实验目的
是为后续的转换SNN网络,写一个基础的ANN,所以ANN的结构存在一些限制
- 1.均没有使用偏置Bias(在Conv2d和Linear)
- 2.没有使用Batch Normalization层(后续SNN转换要融合BN层,先不想写hhh)
就是很基础的代码,没有太多技巧可言,这里主要记录遇到的问题。
代码地址:https://github.com/ppx-hub/PyTorch_VGG16_Cifar10/tree/main
参考代码:
1.VGG16实现Cifar10分类(PyTorch)
2.使用pytorch实现VGG16模型(小白学习,详细注释)
实验结果
- 1.硬件:2块A100 PCIe 40GB,150个epoch所需时间:3472.9s
所需的内存很小,一块跑起来时间也类似
lspci | grep -i nvidia # 得到显卡型号的16进制码
# 在这个网站输入16进制码查显卡型号
# http://pci-ids.ucw.cz/mods/PC/10de?action=help?help=pci
# nvidia-smi也可以,只是我这里显示省略号看不全
- 2.Best_acc: 91.93%(在epoch为130时),即error为8.1%

遇到问题
1. loss不下降
最开始按着参考代码的超参数训练网络,原始网络loss是下降的,但是去掉BN层后怎么调整学习率loss也不下降,这里的主要原因应该是原始网络中没有参数的初始化,加入BN层,减少了网络对参数初始值尺度的依赖。但是我们去掉BN层,又不加参数初始化就有一定的问题。
解决方案:定义网络时对参数进行初始化
class VGG(nn.Module):
def __init__(self, base):
super(VGG, self).__init__()
self.features = nn.Sequential(*base)
self.classifier = nn.Sequential(
nn.Linear(512, 512, bias=False),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, 256, bias=False),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(256, 10, bias=False)
)
# 初始化权重
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
# method 2 kaiming
nn.init.kaiming_normal_(m.weight.data)
2.数据增强选择
可以使用torchvision.transforms在训练时对图像进行增强。Compose可以生成PiPeLine从而方便处理,例如
data_transform={
'train':transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
在ImageNet时代里,一个常用的图像预处理手段就是先对图像(记作 )做归一化,即所有的像素都除以255,因为RGB格式的图像所包含的最大像素值为255,最小像素值为0。因此,通过除以255即可将所有的像素值映射到01范围内,然后再使用均值和标准差做进一步的归一化处理。均值和标准差是从ImageNet数据集中统计出来的,按照RGB通道的顺序,均值为[0.485, 0.456, 0.406],标准差为[0.229, 0.224, 0.225]
(引用自YOLO入门教程:YOLOv1(7)-数据预处理)
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
就是完成了上述过程

注意不同的数据集选择的数据增强方式会有所不同,参考https://github.com/aaron-xichen/pytorch-playground中的预训练模型,我们采用如下的数据增强方式。
if train:
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10(
root=data_root, train=True, download=True,
transform=transforms.Compose([
transforms.Pad(4), # 先四个边都填充4 32x32 -> 40x40
transforms.RandomCrop(32), # 再随机裁剪到32(训练图像大小需要)
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])),
batch_size=batch_size, shuffle=True, **kwargs)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))这里均值和方差的选择原则
可以参考:pytorch中归一化transforms.Normalize的真正计算过程
cifar10数据集选用((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))效果会更好一些(个人结果)
3.加载保存的权重时出现Missing key(s) in state_dict
这是由于使用nn.DataParallel进行了多卡训练,但是这样包装后的模型参数的关键字会比没用nn.DataParallel包装的模型参数的关键字前面多一个“module.”
注意对这个进行处理:
pytoch使用nn.DataParallel导致Missing key(s) in state_dict错误.
