
Hive概述
Hive基于Hadoop的数据仓库工具,提供了一系列的工具,可以用来进行数据提取、转化、加载,是一种可以存储、查询和分析存储在Hadoop中的大规模数据机制。它可以将结构化的数据文件映射成一张表,并提供完成的sql查询功能,可以将sql语句转换成MapReduce任务进行运行。
Hive本质上是基于Hadoop的一种分布式计算框架,底层仍然是MR,本质上是离线大数据分析工具。
数据仓库 VS 数据库
| 数据库 | 数据仓库 | |
|---|---|---|
| 系统类型 | Online Transaction Processing OLTP 联机事务处理系统 |
Online Analytical Processing OLAP 联机分析处理系统 |
| 服务对象 | 为线上系统提供实时查询 | 为离线分析存储历史数据 |
| 功能分类 | 具有完整的增删改查能力 | 只支持一次写入多次查询,不支持航级别的增删改 |
| 事务特征 | 具有完整的事务能力 | 不强调事务的特性 |
| 设计原则 | 避免冗余 提高存储和处理的效率 | 人为冗余 提高查询的效率 |
Hive特点
- 建立表格时,不是建立一张传统意义的数据表,而是将数据文件映射成一张数据库表,并提供完整的sql查询功能
- 受限于Hadoop的HDFS设计,1.0不支持行级别增删改,2.0可以支持追加操作
- 离线数据分析工具
- 不支持事务的特性,追求性能
- 通常会通过制造冗余来提高数据查询性能
安装配置要点
需配置JAVA_HOME和HADOOP_HOME,并配置MySQL来替换内部的Derby数据库存储元数据。
内置Derby问题:
- 数据易消失:Derby为文件型数据库,进入时会检查当前目录是否会有metastore.db的文件夹(存储数据库),没有就新建,会造成换目录登录,元数据就找不到。
- 仅支持单用户操作:Derby是单用户型的数据库,无法支持多用户操作。
配置MySQL要点:
- 修改conf/hive-site.xml 文件
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
- 将mysql驱动【mysql-connector-java-******-bin】复制到hive的lib目录下
- mysql元数据库中的hive库,必须是latin1的编码集
Hive的重要的元数据表
DBS :存储了hive中库元数据的信息,包括库编号、库名称 库所有者 库对应在hdfs中的存储位置
TBLS:存储了hive中表相关的信息,包括表的编号、所属库的编号、表所有者、表名称、表类型
COLUMNS_V2:存储了hive中表对应列的信息,包括所属表的编号、列名称、列类型、列的位置
SDS:存储了hive中表对应在HDFS中的存储位置信息,包括表的编号、存储位置
Hive的各种表
1 内部表 VS 外部表
| 对比项 | 内部表 | 外部表 |
|---|---|---|
| 定义 | 先有表再有数据 | 先有数据再有表 |
| 特点 | 执行表格删除时,会删除原表 | 执行表格删除时,不会删除原表 |
| 创建语句 | create table student (id int, name string) row format delimited fields terminated by ‘\t’; |
create external table teacher (id int ,name string) row format delimited fields terminated ‘\t’location ‘/teacher’; |
| 导入表格 | load data local inpath ‘/home/software/1.txt’ into table stu; |
本来就是导入的 |
2 分区表
表的文件夹下再创建分区对应的文件夹,将表中的数据按照分区字段分放在不同的分区文件夹下,这样之后按照分区字段查询数据时,可以直接找到分区文件夹得到数据,而不用在全部数据中进行过滤,从而提升了查询的效率。
2.1 操作语法
创建表:
create table book (id bigint, name string) partitioned by (country string,…) row format delimited fields terminated by ‘\t’;
加载数据:
load data local inpath ‘./book_china.txt’ into table book partition (country=‘china’,…);
修改结构分区:
alter TABLE book add PARTITION (country=‘jp’,category = ‘xs’) location ‘/user/hive/warehouse/…’;
查询表:
select * from book where category=‘cn’;
显示分区:
show partitions iteblog;
删除分区:
alter table book drop partition(category=‘cn’)
修改分区:
alter table book partition(category=‘french’) rename to partition (category=‘hh’);
3 分桶表
Hive中也支持分桶表,分桶表是一种更细粒度的数据分配方式,主要作用是实现数据的抽样,方便进行数据测试。分桶表通过hash分桶算法,将数据分放在不同的桶(hdfs中的文件)中,方便后续获取。
3.1 分桶语法
