AWS数据库服务
1 关系数据库RDS基础
-
关系数据库定义:一个关系数据库就是数据项之间存在预定义关系的一个集合;数据项通过一系列的表被组织起来,每个表由行和列组成;一个表中的列保存某类数据,以及保存一项属性的值。在一个对象或者实体中,一个表中的行表示一组相关的值;一个表中的每一行可以用一个唯一的值来标识,这个就叫做主键;sql语言是和关系数据库进行交互的主要接口
-
AWS RDS定义:它是一个提供工业标准的云关系数据库被管理服务;它提供工业标准数据库引擎;它便于扩展或者收缩;AWS会为RDS提供高性能、高可用、安全和兼容性,我们只需要专注于管理数据库本身就可以了。管理和使用AWS RDS,我们不需要管理任何操作系统层面的东西,不需要为OS打补丁和更新,而是直接管理RDS程序和版本;由AWS管理备份,补丁和故障检测;首要实例和保持同步的备用实例以保证高可用性;可以使用只读副本来提高读取性能;数据加密;
-
AWS RDS主要提供的数据库类型,注意 Amazon Aurora数据库可以和mysql或postgresql兼容

-
RDS 数据库基础
- 一个数据库实例就是一个运行在云端的独立数据库环境。一个用户最多可以有40个RDS数据库实例,若用户使用的Oracle或 SQL server数据库,那么最多可以有10个数据库实例,其他均为40个
- 每个数据库实例有一个标识符可以供用户使用。虽然数据库运行在实例上,但是用户不能访问数据库底层的EC2实例
- RDS支持三种类型的EC2实例:标准,内存优化和可突增性能实例
- RDS使用EBS存储,所以也提供三种存储类型:GP2,IO1和磁性介质
2 RDS应用
-
实验内容

-
part 1
- 点击左侧导航栏处的 dashbord,点击 create database,先选择标准创建,创建一个mysql的数据库,在templates处选择free tier。在下面的 DB instance identify处自定义数据库名称。在下面指定数据库的密码。下面将它放置于默认的vpc中的私有网段中。安全组处可以创建一个,自定义名称即可。在additional configuration处,自定义名称。其他全部默认即可(或者可以根据实际需要设置),点击create


- 点击左侧导航栏处的 dashbord,点击 create database,先选择标准创建,创建一个mysql的数据库,在templates处选择free tier。在下面的 DB instance identify处自定义数据库名称。在下面指定数据库的密码。下面将它放置于默认的vpc中的私有网段中。安全组处可以创建一个,自定义名称即可。在additional configuration处,自定义名称。其他全部默认即可(或者可以根据实际需要设置),点击create



