以人工智能为代表的新一代信息技术正在深刻改变着世界,改变着人类生活。人工智能技术不但能够带来便利,同时也为其带来了不确定、不稳定等诸多挑战。
2022年7月21日,由中国开源软件推进联盟主办,赛迪传媒、《软件和集成电路》杂志社联合承办,CSDN独家直播的“第十七届开源中国开源世界高峰论坛”上,LF AI & Data基金会执行董事Ibrahim Haddad带来了《加速中的开源人工智能创新与合作》演讲。
以下为Ibrahim Haddad演讲实录:
大家好,我是Linux基金会AI & Data执行董事Ibrahim Haddad,很高兴今天能和大家探讨开源人工智能和数据。
下图展示了人工智能领域开源项目不断增长的生态系统,目前有329个重点和关键项目。这些项目覆盖多个类别,比如机器学习、深度学习、笔记本环境、数据、模型等,有超过4.5亿行代码,每周大约增加100万行新代码。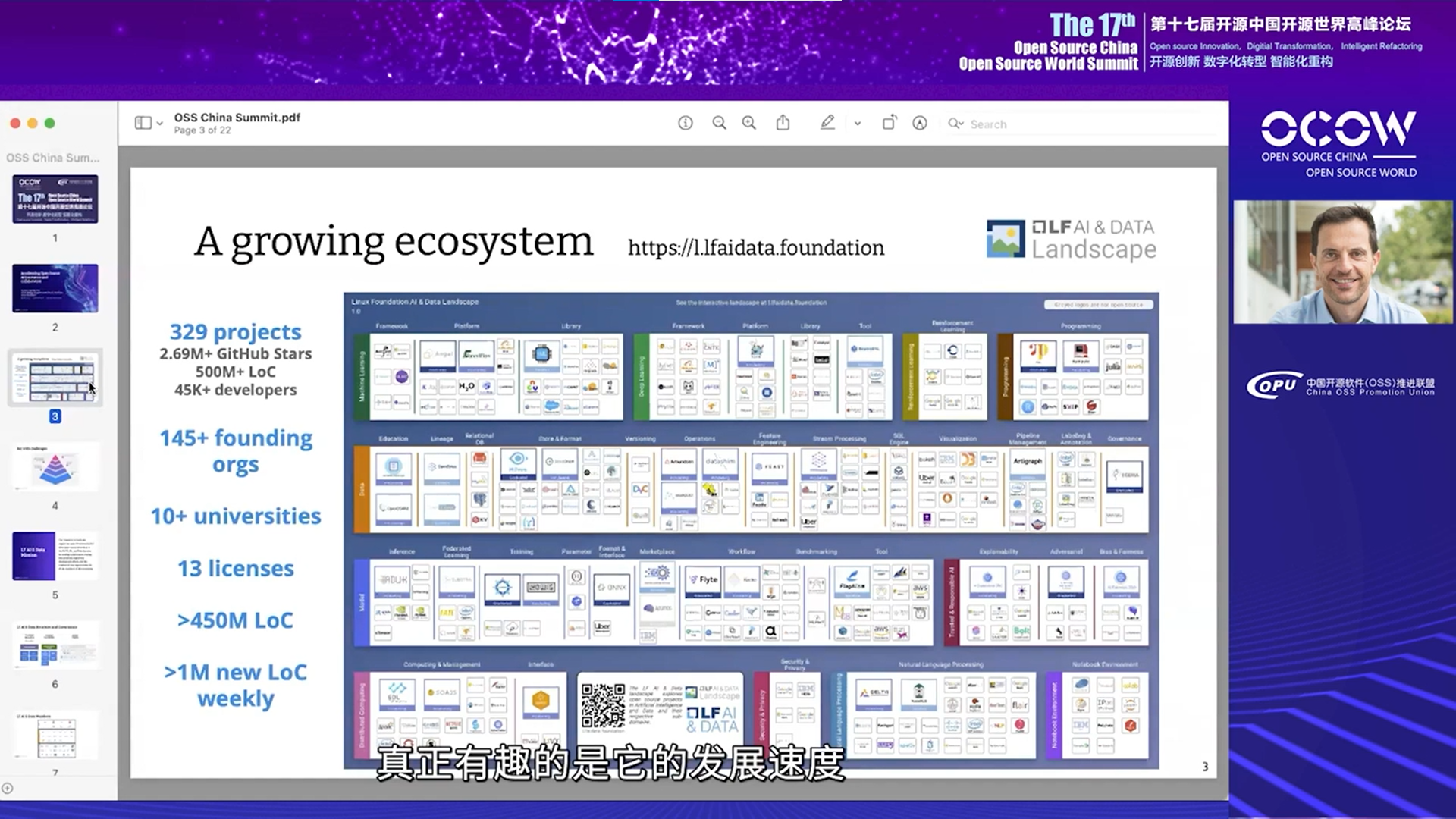
尽管生态系统的发展速度越来越快,参与者的数量也不断增多,但这个生态系统依旧存在一些挑战。这些挑战包括跨项目的碎片化、有限的集成功能、项目中的治理。很多项目都是为特定的产品需求而开发的且非常专业化。

项目和活动
尽管这些项目已经获得成功,但在管理项目资产等方面也有不同的挑战,所有挑战都促成了LF AI & Data的诞生,许多Linux基金会成员聚集在一起,并在这个新保护伞下应对以后的挑战。
LF AI & Data成立于2018年,目标是建立和支持一个开放的AI社区,并在人工智能、机器学习和深度学习的所有领域推动开源项目的创新。