开启分桶功能:hive>set hive.enforce.bucketing=true;
创建带桶的表:create table teacher(name string) clustered by (name)into 3 buckets row format delimited fields terminated by ‘’;
Hive的分桶过程是在底层的MR中实现的,所以必须在一个MR过程中分通才可以实现,通常我们不会直接在原始的表中实现分通,而是单独创建一个带有分通的测试表,从原始表中向分桶的测试表中导入数据,在导入的过程中,触发MR操作,实现分桶。
往表里插入数据:insert overwrite|into table teacher select * from tmp;//需要提前准备好结构相同的tmp,从tmp查询数据写入到teacher,分桶表仅能从另一张表导入数据,触发MR
分桶语法—TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
其实,无论表是否进行过分桶或分桶的数量和抽样的数量是否相同,都不影响tablesample函数执行抽样的过程,但是如果能够保证表是经过分桶的且分桶的数量和抽样的数量相同,则tablesample函数可以直接从表对应的文件夹下获取物理分割好的桶数据返回,从而可以具有良好的性能,所以建议如果对海量的数据进行抽样,最好经过分桶后再抽样,且保证桶的数量和抽样的数量相同。
**查询数据:**select * from teacher_temp tablesample(bucket 1 out of 2 on id);
Hive的自定义函数
hive自定义函数有三种形式:UDF、UDAF、UDTF
UDF:一进一出
UDAF:多进一出 类似sum()、min()、avg()、max()
UDTF:一进多出,通俗来说就是进来一个字段返回多个字段,符合本需求
UDF
Hive允许用户自定义一些函数,供后续调用,Hive的UDF的能力,相当于为HIVE提供了一定的扩展能力,开发者可以通过开发HiveUDF来扩展Hive,实现特定功能。
-
创建HiveUDF类
package cn.hey.hive.udf; import java.math.BigInteger; import org.apache.hadoop.hive.ql.exec.UDF; //编写一个类,继承 org.apache.hadoop.hive.ql.exec.UDF public class MyUDF extends UDF{ //编写一个公有的 evaluate 方法 public String evaluate(String str,Integer num01,Integer num02){ try { BigInteger result=BigInteger.ONE; for(int i=0;i<num02;i++){ result=result.multiply(BigInteger.valueOf(num01)); } return "hello~"+str+"+! The result is "+result+" !"; } catch (Exception e) { e.printStackTrace(); throw new RuntimeException(); } } } -
打包上传
打包的时候如无外部jar包,可以仅打包UDF类文件。Hive内会关联JDK和Hive自己的包。
打包好的jar包放在hive主文件夹的lib目录下。
-
注册函数
注册临时函数
1 加载jar包:add jar /path/xx.jar(存储在本地磁盘)
2 注册临时函数:create temporary function 函数名 as ‘包名.类名’;
3 删除临时函数:drop temporary function 函数名字;
##注册jar hive> add jar /usr/local/src/hive/apache-hive-1.2.0-bin/lib/test01.jar > ; Added [/usr/local/src/hive/apache-hive-1.2.0-bin/lib/test01.jar] to class path Added resources: [/usr/local/src/hive/apache-hive-1.2.0-bin/lib/test01.jar] ##注册临时函数,重新登录hive时函数会失效 hive> create temporary function tt as 'cn.hey.hive.udf.MyUDF'; OK Time taken: 1.003 seconds注册永久函数
如果需要注册成永久函数,Hive仓库是非本地的,需要将jar包上传非本地的路径上,例如HDFS,否则将会报错。
1 注册永久函数:CREATE FUNCTION 函数名 AS ‘包名.类名’ USING JAR ‘hdfs:///path/xxxx.jar’
2 删除永久函数:drop function 函数名;
hive> create function intoBig as 'cn.hey.hive.udf.MyUDF' using jar 'hdfs:///tmp/test01.jar'; converting to local hdfs:///tmp/test01.jar Added [/tmp/736e4db8-8ef3-4c61-b1a7-2d82b4e3789d_resources/test01.jar] to class path Added resources: [hdfs:///tmp/test01.jar] OK Time taken: 1.479 seconds -
