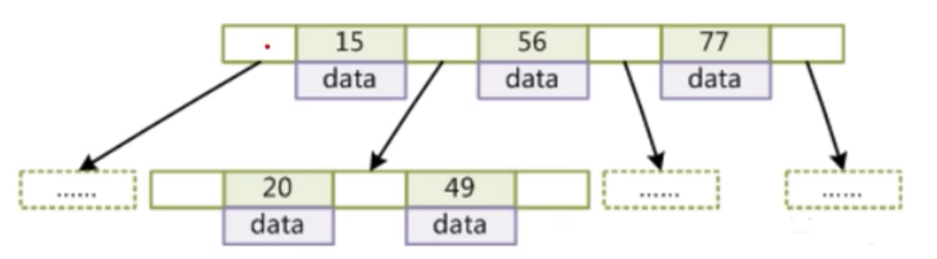
4、B-Tree
- 叶节点具有相同的深度,叶节点的指针为空。
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排序。
二、B+Tree(B-Tree变种)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引。
- 叶子节点包含所有索引字段。
- 叶子节点用指针连接(双向指针),提高区间访问的性能。

mysql关系型数据库在查询方面有三大特性,归功于B+树这种数据结构:
1)范围查询
2)前缀匹配模糊查询
3)排序和分页
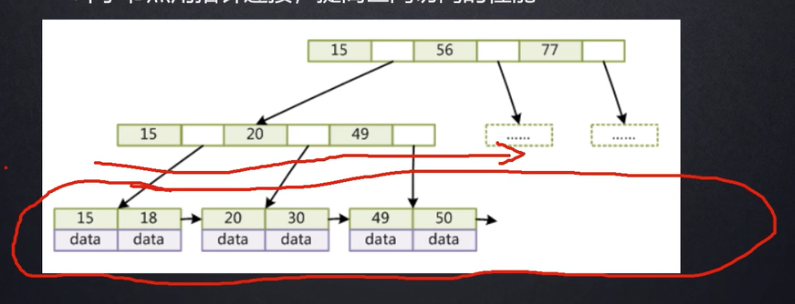
主键索引的B+树逻辑结构:
在叶子节点一层,所有记录的主键按照从小到大的顺序排列,并且形成了一个双向链表,叶子节点的每一个Key指向一条记录。
非叶子节点取的是叶子节点里面Key的最小值。这意味着所有非叶子节点的Key都是冗余的叶子节点。同一层的非叶子节点也互相串联,形成了一个双向链表。

物理结构:
索引用到的B+树只是一个物理结构,索引最终还是要存在磁盘上。下面以InnoDB引擎为例,看一下如何实现B+树的存储。
以“块”为单位对磁盘进行读写,InnoDB默认定义的块大小是16KB,通过innodb_page_size参数指定。这里所说的“块”是一个逻辑单位,而不是指磁盘扇区的物理块。块是InnoDB读写磁盘的基本单位,InnoDB每一次磁盘I/O,读取的都是16KB的整数倍的数据。无论是叶子节点,还是非叶子节点,都会装载Page里。Innodb为每个Page赋予一个全局的32位的编号,所以InnoDB的存储容量的上线是64TB(2的32次方 x 16KB)。
16KB是一个什么概念?如果用来装非叶子节点,一个Page大概可以装1000个Key,意味着B+数有1000个分叉;如果用来装叶子节点,一个Page大概可以装200记录,基于这种估算,一个三层的B+数可以存储多少数据量呢? 【16GB】