作为一个基金会,我们的架构与许多其他基金会相似。如下图所示,左边是董事会,包括管理委员会、外联委员会、法律委员会、战略委员会和预算委员会。中间是技术协调机构,这就是所谓的技术咨询委员会或简称TAC,在此之下,还有许多技术委员会,例如ML OPs、DataOPs、可信AI、ML Workflow & Interop,右边是我们主持的项目。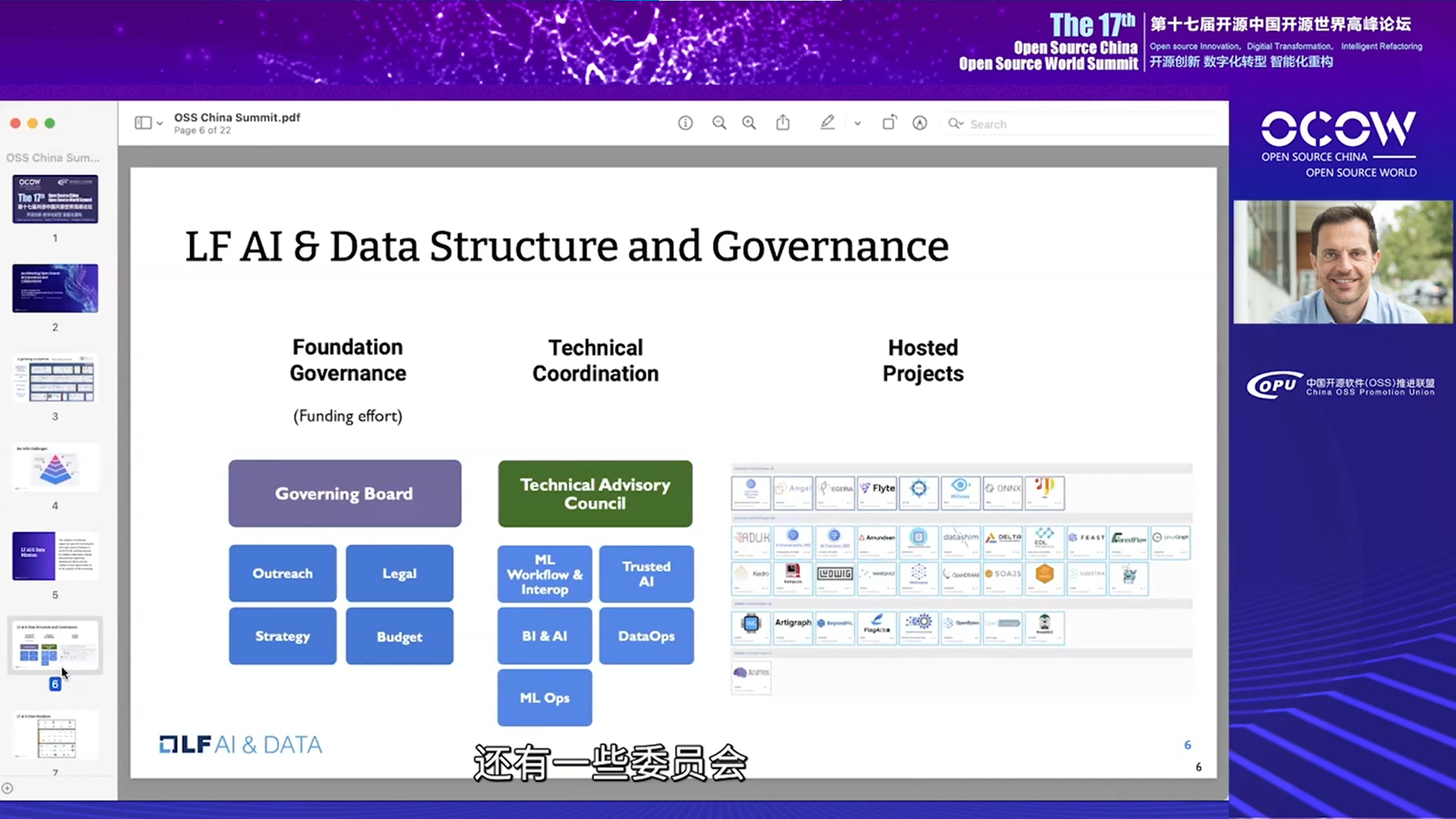
截至现在,我们有38个托管项目,每个项目都有自己的技术管理,且完全独立于基金会本身的治理。基金会的工作通过多个公司的会员身份完成,这些公司都为基金会的成功和财务健康做出了贡献。这里有三个类别的会员:高级会员、一般会员及准会员。准会员是专为学术机构和研发组织设计的。我们许多高级成员是中国的公司,例如华为、中兴、OPPO、百度和第四范式。这38个项目分为四个不同的类别:档案项目、沙盒项目、孵化项目、毕业项目。我们几乎每个月都在增加项目。截至今天,我们主持了超过11%的生态系统重点项目,这些项目的开放治理以及资产管理,提供IT基础设施、市场营销、法律和活动等服务。
这些项目来自中国、欧洲和美国以及韩国、印度等亚洲其他国家和地区。他们依靠LF的专业知识和技能以及员工帮助发展这些项目,并使它们成为各自类别的实际标准。