调用函数
select function ;
hive> select intoBig("hello",10,10); OK hello~hello! The result is 10000000000 ! Time taken: 1.212 seconds, Fetched: 1 row(s)
Hive的JDBC操作
1 启动连接
启动server2服务接收JDBC操作
./hive --service hiveserver2
#前台启动 每次完成返回一个ok
[root@student01 bin]# ./hive --service hiveserver2
OK
OK
#后台启动 每次完成返回一个ok
[root@student01 bin]# ./hive --service hiveserver2 &
[1] 8599
[root@student01 bin]# OK
如果没有启动server2服务,或没有在前台启动,则会报java.sql.SQLException,告连接失败:
Exception in thread “main” java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://192.168.161.121:10000/parkdb: java.net.ConnectException: Connection refused: connect
2 建立jdbc连接文件
导入关键JAR包:
- hadoop-2.7.1\share\hadoop\common下的 hadoop-common-2.7.1.jar
- hive\lib目录下的 hive-jdbc-1.2.0-standalone.jar
package cn.hey.hive.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
//为了简便没有用规范try-catch-finally结构操作jdbc,仅供测试
public class helloJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//1 注册驱动 --加载jar包后输入HiveDriver,ctrl+鼠标左键可见类名
Class.forName("org.apache.hive.jdbc.HiveDriver");
//2 获取数据连接
Connection conn = DriverManager
//使用了hive1.2.0版本,所以是hive2,端口号默认10000,可更改
.getConnection("jdbc:hive2://student01:10000/heydb","root","root");
//3 获取传输器
PreparedStatement ps = conn.prepareStatement("select * from student");
//4 传输sql后执行操作,后取结果集
ResultSet rs = ps.executeQuery();
//5 遍历结果集
while(rs.next()){
String name = rs.getString(2);//第二列
System.out.println(name+ "--ok");
}
//6 释放资源 --按先进后出顺序关闭资源,规范是放在finally中判非空后释放
rs.close();
ps.close();
conn.close();
}
}
Hive的优化
1 优化要点
Hive优化其实涉及到几方面,其中一方面是计算引擎方面的优化,比如你使用MapReduce作为计算引擎,那么就需要优化MapReduce;如果你选择Spark作为计算引擎,那么需要对Spark进行优化。
此处对Hive层面优化说明。
1 表设计层面优化
- 合理利用中间结果集,避免查过就丢的资源浪费,减低Hadoop的IO负载
- 合理设计表分区,包括静态分区和动态分区
- 尽量不使用复杂或低效函数,比如count(distinct),可以使用其他方式实现
- 选择合适的表存储格式和压缩格式
- 如果某些逻辑使用系统函数可能嵌套好几层,可以使用自定义函数实现
- 适当使用索引
2 语法和参数层面优化
-
合理控制mapper和reducer数
-
设置map和reduce的内存大小
-
合并小文件
-
避免数据倾斜,解决数据倾斜问题
-
减少Job数
-
Join优化
尽量将小表放到join的左边。小表和大表join时,如果差一个以及以上数量级并且小表数据量很小,可以使用mapjoin方式,将小表全部读入内存中,在map阶段进行表关联匹配。大表和大表进行关联时,要注意数据倾斜的问题。如果两个表以相同Key进行分桶,以及表的桶个数是倍数关系,可以使用bucket join,加快关联查询。
-
避免笛卡尔积
-
提前裁剪数据,减少处理的数据量,避免资源浪费
3 Hive Job优化
- 并行化执行——每个查询被Hive转化成多个阶段,有些阶段关联性不大,则可以并行化执行,减少执行时间。
- 本地化执行
- JVM重利用——JVM重利用可以是Job长时间保留slot,直到作业结束,这在对于有较多任务和较多小文件的任务是非常有意义的,减少执行时间。
- 推测执行——所谓的推测执行,就是当所有的task都开始运行之后,Job Tracker会统计所有任务的平均进度,如果某个task所在的节点配置内存比较低或者CPU负载很大,导致任务执行比总体任务的平均执行要慢,此时Job Tracker就会在其他节点启动一个新的相同的任务,原有任务和新任务哪个先执行完就把其他节点的另外一个任务kill掉。
