今天我们来学习下经典网络VGG,并且模拟实现VGG16,且用来训练cifar10数据集。
一:VGG简单学习
先来看下图的总体介绍,有下面几种分类,A,A-LRN,B,C,D,E。其中最常用的是后两种,D和E的网络配置一般也叫做VGG16和VGG19。
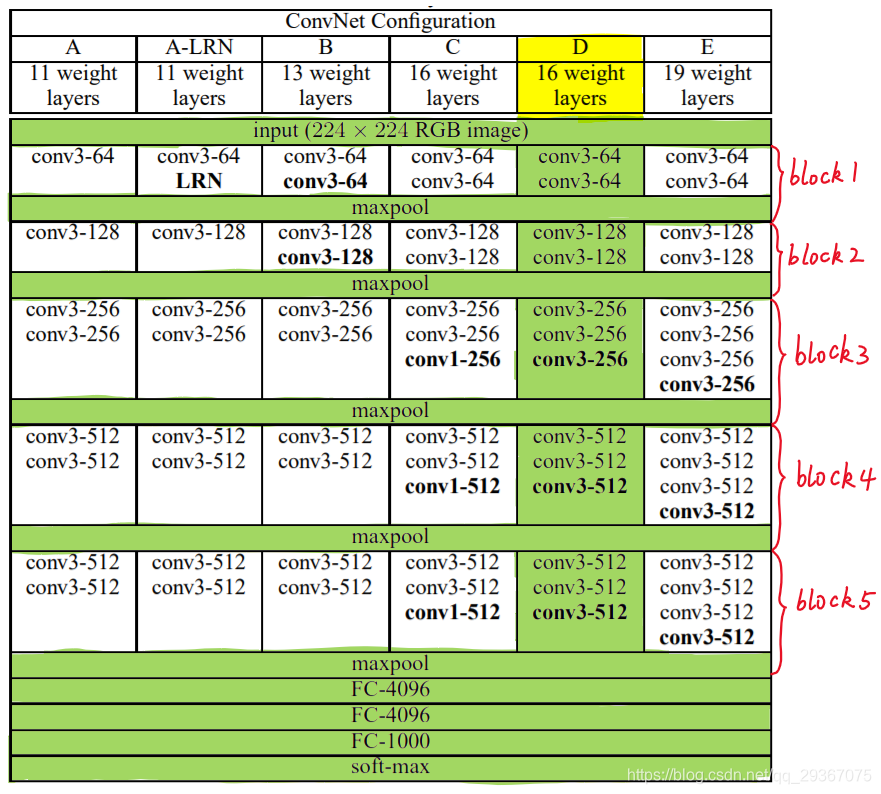
VGG16有13个卷积层加上3个全连接层,VGG19则有16个卷积层加上3个全连接层。
VGG16和VGG19度包含了5个池化层。
整体网络可以分成6个部分,前面5个是卷积层(Conv-XXX表示)(若干卷积ReLU和一个maxpooling组成),也就是用来做特征提取。
后面一个是是分类层,是由3个全连接层(FC-XXX表示)加上softmax组成的。
Conv3-128的含义就是,卷积核的大小是3x3,128个输出通道。
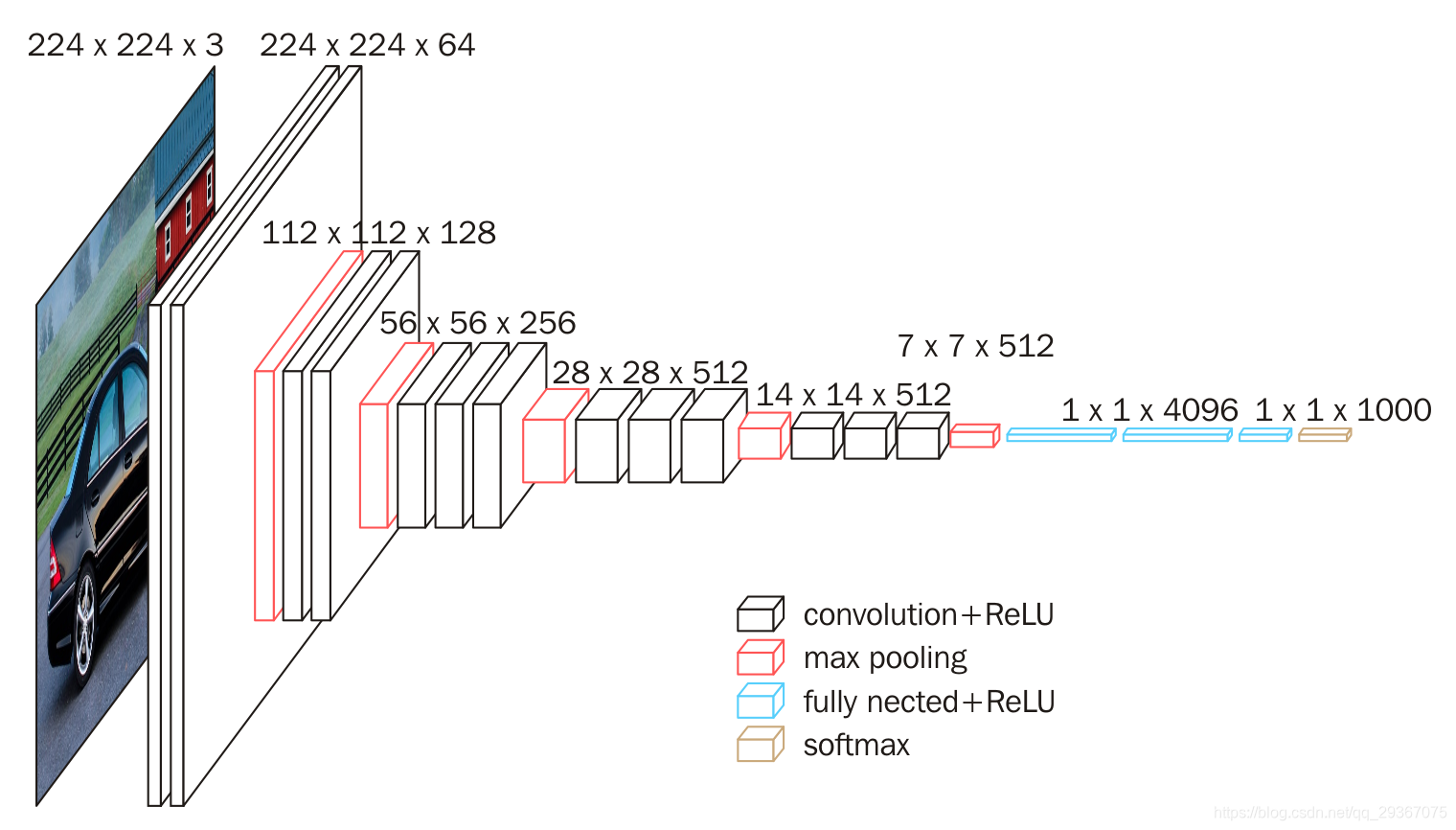
如下图VGG16 的结构所示:
就比较清晰了。
什么?还不清楚?那来,我们看一看原始的VGG16的例子,把他的结构打印出来不就楚了么。
import torch
import torchvision
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
net = torchvision.models.vgg16(pretrained=True) #从预训练模型加载VGG16网络参数
print(net)
输出如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
这下总清楚了吧?这里所有的网络结构都打印了出来呢。
接下来我在代码中也会按照这个结构这么写。
二:cifar10数据集
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( a叩lane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练圄片和 10000 张测试图片。 CIFAR-10 的图片样例如图所示。
下面这幅图就是列举了10各类,每一类展示了随机的10张图片:

与 MNIST 数据集中目比, CIFAR-10 具有以下不同点:
1:CIFAR-10 是 3 通道的彩色 RGB 图像,而 MNIST 是灰度图像。
2: CIFAR-10 的图片尺寸为 32×32, 而 MNIST 的图片尺寸为 28×28,比 MNIST 稍大。
3:相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、 特征都不尽相同,这为识别带来很大困难。 直接的线性模型如 Softmax 在 CIFAR-10 上表现得很差。
三:完整训练代码
这里我是自己按照VGG16 的网络定义,写了其前5层的卷积的网络结构,并且为了加速收敛,将model.vgg16()的参数初始化了过来。当然了,这里也可以不用自己模仿写出前5层的卷积的网络结构,可以直接利用model.vgg16()的模型,只不过需要把最后的FC层全部替换掉罢了。但是这里为了学习,就自己写一个一模一样的。
至于全连接层则是自定义的,因为原始的model.vgg16()输入图片是224x224大小的,而我们测试CIFAR-10是32x32大小的,尺寸小了7x7倍,因此我们需要自行做出一些改变。
这种拿现成的模型结构和参数来初始化训练的思路也是迁移学习的一种思想。
from torch import nn
import torch
import torch.optim as optim
from torchvision import datasets, transforms
import torchvision
"""
第一步:加载 CIFAR10 数据,大小是32*32*10
"""
batch_size = 16
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
"""
第二步:定义VGG16 模型,全部的卷积层,也就是特征抽取层和models.vgg16(pretrained=True)是一样的
但是FC层根据自己的特点自己定义了。
"""
class VGGTest(nn.Module):
def __init__(self, pretrained=True, numClasses=10):
super(VGGTest, self).__init__()
# 100% 还原特征提取层,也就是5层共13个卷积层
# conv1 1/2
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.relu1_2 = nn.ReLU(inplace=True)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv2 1/4