B+树模拟
在网站上进行模拟B+树,我们设置节点最大4,分别插入001,002,003节点,得到下面一个节点的树。
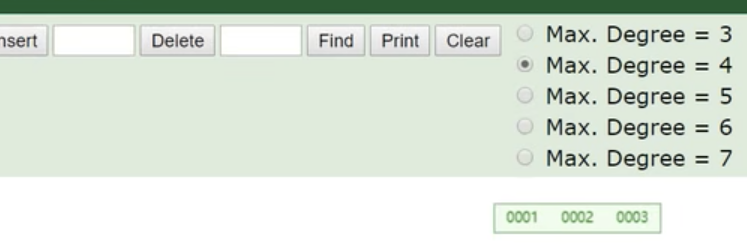
当我们插入004的时候,会发现发生了节点分裂,因为我们设置了一个节点最大不能超过4个索引。
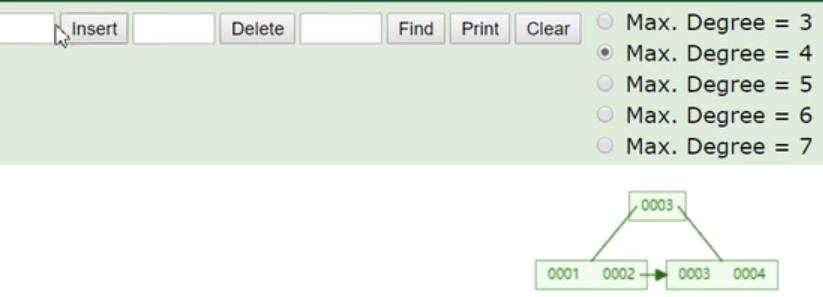
插入005,得到下面树,一个节点目前最大可以存3个索引数据。
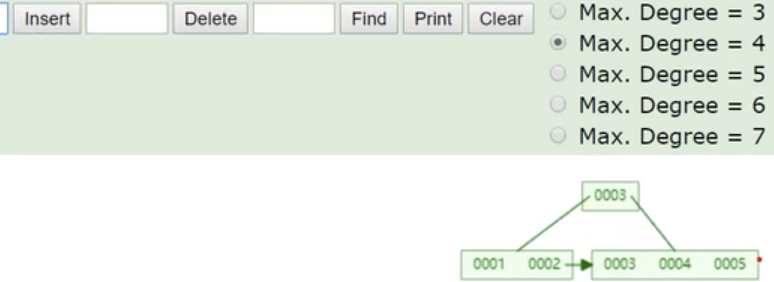
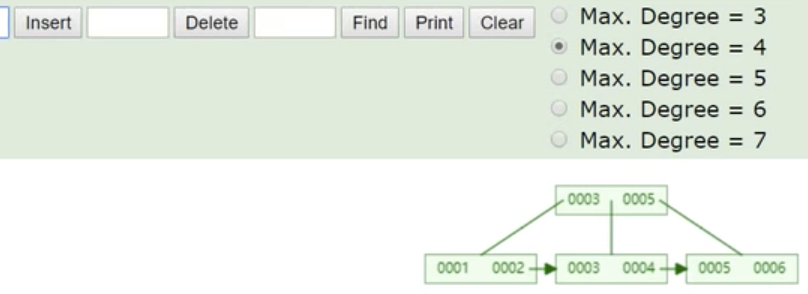
插入006, 因为节点又要超过3个数据了,又产生分裂,得到下面的树结构
mysql实际B+树配置情况
一个节点最大能存16k的数据,也就是一个节点能存储的数据量非常大,而且非叶子节点只存索引值,那么一个非叶子节点能存的索引数量就很多。节点上存储大量索引数据,树的层级会非常少,这样查询时能极大减少磁盘IO。查询数据的时候,先从根节点查询,把根节点数据都load到内存在进行数值匹配,然后在继续往下一级节点查询。
非叶子节点上面存储很多索引值,同时还有很多指针项,指向下面的节点,这个指针项(B+树上面图例中节点中白色部分)占用6个字节大小。
非叶子节点能存多少索引? 如果用主键bigint 8字节,一个指针项占6个字节,那么一个非叶子节点能存索引1170个(16✖️1024 ➗ 14)。
叶子节点能存多少索引? 叶子节点存储索引,还要存索引数据项data。 这个data可能是数据所在磁盘的地址,也能是索引所在行的其他列字段数据,这个跟存储引擎有关。我们假设data数据要占用1kb,那么一个节点16k,能存16个索引元素。
一个三层的B+树,能存多少数据? 1170✖️1170✖️16 = 2190万。也就是一张表如果有上千万条数据,索引对应B+树的高度也就3层。
索引的根节点一般会常驻内存,按照索引去查询的时候,也就1-2次io就能找到要的数据,性能非常强。
三、Hash索引
mysql索引底层用BETREE以外,还可以用HASH,如下图展示的。
如下图,如果col2列要做HASH索引。 那么当我们插入记录的时候,会对col2列的值进行hash计算,hash后的是散列值,会把散列值和记录的磁盘地址进行绑定,后面通过散列值能快速找到磁盘地址。
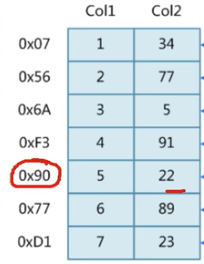
哈希查询步骤:
- 要查询col2值为22的记录,那么先对22进行哈希运算,hash(22) = m,m就是哈希散列值。