- Hive中间结果压缩数据——中间压缩就是处理Hive查询的多个job之间的数据,对于中间压缩,最好选择一个节省CPU耗时的压缩方式
2 常用优化方法
1 map side join
当链接的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小的table直接放到内存中去,然后再对比较大的表格进行map操作。join就发生在map操作的时候,每当扫描一个大的table中的数据,就要去去查看小表的数据,哪条与之相符,继而进行连接。这里的join并不会涉及reduce操作。map端join的优势就是在于没有shuffle。
hive>set hive.auto.convert.join=true; #开启map side join
hive>set hive.mapjoin.smalltable.filesize=25mb
默认25mb,即当其中一个表的大小小于25mb时,自动启用mapJoin
注意:hive 在做join的时候,要求小表在前
2 join语句优化
-
优化前
hive> select m.cid,u.id form order m join customer u on m.cid=u.id where m.dt=’20160801’;
-
优化后
hive> select m.cid,u.id from (select cid from order where dt=’20160801’)m
join customer u on m.cid = u.id
注意:hive 在做join的时候,要求小表在前
3 group by 优化 – 处理数据倾斜
当group by 过程中出现倾斜,应该设为true,但是这种情况下,hive不支持多列上的去重操作
hive>hive.groupby.skewindata=true;
当选项设定为 true,生成的查询计划会有两个 MR Job。
第一个 MR Job 中,Map 的输出结果集合会随机分布到Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
第二个 MR Job 再根据预处理的数据结果按照 Group ByKey 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce中),最后完成最终的聚合操作。
4 count distinct 优化
-
优化前
hive>select count(distinct id )from tablename;
-
优化后
hive>set mapred.reduce.tasks=3; #count只会启动一个reduce,此处在会话级别增加reduce
hive>select count(*) from (select distinct id from tablename)tmp;
由于引入了DISTINCT,因此在Map阶段无法利用combine对输出结果消重,必须将id作为Key输出,在Reduce阶段再对来自于不同Map Task、相同Key的结果进行消重,计入最终统计值。
当Reduce Task个数为1,对于统计大数据量时,这会导致最终Map的全部输出由单个的ReduceTask处理。这唯一的Reduce Task需要Shuffle大量的数据,并且进行排序聚合等处理,这使得它成为整个作业的线程和运算瓶颈。
但是当Hive在处理COUNT这种全聚合计算时,它会忽略用户指定的Reduce Task数,而强制使用1。所以可以迂回的将一个job拆分为两个job进行,在不处理count Job的时候,就可以采用调控出来的Reduce Task数。
5 调整切片数(map任务数)
Hive底层自动对小文件做了优化,用了CombineTextInputFormat,将做个小文件切片合成一个切片。
合成完之后的切片大小,如果 > mapred.max.split.size的大小,就会生成一个新的切片。
mapred.max.split.size默认是128MB
set mapred.max.split.size=134217728(128MB)
对于切片数(MapTask)数量的调整,要根据实际业务来定,比如一个100MB的文件,假设有1千万条数据,此时可以调成10个MapTask,则每个MapTask处理1百万条数据。
6 JVM重用
hive> set mapred.job.reuse.jvm.num.tasks=20 (默认是重用1次,即不重用)
JVM重用是hadoop调优参数的内容,对hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或者task特别多的场景,这类场景大多数执行时间都很短。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成千上万个task任务的情况。
-
优点:使JVM实例在同一个JOB中重用N次,N的值可以在Hadoop的mapre-site.xml文件中进行设置。
-
缺点:开启JVM重用将会一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。
如果某个“不平衡“的job中有几个reduce task 执行的时间要比其他reduce task消耗的时间多得多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
Job & Task
一个MapReduce程序就是一个Job,而一个Job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce Task.