- 创建一个实例,在user data处输入脚本,内容如下。在安全组处需要开放80和22端口。在安全组处,将数据库的那条安全组设置,允许访问处修改为刚才创建的实例的安全组
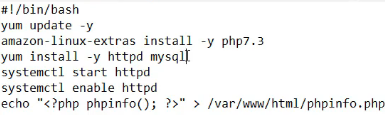
- 此时去浏览器输入 http://ip/phpinfo.php,可以访问到发布页面即可
- part 2
- 在RDS界面处,点击数据库名,就可以查看到数据库的详细信息,在下面的 connectivity & security处,可以查看到数据库的 endpoint & port,这里的 endpoint就是访问数据库的方法,将其复制,进入到公网实例控制台中输入
mysql -h endpoint的内容 -u admin -p,输入密码后即可登录进入到数据库。 - 创建一个名为 wordpress的数据库。
cd /var/www/html,wget https://wordpress.org/latest.tar.gz,tar zxf latest.tar.gz,cd wordpress,此时在浏览器输入ip/wordpress,就会自动进入配置页面。【注意:访问浏览器时使用的是公网ip,在控制台上连接时使用的是私网ip】,点击左下角的进入,就可以进入到配置页面 - 进入后的数据库名称处就是前面创建的数据库,用户名和密码可以使用管理员的,也可以创建新的;在 database host处,需要将数据库的 endpoint复制进去,其他默认,点击提交;提交后会提示没有写的权限,将所显示的代码复制,点击run。此时需要回到控制台,进入
/var/www/html/wordpress目录,vi wp-config.php,将刚才复制的内容写入,然后再回到留恋其页面,点击run即可 - 此时就进入到了这个wordpress博客站点,这里需要自定义名称。输入用户名,这里的密码是随机生成的,需要自己保存,输入邮箱后,点击 install即可。
- 此时就可以登录进入wordpress,可以点击 write your first blog ,写一些内容,然后发布。此时进入数据库查看,会发现自动创建了一些表格,
use wordpress,show tables;。
- 在RDS界面处,点击数据库名,就可以查看到数据库的详细信息,在下面的 connectivity & security处,可以查看到数据库的 endpoint & port,这里的 endpoint就是访问数据库的方法,将其复制,进入到公网实例控制台中输入
3 RDS特色功能
1)多高可用域和只读副本
- multi-AZ(多高可用域):RDS使用 multi-AZ 来创建一个在不同AZ中,并和主数据库进行同步的备用数据库,以实现高可用和支持故障转移(备用数据库不可用作只读扩展)【实际上就是主从复制】。Aurora数据库本身就支持多可用区部署的高可用设置,因此不需要为Aurora数据库特别开启这个功能。高可用的设置只是用来解决灾备的问题,并不能解决读取性能的问题;要提升数据库读取性能,我们需要用到Read Replicas。
- Read Replica(只读副本): MariaDB/mysql/oracle/postgresql使用从源数据库创建只读副本的功能,减轻源数据库的负载并达到提高读性能的目的【也就是说数据库的读写分离或者说是达到一个缓存的效果】;只读副本使用的是异步复制来复制变更数据,他们也可以存在不同于源数据实例的地区;可以将一个只读副本提升为一个独立的实例,来作为一个容灾解决方案
- 特点:是用来提高读取性能的,不是用来做灾备的;要创建只读副本需要源RDS实例开启了自动备份的功能;可以为数据库创建最多5个Read Replicas;可以为Read Replicas创建Read Replicas;可以为一个启用了Multi-AZ的数据库创建Read Replicas;Read Replicas可以提升成为独立的数据库;可以创建位于另一个区域(Region)的Read Replicas
2)快照和备份
- 自动备份每天在指定的备份窗口常见一个数据库的备份,备份可以被保留最多35天
- RDS还会每5分钟将事务日志商场到s3进行备份
- 用户可以发起时间点的数据恢复,并指定备份保留日期内的某个时间节点。最近恢复点一般在最近的5分钟内
- RDS的快照需要手动进行,用户可以自行创建快照来进行手动备份。手动备份在数据库实例被删除后仍然会被保留
- 在你删除数据库的时候,所有的自动备份都会被删除
3)安全实践
- 在vpc中运行数据库实例,并采用最大程度可能性的网络访问控制
- 使用IAM给数据库管理员和用户赋予对应的权限
- 使用安全组来控制可以访问数据库的资源或者服务
- 使用SSL对数据库的连接进行加密
- 使用RDS加密对保存的数据库实例,日志,备份还有快照进行保护
- 如果在创建数据库的时候没有加密,我们不能在事后对其进行加密。但我们可以创建这个数据库的快照,复制该快照并且加密这个复制的版本
4) 实验:
- 进入到RDS创建数据库的界面,进入到之前创建好的数据库,actions–>create read replica,此时可以选择同一个地区的不同zone或者不同地区,其他选项依照实际情况选择,在settings处,选择只读副本的源,然后自定义名称,最后点击 create即可。
- 此时就可以进入并看到其详细信息,复制其endpoint 并打开控制台连接该只读数据库,
show databases;,此时可以看到其内容与主数据库中是一模一样的,use wordpress,show tables;,也是一样的;输入create database test;此时就会报错,显示只读 - 如果需要将只读数据库promote(将数据库独立出来),可以点击actions–>promote,完成后,该数据的状态就不再是只读,而是变成了一个单独的数据库。此时再连接上该数据库,是可以进行读写操作的
- 注意清理实验环境,放置产生费用,在删除时,会有一个 create final snapshot ,表示是否在删除后才创建一个快照,方便后面恢复或使用,可以根据实际情况选择,为了清理实验环境,可以取消勾选该项
4 RDS Aurora数据库
- Amazon开发的数据库系统,和mysql以及postgresql数据库兼容(该数据库在创建时可以指定与那个数据库进行兼容),其相比于其他两种数据库有3-5倍的性能提高
- 它可以自动创建集群,自动复制以及自动扩展
- Aurora自动维持6份数据库数据,并存放在3个同区域的AZ中
- 可以提供不同的节点类型
- 首要数据库实例,用于读写操作
- 只读节点用于只读操作
- 用户自定义节点,用于数据库操作的负载均衡
- 可以创建两种数据库集群
- single region DB :单区域单一集群数据库(一个首要实例;最多可以有15个只读副本存放在多个AZ)
- global DB:全球数据库(主区域运行一个主数据库集群,供读写操作;第二区域(地区)运行只读副本集群,最多16个副本;跨区域之间复制的延迟一般小于1秒;第二集群在一分钟内可以被提升为主集群并可用于写操作)
- 实验:
- 进入数据库创建页面,选择标准,在数据库类型处,选择 Aurora数据库,在下面的edition处可以选择与哪一个数据库兼容,下面的database location处就可以选择 regional或global,默认即可;在 database features处选择第一个,如果选择第二个表示用户不需要关心数据库底层的硬件;在模板处选择 生产,下面的设置与mysql基本一致,按需求选择即可。完成后点击create即可
- 创建完成后就可以查看到其详细信息,注意这里会自动有两个数据库,会自动创建一个只读数据库,并且两个数据库呈树形排列。在其详细信息处可以看到它有两个endpoint
- 可以在actions处对其做相应操作
5 NoSQL DynamoDB数据库
-
概念:不同于在关系数据库中使用表格式关系的数据库存储方式,一个nosql数据库使用多种方式来存储和检索数据;起初表示非SQL或者非关系数据库,但是随着大数据和实时web应用时代变得日益流行,现在也成为 Not Only SQL;在nosql类型的数据库中,集合(Collection)- 相当于关系数据库中的表、文档(Document)- 相当于关系数据库中的行、键值(Key Value Pairs) = 相当于关系数据库中的列
-
aws中nosql数据库类型:
- 键值型:dynamoDB
- 文档型:documentDB/dynamoDB
- 图标型:Neptune
- 基于内存型:elasticache
- 搜索型:elasticsearch
-
dynamoDB特性:
- 是全托管的nosql数据库服务,并提供快速可预期的性能及无缝的扩展性。
- 无服务器数据库服务,并非是 没有服务器,它底层使用的依旧是ec2的实例,只不过对用户来说,不需要考虑以及管理底层实例,用户只需要使用即可
- 最终一致性【默认的读取方式】(最终用户读到的更新后的数据时一致的)和强一致性(如果同时有读和写的操作,保证写之后立马可读)
- 能存储任何数据量和应对任何级别的请求
- 无需停机即可方便的扩展或者收缩带宽
- 所有数据库数据存储在SSD上并复制到同个区域的多个AZ上
-
dynamoDB核心概念
- 表:一组数据的集合
- 项目:属性的一组集合(和数据库中的行类似,相当于元祖)
- 属性:基本数据项(和数据库中得列类似)
- 主键:单一主键(只有一个属性作为主键)和组合主键(有两个或两个以上的属性作为主键)
- 无架构:属性及数据类型无需预先定义(每个元祖所包含的属性可以不一样,属性多少也可以不同)
- 标量属性:只有一个值
- 嵌套属性:比如地址属性,里面会有具体的其他属性