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.relu2_2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv3 1/8
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.relu3_2 = nn.ReLU(inplace=True)
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.relu3_3 = nn.ReLU(inplace=True)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv4 1/16
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu4_2 = nn.ReLU(inplace=True)
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu4_3 = nn.ReLU(inplace=True)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv5 1/32
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_2 = nn.ReLU(inplace=True)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_3 = nn.ReLU(inplace=True)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
# load pretrained params from torchvision.models.vgg16(pretrained=True)
# 从原始的 models.vgg16(pretrained=True) 中预设值参数值。
if pretrained:
pretrained_model = torchvision.models.vgg16(pretrained=pretrained) # 从预训练模型加载VGG16网络参数
pretrained_params = pretrained_model.state_dict()
keys = list(pretrained_params.keys())
new_dict = {
}
for index, key in enumerate(self.state_dict().keys()):
new_dict[key] = pretrained_params[keys[index]]
self.load_state_dict(new_dict)
# 但是至于后面的全连接层,根据实际场景,就得自行定义自己的FC层了。
self.classifier = nn.Sequential( # 定义自己的分类层
# 原始模型vgg16输入image大小是224 x 224
# 我们测试的自己模仿写的模型输入image大小是32 x 32
# 大小是小了 7 x 7倍
nn.Linear(in_features=512 * 1 * 1, out_features=256), # 自定义网络输入后的大小。
# nn.Linear(in_features=512 * 7 * 7, out_features=256), # 原始vgg16的大小是 512 * 7 * 7 ,由VGG16网络决定的,第二个参数为神经元个数可以微调
nn.ReLU(True),
nn.Dropout(),
nn.Linear(in_features=256, out_features=256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(in_features=256, out_features=numClasses),
)
def forward(self, x): # output: 32 * 32 * 3
x = self.relu1_1(self.conv1_1(x)) # output: 32 * 32 * 64
x = self.relu1_2(self.conv1_2(x)) # output: 32 * 32 * 64
x = self.pool1(x) # output: 16 * 16 * 64
x = self.relu2_1(self.conv2_1(x))
x = self.relu2_2(self.conv2_2(x))
x = self.pool2(x)
x = self.relu3_1(self.conv3_1(x))