7 启用严格模式
hive>set hive.mapred.mode=strict #严格模式,非严格模式为unstrict
通过严格模式防止用户执行那些可能产生意想不到的不好的效果的查询,从而保护hive的集群。以下query会报错:
-
分区表的查询没有使用分区字段来限制
-
使用了order by 但没有使用limit语句。(如果不使用limit,会对查询结果进行全局排序,消耗时间长)
-
产生了笛卡尔积
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
8 关闭推测执行机制
因为在测试环境下我们都把应用程序跑通,如果还加上推测执行。
如果有一个数据分片本来就会发生数据倾斜,执行执行时间就是比其他的时间长,那么hive就会把这个执行时间长的job当作运行失败,继而又产生一个相同的job去运行,后果可想而知。
可通过如下设置关闭推测执行:
-
hive>set mapreduce.map.speculative=false
是否为 Map Task 打开推测执行机制,默认为 true,如果为 true,则可以并行执行一些 Map 任务的多个实例。
-
hive>set mapreduce.reduce.speculative=false
是否为 Reduce Task 打开推测执行机制,默认为 true。
-
hive>set hive.mapred.reduce.tasks.speculative.execution=false
是否开启 reducer 的推测执行,与 mapred.reduce.tasks.speculative.execution 作用相同,默认true。
数据倾斜问题
数据倾斜就是数据的key的分化严重不均,造成一部分数据很多,一部分数据很少的局面。
1 产生原因
-
硬件原因
单节点机器内存不够大,CPU、网络等资源不充足
-
业务原因
-
group by - 某些key的数量巨大,最后聚合时数据倾斜
-
distinct count(distinct xx)
count操作由于要使用聚合,只会调用一个reduce;而distinct操作由于在map阶段无法利用combine对数据进行聚合,后续只能按id在reduce阶段去重,但是如果只有一个reduce,会在suffle阶段承受相当大的压力
-
join
大表与小表join,但是小表的数据少且集中,分发到一个或某几个reduce上的数据远高于平均值;或者,大表与大表join,但是分桶判断字段的0值或空值过多,而这些值都由一个reduce处理,很慢
-
-
综合原因
- key分布不均匀
- 业务数据本身特性
- 建表时考虑不周
- 某些SQL语句本身就有数据倾斜
2 解决办法
-
参数调节
hive> hive.map.aggr = true map端做部分聚合,相当于combiner
hive> hive.groupby.skewindata = true 生成一个随机job和一个聚合job配合完成工作
-
SQL语句调节
-
Join的选择:
驱动表选用join key分布最均匀的表做驱动,同时做好列裁剪和filter操作,以达到量表join的时候,数据量相对变小。
-
大小表join
使用map join让小的维度表(1000条以下的)先进入内存,在map端完成聚合。
-
大大表join
把空值的key变成一个字符串加随机数,把倾斜的数据分到不同的reduce上,由于null值不会被关联,处理后不影响最终结果,如有需要,可以在后面统一去除。
-
count distinct 大量相同特殊值
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
-
count(distinct )
采用sum() group by 替代 count(distinct) 完成计算
-
特殊情况
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
-
Hive运行模式
1 架构组件
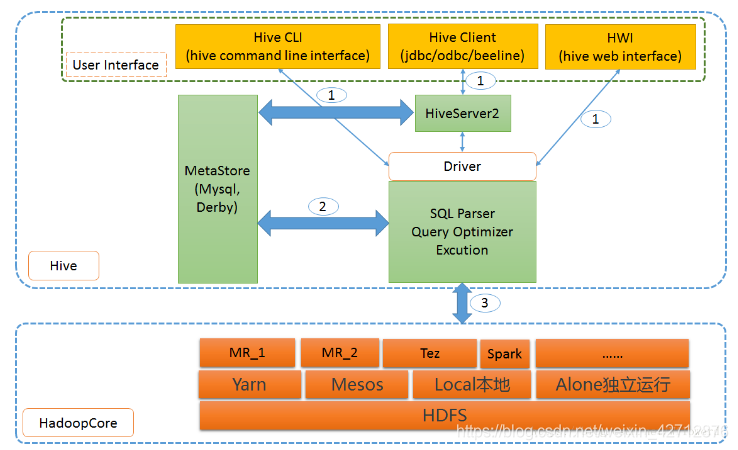
1 连接接口
-
CLI命令行 - 在hive> 下执行命令行操作
-
HiveServer2/beeline - 启动Hive客户端,使用其他客户端例如JDBC、beeline操作
Beeline是从 Hive 0.11版本引入的Hive新型命令行客户端工具,Hive客户端工具后续将使用Beeline 替代HiveCLI。Beeline是基于SQLLine CLI的JDBC客户端,支持嵌入模式(embedded mode)和远程模式(remote mode)。
在嵌入式模式下,运行嵌入式的Hive(类似Hive CLI),而远程模式可以通过Thrift连接到独立的HiveServer2进程上。从Hive 0.14版本开始,Beeline使用HiveServer2工作时,它也会从HiveServer2输出日志信息到STDERR。
-
Web UI - 在网页上操作Hive,需要源码包和安装ant,配置hive-site.xml
2 元数据库 Metastore
Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,
表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3 解释器(Complier)、优化器(optimizer)、执行器(executor)组件
这三个组件用于:HQL语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
4 Hadoop
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成。
2 工作流程
-
准备阶段
-
执行查询操作