- 然后根据m能从哈希表中快读查到m对应的值,就是记录的磁盘地址。
在等值查找时,hash的查询效率还会高于B+树。但是在工作当中,我们99.9%的情况会使用B+树作为索引,因为我们需要范围查找的场景多。如下图,B+树的两个节点之间会有双向指针,范围查询非常方便。
四、索引规则
1、联合索引的底层存储结构长什么样?
- 底层是B+树。
- 按照索引字段顺序,逐个字段去比对排序。第一个字段比较大小,如果name1大于name2就不会看下面字段,如果name1等于name2,会看age1和age2的大小来排序。如果age1等于age2,那么就对比position1和postition2的大小。
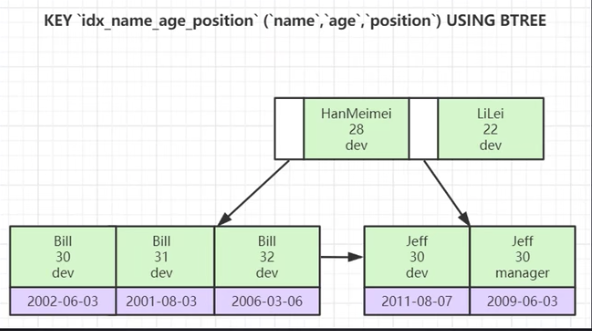
看上图,HanMeimei在Lilei的前面,name字段最先排序,按照字母顺序。
如果name都是Bill,就会再看age字段,按照大小排序。
如果name都是Jeff,age都是30,会按照position的值大小排序。
2、索引规则举例
1、全值匹配
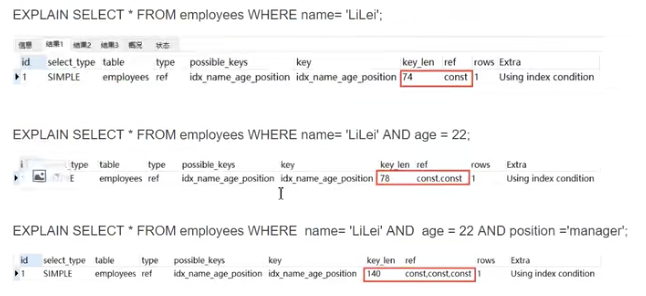
2、最左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。下图,只有第一个语句能用到(name,age,position)这个联合索引。

你要用索引,必须从第一个字段开始用,否则不会走索引。所以上面只有第一个语句走了索引。
3、不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描

4、存储引擎不能使用索引中范围条件右边的列 
5、尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select * 语句。

6、mysql在使用不等于(!= 或者<>)的时候无法使用索引会导致全表扫描

7、is null ,is not null一般情况下也无法使用索引

8、like以通配符开头,mysql索引失效会变成全表扫描操作

问题:解决like “%字符串%” 索引不被使用的方法?
a) 使用覆盖索引,查询字段必须是建立覆盖索引字段

b)如果不能使用覆盖索引则可能需要借助搜索引擎。
9、字符串不加单引号索引失效

10、少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引,详见范围查询优化。