-
dynamoDB Accelerator服务(DAX):加速器
- DAX是一个基于内存的缓存服务。 即便在每秒数百万级别的数据请求下,它仍可以提供从毫秒到微妙,高达十倍性能提升的响应
- 适用于 需要对读操作提供最快响应的应用、对某小部分数据项有更频繁读取操作的应用、读取密集型并且对费用敏感的应用、需要对大型集合数据进行重复性读取操作的应用
-
实验:
- 进入dynamoDB界面,点击create table ,自定义名,指定主键并勾选add sort key,直接在这里自定义名即可 ;在下面的 table setting处将 use default settings 的勾选取消,表示不使用默认设置;在 读写容量处,选择on-demand ,表示需要多少读多少,其他默认即可,点击create。
- 此时可以进入数据库查看其详细信息,在 items处可点击 create item创建数据,在其actions处的 edit就可以添加新的键。如果某条数据添加错误,需要修改时,点击actions --> duplicate 进行修改,修改完后会有之前和修改后的两条记录,将错误的记录删除即可
6 Redshift 数据仓库
-
概念:数据仓库就是一个中央信息储存库,可被用来做数据分析以帮助用户做更好的决策
-
数据仓库和交易型数据库对比:

-
Redshift 是一种完全托管的PB级云数据仓库服务
-
Redshift 的核心基础设施组件是集群,其工作原理如下所示
- 多节点部署模式:领导节点——管理连接和接受请求;计算节点——存储数据,执行请求和计算任务,最多可以有128个计算节点

- 多节点部署模式:领导节点——管理连接和接受请求;计算节点——存储数据,执行请求和计算任务,最多可以有128个计算节点
-
数据仓库是一种列式存储,将一列的信息作为一个block存储起来,其优点是每一列的信息都是同种数据类型,所以会方便数据的压缩节省空间

-
特点:
- 目前 redshift只支持单AZ的部署
- redshift总是保持3份拷贝数据,包括计算节点的源数据和s3的副本
- redshift 的WLM功能使用户可以管理负载的优先级,使得短暂查询不必在长队列中等待耗时查询完成才能进行
- redshift spectrum使得用户可以从 s3中的文件进行有效的查询和检索结构化和半结构化数据,而不必将数据加载到redshift表中
7 ElastiCache云缓存
- 通过将数据缓存到全托管,基于内存的ElastiCache服务里面,可以大幅度提升网络应用性能。
- Elasticache通过在内存中缓存数据来减少对象读取数据库的次数,减轻了数据库的负载,以及提高了网站的访问速度(内存的访问速度比磁盘的访问速度高很多)。一般来说我们会把相对来说更新频繁的“热数据”放在Elasticache中,把“冷数据”还是放在数据库中,以支持及时的更新。
- 目前ElastiCache主要支持两种类型的引擎,memcached和Redis

8 OLTP/OLAP
数据处理大致可以分为两类,分别是OLTP和OLAP
1)联机事务处理OLTP(Online Transaction Processing)
- OLTP是传统的关系数据库的主要应用,是基本的日常事务处理,例如银行交易等。
- OLTP包括了以上所说的关系数据库SQL Server,Oracle,MySQL Server,PostgreSQL,Aurora,MariaDB等。
2)联机分析处理OLAP(Online Analytics Processing)
- OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且能提供直观易懂的查询结果。OLAP是用来做商业智能方面的分析的。常用的流行工具是AWS Redshift
- 数据仓库有更好地读取速度和更加便利的分析和查询方式。