命令行或Web UI之类的Hive接口将查询发送给Driver(任何数据库驱动程序,如JDBC、ODBC等)以执行。
-
获取计划任务
Driver借助查询编译器解析查询,检查语法和查询计划或查询需求
-
获取元数据信息
编译器将元数据请求发送到Metastore(任何数据库)。
-
-
编译阶段
-
发送元数据
Metastore将元数据作为对编译器的响应发送出去。
-
发送计划任务
编译器检查需求并将计划重新发送给Driver
-
-
处理阶段
-
执行计划任务
Driver将执行计划发送到执行引擎
-
执行job任务
在内部,执行任务的过程是MapReduce Job。执行引擎将Job发送到ResourceManager,ResourceManager位于Name节点中,并将job分配给DataNode中的NodeManager。在这里,查询执行MapReduce任务。
-
元数据操作
在执行的同时,执行引擎可以使用Metastore执行元数据操作。
-
-
返回阶段
-
拉取结果集
Fetch Result执行引擎将从datanode上获取结果集。
-
存储结果集到Driver
执行引擎将这些结果值发送给Driver
-
发送结果集到接口
Driver将结果发送到Hive接口
-
自动化运维设置
利用定时任务crontab -e 以及shell内置函数进行操作
Hive 练习题
Hive优化的要点
Hive优化包括Hive本身优化和计算引擎方面的优化,这里讲一下Hive层面的优化。
1 表设计层面的优化
2 语法和参数层面的优化
3 Hive Job优化
写出hive架构,并说说你理解的最重要的一层
Hive架构包含三个方面,包括Hive Clients(客户端)、Hive Services(服务) 、Hive Storage and Computing(存储与计算)。其中,客户端指的是Hive的外部接口,包括CLI命令行、webUI、HiveServer2客户端(含jdbc、beeline),服务端指的是以Driver为核心的数据编译、解析工具,主要负责连通客户端和存储计算架构的,存储与计算端主要是外部的计算引擎入MapReduce,Spark等等。
作为hive的架构,我认为服务层最为重要,因为服务层是连接客户端和存储计算层的中间间,兼容多种端口,是固定的组件,也在绝大多数上影响Hive内部性能。
hive下将/home/test.txt导入
1 未建表
hadoop fs -put /home/test.txt /user
create external table test (id int, content string) row formate delimited filed terminated by ‘\t’ location ‘/user/test.txt’;
2 已建表
hadoop fs -put /home/test.txt /user
load data local inpath ‘’/user/test.txt’ into table test;
hive中map join的原理以及适用环境
Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join),默认采用Common Join。Map Join就是在Map阶段进行表之间的连接。而不需要进入到Reduce阶段才进行连接。这样就节省了在Shuffle阶段时要进行的大量数据传输。从而起到了优化作业的作用。
Map Join原理:
原理是等同于Spark的broadcast join,即把小表作为一个完整的驱动表来进行join操作。
通常情况下,要连接的各个表里面的数据会分布在不同的Map中进行处理。即同一个Key对应的Value可能存在不同的Map中。这样就必须等到 Reduce中去连接。要使MapJoin能够顺利进行,那就必须满足这样的条件:
除了一份表的数据分布在不同的Map中外,其他连接的表的数据必须在每 个Map中有完整的拷贝。Map Join会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配 (这时可以使用Distributed Cache将小表分发到各个节点上,以供Mapper加载使用),由于在map时进行了join操作,省去了reduce运行的效率也会高很多。
对于broadcast join模式,会将小于spark.sql.autoBroadcastJoinThreshold值(默认为10M)的表广播到其他计算节点,不走shuffle过程,所以会更加高效。
Map Join适用场景:
Map Join的适用场景如关联操作中有一张表非常小,不等值的链接操作。通过上面分析你会发现,并不是所有的场景都适合用MapJoin. 它通常会用在如下的一些情景:在二个要连接的表中,有一个很大,有一个很小,这个小表可以存放在内存中而不影响性能。这样我们就把小表文件复制到每一个Map任务的本地,再让Map把文件读到内存中待用。
Map Join实现方法
- 在Map-Reduce的驱动程序中使用静态方法DistributedCache.addCacheFile()增加要拷贝的小表文件。 JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
- 在Map类的setup方法中使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
hive中常见的数据类型
Hive支持两种数据类型,一类是基本数据类型,一类是复杂数据类型
1 基本数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| tinyint | 1个字节(8位)有符号整数 | 1 |
| smallint | 2字节(16位)有符号整数 | 1 |
