etcd备份存储

它主要通过snapshot去备份的,snapshot是不能很频繁去做的,因为做snapshot的时候要去锁住磁盘空间,然后做一个快照,这个时候做的任何修改都要开辟新的空间来写,也就是snapshot频繁的时候,它就快速的让你磁盘占用的空间变的非常的大。
有了wal log,那么wal log存放的是增量数据的写入日志,它们两个结合到一起就是全局。
备份方案实践
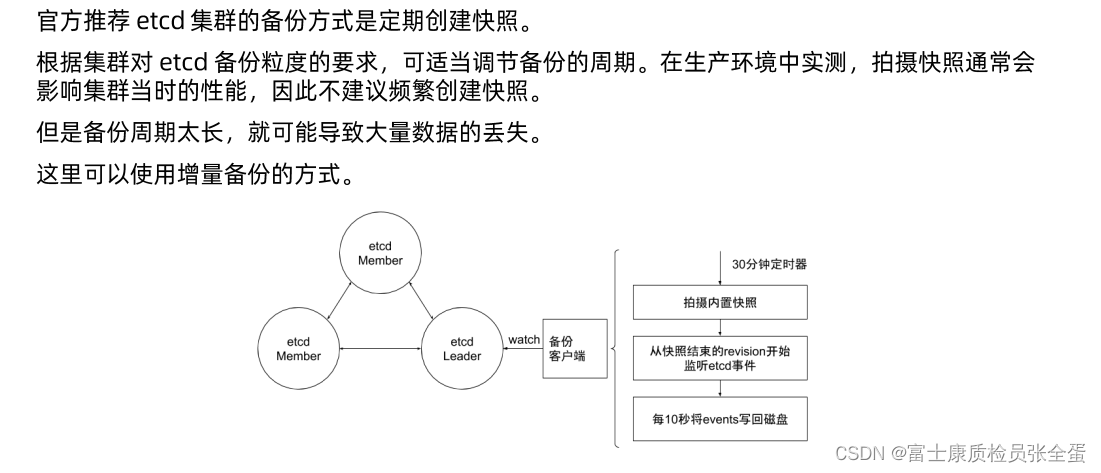
上面是社区方案里面做了增强, 比如说在每个etcd member里面,会有一个备份的客户端,是一个sidecar形式,这个sidecar会去watch etcd leader,它每30分钟去做一次snapshot,这样snapshot的频度没有那么大,30分钟的数据备份一定是不足够的,因为极端的情况下可能是29.5秒的数据全部没有了,那么怎么减少snapshot频度又可以保证数据的时效性。
在这基础之上先做snapshot,然后去监听从快照结束reversion开始监听etcd事件,也就是通过etcd的客户端去做watch,watch所有对象,所有对象修改的信息,我们都可以通过每10s一次把这些watch到的event写入到磁盘,也就是通过snapshot的方式加上event这种方式去做增强备份。
30分钟snapshot+10s一次的event,这个event是实时去监听的,每10s写入一次,这个就是增强备份方案。
增强版backup方案

当谈论etcd备份的时候,来看看现有工具是什么。那是etcdctl snapshot save,它的好处是一次性的将整个etcd dump出来,效率比较高,但是它有它的问题,比如它锁住硬盘空间导致磁盘空间暴涨,其实还有其他方法,比如watch k8s,etcd event,这样可以把集群所有的细节变动都拉下来,
对于etcd来说我们是关心所有etcd写入的event,从这个层面就可以将集群的所有变更都记录下来。
那么就可以snapshot加上一些事件驱动,去关注事件流,将这些日志存下来再回放那个的这样维护方案。
备份时间太长数据可能丢失的越多,越短导致etcd的压力大,备份的时候,时效性上来之后,它的硬盘空间磁盘碎片就多了,因为它会snapshot会锁住磁盘,那能不能做一些auto defrag,就将defrag也做成一个自动执行的命令,让它自动过段时间去清理一次磁盘。

用户在建立etcd backup对象的时候,那么backup-operator就会每隔30分钟往remote storage写一个snapshot,但是30分钟的频次是不够的,我们会导致最多30分钟的数据丢失,这是不可接受的,那我们要在原来的基础上做个增强,我们在backup的sidecar里面去写一个etcd的watch client,它去监听snapshot后面所有的时间,其实就是wal log,它其实就是监听snapshot之后的reversion所有的变更,那么每1分钟或者每10s将这种增量信息也存放到remote volume,也存放到远端存储。watch结果是什么?(比如这边更新对象,那边就会有一个put,put k=value1,value2,它就会有一个一个这样的event出来)
当去做数据的restore的时候,我先去snapshot里面拉取30分钟的频度快照,然后接下来我去remote volume里面拉取这一堆时间的增量,在原来快照的基础之上,再将这些增量replay出来,最后实现了对整个etcd的备份和恢复,即减小了snapshot的频次,又保证了数据的时效性。
安全性