在成员方和项目方面,我们的势头非常强劲。每个月都在增加一个新项目,我们为项目提供了大规模的基础设施,管理项目的所有合法资产、商标、出口管制备案和合规扫描。一个重要的里程碑是在6月初我们拥有了16000名活跃开发者,我们的营销传播服务支持与项目有关的公告,给会员项目毕业和合作机会。另外我们也有一些活动来支持项目和成员。
其中一些活动是社区活动,还有一些是大型会议和分会。例如,我们每年举办的LF AI & Data峰会,多次作为北美、欧洲和中国开源峰会的一部分。KubeCon也有人工智能分会,我们还有一个与CNCF合并的特别活动叫做Kubernetes +AI。除了活动,那16000名贡献者也是一个重要的里程碑。下图是一份全面的服务清单,我们有专门的工作人员来支持这些项目,并支持采用所主持的开源LF AI项目。作为伞型基金会的一部分,我们有一个支持活动管理的团队,有一个以开发者为中心的运营。
我们有专门的工作人员进行项目管理,就Commits的增长而言,下图是过去三年的情况,我们所有项目的投入都在持续增长。同样,贡献者数量和力量都在不断增加。贡献者实力指的是随着时间的推移,贡献者的贡献不断增加。截至目前,有543个机构正在参与我们的项目。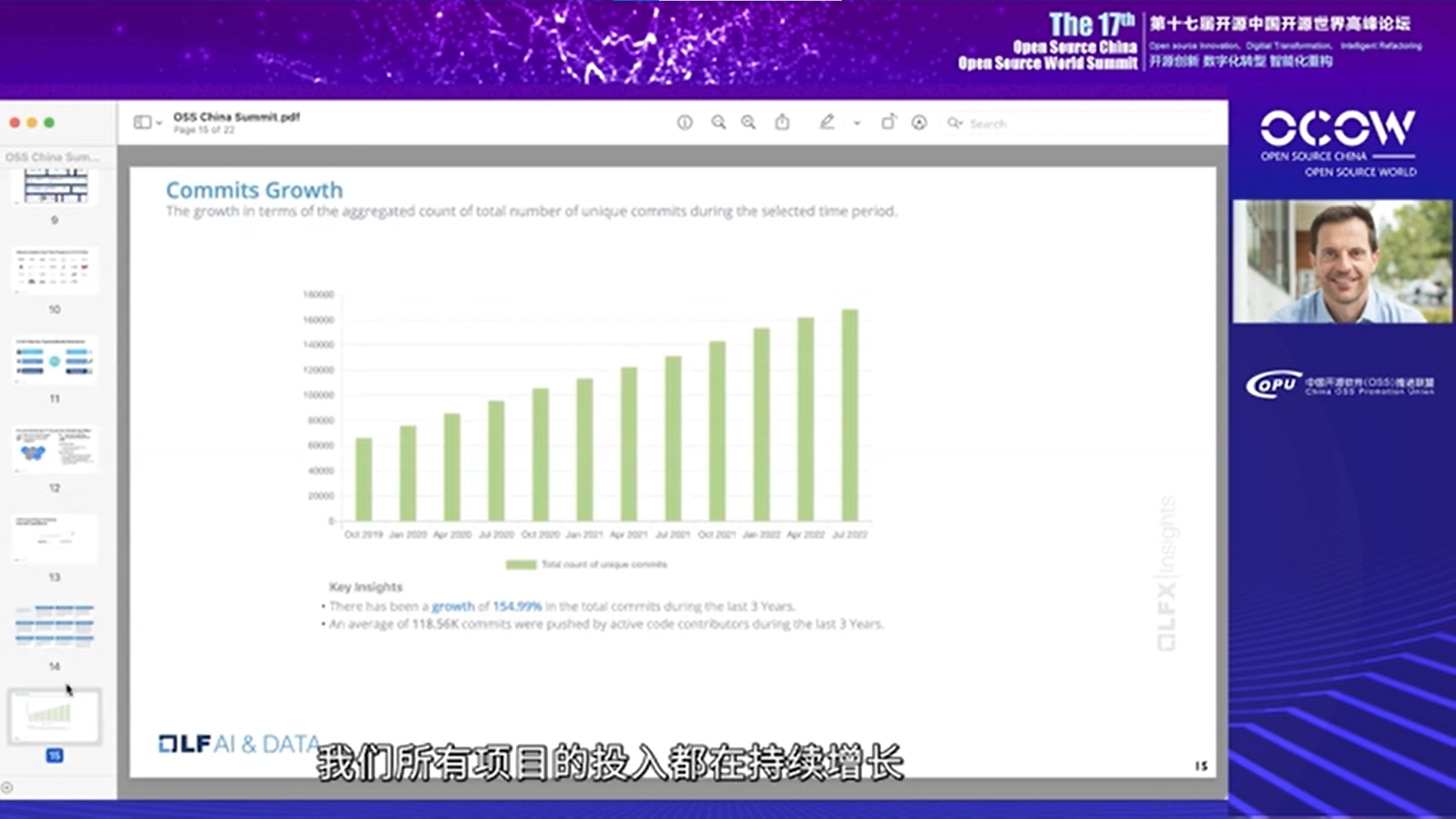

挑战和趋势
下面来看挑战和趋势。
我们看到的一些全球趋势与开源人才需求的增加有关,开源项目办公室的增加已经成为全球趋势,横跨所有行业,对安全的重视程度更高。
基金会在这个阶段主要通过开源安全基金会(SSF)的努力不断累积,在该领域的产品和服务中融合人工智能和机器学习是一种趋势。特别是LF AI & Data在主持项目、协作和集成上做了大量的工作。考虑到数据的重要性,数据管理、治理和传承在全球都很重要,LF AI & Data将主持这些不同类别的关键项目。