| int | 4字节(32位)有符号整数 | 1 |
| bigint | 8字节(64位)有符号整数 | 1 |
| float | 4字节(32位)单精度浮点数 | 1.0 |
| double | 8字节(64位)双精度浮点数 | 1.0 |
| boolean | true/false | true |
| string | 字符串 | ‘haha’ |
2 复杂数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| array | 一组有序字段。字段的类型必须相同 | Array(1,2) |
| map | 一组无序的键/值对。键的类型必须是原子的,值可以是任何类型,同一个映射的键的类型必须相同,值得类型也必须相同 | Map(‘a’,1,‘b’,2) |
| struct | 一组命名的字段。字段类型可以不同 | Struct(‘a’,1,2,3) |
将一个hive表导入到另外一个hive表中有几种方式
-
从本地文件系统导入
load data local inpath ‘wyp.txt’ into table wyp;
-
从HDFS中导入
load data inpath ‘/home/wyp/add.txt’ into table wyp;
-
已有表,从别的表中查询出相关的数据导入
insert into table test partition (age=‘25’) select id, name, tel from wyp;
-
创表时通过从别的表中查询到的记录插入到创建的表中
create table test4 as select id, name, tel from wyp;
如何了解一个hive表的数据容量?
单位为Byte:hadoop fs -ls /user/hive/warehouse/weblog.db/dataclear|awk -F ’ ’ ‘{print $5}’|awk ‘{a+=$1}END{print a}’
列出文件数目:hadoop fs -ls /user/hive/warehouse/weblog.db/dataclear|wc -l (结果=实际数量+1)
如果是分区表,如何查看指定分区的数据位置?
- 确认某个表的分区信息:SHOW PARTITIONS employee;
- 查看分区信息:select * from employee where age=‘20’;
hive的建表语句
内部表:create table student(id int, name string) row format delimited fields terminated by ‘\t’;
外部表:create external table student(id int, name string) row format delimited fields terminated by ‘\t’;
分区表:create external table student(id num, name string) partitioned by (gender string) row format delimited fields terminated by ‘\t’;
分桶表:created table student(id num,name string) clustered by (name) into 3 buckets row format delimited fields terminated by ‘\t’;
hive如何存储数据
Hive中数据存储的位置,元数据(即对数据的描述,包括表,表的列及其它各种属性)是存储在MySQL等数据库中的,因为这些数据要不断的更新,修改,不适合存储在HDFS中。而真正的数据是存储在HDFS中,这样更有利于对数据做分布式运算。
hive怎样实现分页查询?
hive内的limit函数仅能作为数据条数的限制,但是支持between and 函数,为了每次都能根据条件查询到固定数量的数,可以为表格增加一行自增的id,用between查询。因为这种查询对于海量数据来说还有点麻烦,所以在程序设计时要尽量减少分页场景。
Hive表关联查询,如何解决数据倾斜问题?
1 调节参数:hive> hive.groupby.skewindata = true 启动两个job完成工作
2 大小表join:采用mapJoin将较小表(数据量少、数据key集中)放到内存,省去reduce工作,提升效率
3 大大表join:将大表中用于匹配的空值和0值赋予固定字符+随机数字,分散操作
4 count(distinct x):用sum x group by替代
5 distinct count :
Hive分区表有什么作用?
物理逻辑上,分区表是在表的文件夹下再创建分区对应的文件夹,将表中的数据按照分区字段分放在不同的分区文件夹下,这样之后按照分区字段查询数据时,可以直接找到分区文件夹得到数据,而不用在全部数据中进行过滤,从而提升了查询的效率。
Hive的条件判断有几种?
条件判断有4种模式:
| 函数 | 说明 |
|---|---|
| if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 判断是否满足条件,如果满足返回一个值,如果不满足则返回另一个值。 |
| COALESCE(T v1, T v2, …) | 返回一组数据中,第一个不为NULL的值,如果均为NULL,返回NULL。 |
| CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | 当a=b时,返回c;当a=d时,返回e,否则返回f。 |
| CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 当值为a时返回b,当值为c时返回d。否则返回e。 |