环境
Leo采用的环境为:
Ubuntu-Kylin-16.04
jdk1.8.0_151
Hadoop-2.9.0
Hive安装版本:2.1.0
一、解压缩文件
前提,Leo的VBox安装了增强功能,挂载Windows系统中的Install文件夹
也可以通过FileZilla进行ping通IP后导入压缩文件
1.mount挂载文件夹 /pcshare

2.查看权限

3.解压到 /usr/local文件夹下 利用tab键自动补全

4.mv [a] [b]重命名 b是新名字(b名字在文件夹里不存在)

5.修改文件权限使hadoop这个用户能使用

二、配置环境变量
1.vim编辑器,编辑/.bashrc文件

文件最下方添加HIVE的HOME和PATH

2.修改hive-site.xml.template文件,重命名为hive-default.xml

新生成一个hive-site.xml进行编辑
利用Tab键空行排版,一定一定要细心检查几遍
把<!—>注释框框删掉


三、配置mysql(之前已经安装完成)
1. 解压connector文件

2. 向hive导入jar包(Tab键自动补全)

3. 启动服务,登陆Shell界面

4. 新建hive数据库

5. 配置MySql允许hive接入

6. 启动hive,先启动Hadoop伪分布式集群
几个守护全部开启(jps)
Start-all.sh


开启hive

某种错误出现——黄线部分

配置单元Metastore数据库未初始化
为Hive建立相应的MySQL账户,并赋予足够的权限,执行命令如下

允许hive接入

同样地,刷新权限表

以hive用户登陆mysql,密码是hive

这是由于没有初始化数据库,生成元数据。
需要执行以下指令(在hive的bin目录下执行)
./schematool -initSchema -dbType hive(hive是database 的名字)

反复摸索6次后,我的hive起来了


利用MySQL数据库保存Hive元数据
四、Hive的基本操作:
(1) 创建database
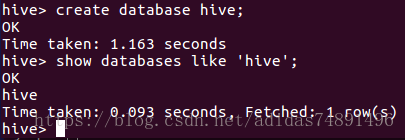
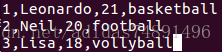
(2) /usr/local下新建一个usr.txt(用以存储数据信息)
记得用sudo给Hadoop用户赋予root权限


(3) 导入database hive

(4) Describe table

(5) 查询功能

(6) Overwrite重写前一个table usr,创建拥有相同列的空表 new_usr

出现了神秘问题(提示我使用Hive 1.x.y的版本)
Hive-on-MR在Hive 2.x.y中不推荐使用,并且可能在未来的版本中不可用
可能是hadoop的block的冗余数量没设置正确,
也可能是版本不完全匹配的问题
Apache-Hadoop官方文档显示适配 Hive1.x.y 的版本
安装之前最好上Apache的官网上瞅瞅说明
PS:【http://www.apache.org/ 网页上方的project里找到Hadoop或者Hive】