在人工智能和数据面临的具体挑战方面,招聘人才是一个持续的挑战,需要额外的计算能力。建立信任也是一个挑战,尤其是在模型方面,这是一个在不同类别、不同技术领域,并在不同行业部门进行不同的部署,解决偏见问题是人工智能伦理的另一个方面,这是LF AI & Data正在努力解决的问题。数据方面也存在不同的挑战,特别是在数据隐私、安全和治理方面,随着国家政策的不同以及已经实施的法律,这一切变得更加复杂。
还有就是达到人类智力水平的挑战,很多人都在努力推动人工智能机器学习,向人类智能水平发展。这些不同的挑战同时也带来了机遇,我们有机会致力于创造可信和负责任的人工智能并获得价值和见解。
现在有大量的数据表明,在人工智能和边缘计算方面也存在机会,而这样的机会是由更接近边缘的自由时间决策的要求所驱动的。比如智能汽车。
另外在人工智能芯片设计的专业化方面,创业公司和在这一领域的研究都有很多机会。当然,所有公司都希望自己的算法更快、更便宜、更智能。在改进现有算法的空间上人们付出了很多努力,包括跳过与Suspect竞争的方法,以及保护隐私的新方法,在人工智能的不同类别中真正被采用的联合学习。
今天讲了在LF AI & Data在做的事情,以及面临的趋势和挑战。欢迎成为LF AI & Data的成员,和我们一起孵化你们的项目。谢谢大家。
点击2022(第十七届)开源中国开源世界高峰论坛-CSDN直播,查看更多精彩演讲内容!