活动地址:CSDN21天学习挑战赛
目录
前言
经过前段时间研究,从LeNet-5手写数字入门到最近研究的一篇天气识别。我想干一票大的,因为我本身从事的就是C++/Qt开发,对Qt还是比较熟悉,所以我想实现一个基于Qt的界面化的一个人脸识别。
对卷积神经网络的概念比较陌生的可以看一看这篇文章:卷积实际上是干了什么
想了解神经网络的训练流程、或者环境搭建的可以看这篇文章:环境搭建与训练流程
如果想学习本项目请先去看第一篇:基于卷积神经网络(tensorflow)的人脸识别项目(一)
第二篇:基于卷积神经网络(tensorflow)的人脸识别项目(二)
基本思路
具体步骤如下:
- 首先需要收集数据,我的想法是通过OpenCV调用摄像头进行收集人脸照片。
- 然后进行预处理,主要是对数据集分类,训练集、验证集、测试集。
- 开始训练模型,提前创建好标签键值对。
- 测试人脸识别效果,通过OpenCV捕获人脸照片然后对图片进行预处理最后传入模型中,然后将识别的结果通过文字的形式打印在屏幕上,以此循环,直到输入q退出。
本篇主要是对上述步骤中的第三步进行实现。
激活函数
由于神经网络每一层的I/O全是线形求合的全过程,只要我们对它的上一层进行一系列的线性变换,就可以成功的求出下一层所要输出的东西。如果没有激活函数,无论你搭建的神经网络多么复杂,无论是几层,最后输出全是键入的线性组合,因此单纯的线性组合不可以处理更繁杂的问题。引入激活函数后,你就会发现一般的激活函数全是非线性,因而,根据在神经细胞中引入非线性,神经网络可以贴近非线性元素,神经网络可以运用于大量非线性模型。
Sigmoid函数
Sigmoid函数平滑易于求导;其取值范围为[0, 1]。圆周系统中解决三角函数计算问题,线性系统中解决乘法和除法问题。公式如下所示:
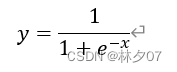
如图所示。可以应用于圆周系统、线性系统和双曲系统等,在不同的系统内解决不同的复杂计算问题。
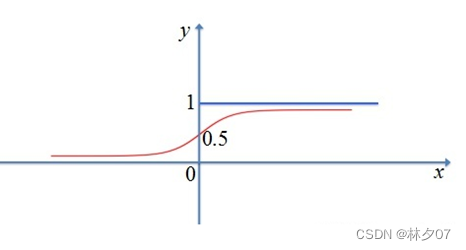
Tanh/双曲正切激活函数
它是双曲激活函数的一种,在数学语言上一般写作tanh,虽然它能够使Sigmoid函数的以0为中心输出,但梯度消失问题依旧存在。因为它的本质是,很多层进行一次次的传递,如果数据太小而层数很多,最后可能变成了零。所以在之后我们控制了函数的导数,才使这个问题得到了一定程度上的解决。
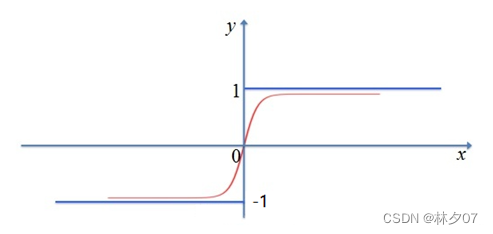
ReLU激活函数
它全名为线性整流函数,在人工神经网络中非常常见,它是一种非线性函数,通常是由斜坡函数以及它衍生出来的一系列变种。
它有很多优点,比如:只要你的输入值是一个正数,它就不会进入饱和区,而且它与其他激活函数相比,计算速度会快很多。但它有一个问题一直没有成功解决,那就是当它输入一个负数值时,此函数就会完全失效,此时的梯度会为零。当然,前面所提到的Sigmoid和tanh函数也有同样的问题。而且它还不是以0为中心的函数,这也就意味着它求导非常困难,而且需要大量的函数来支撑它。公式: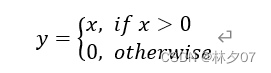
损失函数
损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
作用
损失函数使用主要是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。
建立神经网络模型
参数说明
每次都会有一堆参数,这里我先对参数进行一个介绍。
batch_size:指定每次迭代训练样本抓取的数量
nb_epoch:训练轮换次数
border_mode:卷积层的参数 选择为same,那么卷积操作的输入和输出尺寸会保持一致。如果选择valid,那卷积过后,尺寸会变小。
verbose:日志显示 0 为不在标准输出流输出日志信息 1 为输出进度条记录 2 为每个epoch输出一行记录
CNN模型
共18层,其中卷积层4个,激活层6个,池化层2个,Dropout层3个,Dense层2个,Flatten层一个。
def build_model(self, dataset, nb_classes=9):
# 构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
self.model = Sequential()
# 以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=dataset.input_shape)) # 1 2维卷积层
self.model.add(Activation('relu')) # 2 激活函数层
self.model.add(Convolution2D(32, 3, 3)) # 3 2维卷积层
self.model.add(Activation('relu')) # 4 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 5 池化层
self.model.add(Dropout(0.25)) # 6 Dropout层
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) # 7 2维卷积层
self.model.add(Activation('relu')) # 8 激活函数层
self.model.add(Convolution2D(64, 3, 3)) # 9 2维卷积层
self.model.add(Activation('relu')) # 10 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 11 池化层
self.model.add(Dropout(0.25)) # 12 Dropout层