数据加密
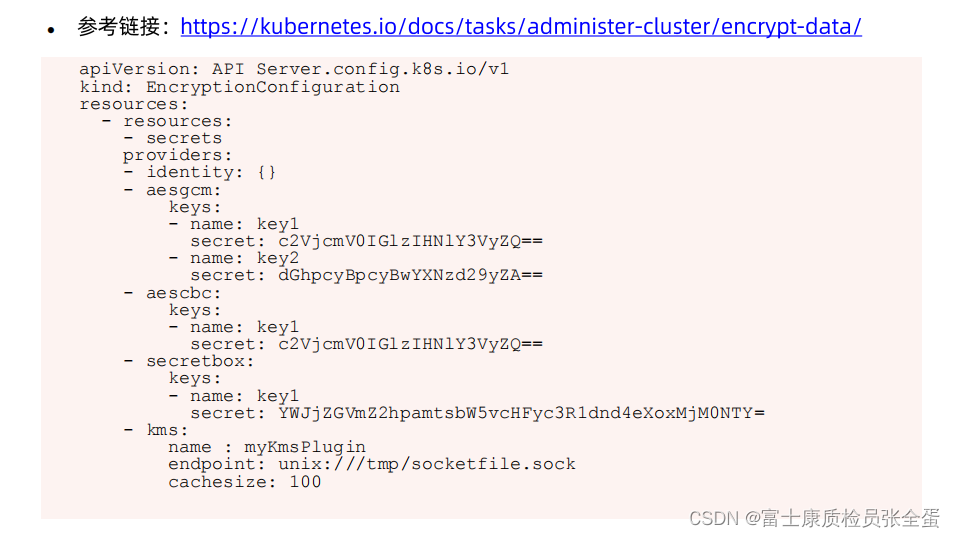
任何k8s对象在落盘的时候,本身是可以通过非对称加密的形式保存的,这样即使通过etcd这一端去做数据恢复,那么这里面的数据也是一个加密数据,你是看不到的。
有哪些对象需要加密可以通过EncryptionConfiguration里面配置,通常就是secret,因为secret往往存放着用户的密码 证书 token这些信息,它是需要安全保证的,providers这里就会提供加密算法来保存,都是非对称加密算法,这些数据一旦保存,你没有这些key是解不开的,这样就保证的数据的安全性。
查询apiserver
数据存放在etcd里面了,通过什么样的方式在apiserver这边查询呢?比如说要查询test/namespace里面所有的pod,前面api是它的前缀,v1就是group version,pod属于core group,所以group信息不需要体现,所以这里只写了一个v1。
然后查询test namespace里面所有的pod就是一个rest调用,这个rest调用最后会被转化为etcd调用。
基本上后缀都是一致的。

etcd里面有reversion的概念,任何的对象都有一个版本信息,这个reversion信息在k8s里面它表现的行为为resource version,无论是单个的对象还是list,在去get 对象的时候可以加上watch参数,不仅仅要get还要保证长连接去watch,同时可以去指定resource version,这样就是从之前某个版本来watch,最后转化为etcd里面的请求就是加上reversion信息,这样的话你正真的watch是这个对象从你指定的reversion到当前reversion的所有变化的信息,只要没有compat,那么这些历史信息就存着,就可以返回给你。

很多时候etcd里面存储的对象是非常多的,如果任何的查询都要将全量返回回来,你可想而知开销有多大,我们希望在做操作的时候返回output的量,在查询数据库的时候不能全量返回,要做分页查询。
那么我们去get某个对象的时候,kubelet其实默认加了一个限制,叫做limit,limit其实默认是查询500个,返回前500之后,返回的list里面会给你一个continue的token,k8s会按照这个token继续往下查下一部分。
所以做大数据查询的时候,基本上都是通过这种方式去做分页查询的,先返回500给你一个token,下次加上continue token,它就知道这次查询的时候是和上次连接起来的,它就会将下一批发送给你。
新的查询又会给你新的continue token,你带着新的continue token它就会给你返回1000-1500。
通过这样机制就做了分页查询的支持。
resource version到底怎么使用,我们任何的对象都有resource version,

单个对象的resource version就是这个对象最后修改的时间,