x = self.relu3_2(self.conv3_2(x))
x = self.relu3_3(self.conv3_3(x))
x = self.pool3(x)
x = self.relu4_1(self.conv4_1(x))
x = self.relu4_2(self.conv4_2(x))
x = self.relu4_3(self.conv4_3(x))
x = self.pool4(x)
x = self.relu5_1(self.conv5_1(x))
x = self.relu5_2(self.conv5_2(x))
x = self.relu5_3(self.conv5_3(x))
x = self.pool5(x)
x = x.view(x.size(0), -1)
output = self.classifier(x)
return output
def vgg_train():
epochs = 10 # 训练次数
learning_rate = 1e-4 # 学习率
net = VGGTest()
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(net.parameters(), lr=learning_rate) # Adam优化器
for epoch in range(epochs): # 迭代
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data # labels: [batch_size, 1]
# print(i)
# print(labels)
# 初始化梯度
optimizer.zero_grad()
outputs = net(inputs) # outputs: [batch_size, 10]
# print(outputs.shape)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印loss
running_loss += loss.item()
if i % 20 == 19: # print loss every 20 mini batch
print('[%d, %5d] loss: %.5f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 我们测试数据是CIFAR10,图像大小是 32*32*3
if __name__ == '__main__':
vgg_train()
效果如下:
[1, 20] loss: 0.02316
[1, 40] loss: 0.02246
[1, 60] loss: 0.02174
[1, 80] loss: 0.02091
……
[1, 1120] loss: 0.00908
[1, 1140] loss: 0.00822
[1, 1160] loss: 0.00790
[1, 1180] loss: 0.00754
……
刚刚也说了,也可以直接使用model.vgg16()的模型,只不过需要把最后的FC层全部替换掉。如下:
class VGGTest(nn.Module):
def __init__(self, num_classes=2): #num_classes,此处为 二分类值为2
super(VGGTest, self).__init__()
net = models.vgg16(pretrained=True) #从预训练模型加载VGG16网络参数
net.classifier = nn.Sequential() #将分类层置空,下面将改变我们的分类层
self.features = net #保留VGG16的特征层
self.classifier = nn.Sequential( #定义自己的分类层
nn.Linear(512 * 7 * 7, 512), #512 * 7 * 7不能改变 ,由VGG16网络决定的,第二个参数为神经元个数可以微调
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 128),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
这个模型和上面自己写的一起放在一起对比看,就会更容易学习VGG16的结构。
感谢参考的文章:
https://www.cnblogs.com/lfri/p/10493408.html
https://www.it610.com/article/1295252184836939776.htm
https://blog.csdn.net/hnu_zzt/article/details/85092092
https://blog.csdn.net/mao_hui_fei/article/details/89477938