同时需要注意若是保存的是权重而非整个模型,即net.state_dict(),则需要用net.load_state_dict(torch.load(b))加载,而不是torch.load()直接加载。
4. 准确率差一点
实验目的是复习Going Deeper这篇文章,文章中的ANN top-1 error为8.3%
刚开始训练网络在测试集上的结果acc最好为91.2%,也就是8.8%,为了降低几个点的错误率,进行了超参数调整。
- 1.Batch_Size调小,从100调整为64
- 2.Learning_Rate动态调整,采用warmup(前五个epoch)和阶段调整lr
采用预训练模型进行微调(可选)
torchvision.models.vgg16(pretrained=True)可以直接用pytorch官方再Imagenet上训练好的模型,需要注意的是要想改成Cifar10上的分类,可以只选用fc层前面的权重。后面再接输出10类的神经元。
例如这样设计网络
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.features = torchvision.models.vgg16(pretrained=True).features
self.classifier = nn.Sequential(
nn.Linear(512, 256, bias=False),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(256, 10, bias=False)
)
# 初始化权重
for m in self.modules():
if isinstance(m, nn.Linear):
# method 2 kaiming
nn.init.kaiming_normal_(m.weight.data)
def forward(self, x):
x = self.features(x) # 前向传播的时候先经过卷积层和池化层
x = x.view(-1, 512)
x = self.classifier(x) # 再将features(得到网络输出的特征层)的结果拼接到分类器上
return x
fine-tune时学习率可以设置的小一些。
但是预训练模型好的模型有bias,我们不适用,所以只作为参考
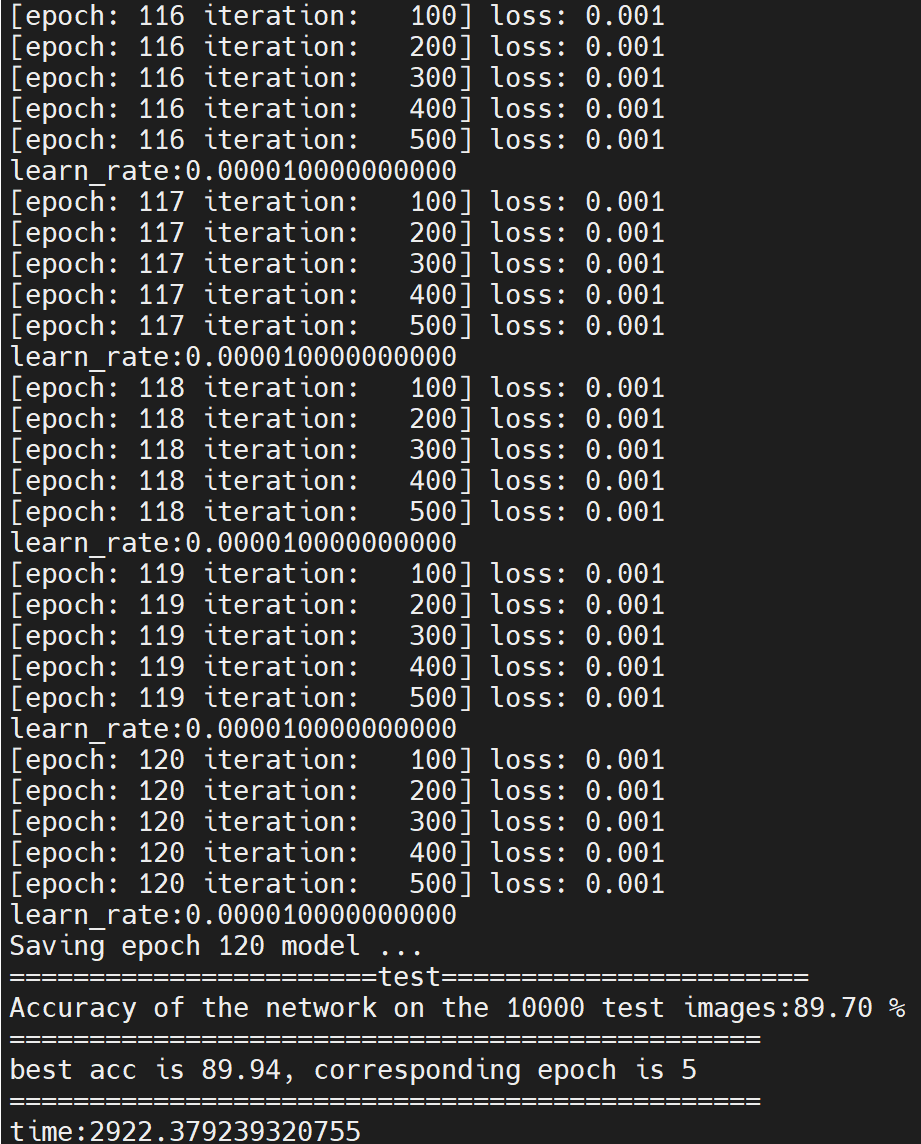
输出best acc对应的eopch忘记乘10了,对应的epoch是50…