self.model.add(Flatten()) # 13 Flatten层
self.model.add(Dense(512)) # 14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) # 15 激活函数层
self.model.add(Dropout(0.5)) # 16 Dropout层
self.model.add(Dense(nb_classes)) # 17 Dense层
self.model.add(Activation('softmax')) # 18 分类层,输出最终结果
# 输出网络结构
self.model.summary()
网络结构
下面为该神经网络的结构,总参数量6M。
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 64, 64, 32) 896
_________________________________________________________________
activation_1 (Activation) (None, 64, 64, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 62, 62, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 62, 62, 32) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 31, 31, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 31, 31, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 31, 31, 64) 18496
_________________________________________________________________
activation_3 (Activation) (None, 31, 31, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 29, 29, 64) 36928
_________________________________________________________________
activation_4 (Activation) (None, 29, 29, 64) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 14, 14, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 6423040
_________________________________________________________________
activation_5 (Activation) (None, 512) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 5130
_________________________________________________________________
activation_6 (Activation) (None, 10) 0
=================================================================
Total params: 6,493,738
Trainable params: 6,493,738
Non-trainable params: 0
训练模型
不懂就看代码中的注释哦。
def train(self, dataset, batch_size=20, nb_epoch=10, data_augmentation=True):
# 参数batch_size的作用即在于此,其指定每次迭代训练样本的数量
# nb_epoch 训练轮换次数
sgd = SGD(lr=0.01, decay=1e-6,
momentum=0.9, nesterov=True) # 采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy']) # 完成实际的模型配置工作
# 不使用数据提升,所谓的提升就是从我们提供的训练数据中利用旋转、翻转、加噪声等方法创造新的
# 训练数据,有意识的提升训练数据规模,增加模型训练量
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size=batch_size,
nb_epoch=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels),
shuffle=True,
verbose = 1)
# 使用实时数据提升
else:
# 定义数据生成器用于数据提升,其返回一个生成器对象datagen,datagen每被调用一
# 次其生成一组数据(顺序生成),节省内存,其实就是python的数据生成器
datagen = ImageDataGenerator(
featurewise_center=False, # 是否使输入数据去中心化(均值为0),
samplewise_center=False, # 是否使输入数据的每个样本均值为0
featurewise_std_normalization=False, # 是否数据标准化(输入数据除以数据集的标准差)
samplewise_std_normalization=False, # 是否将每个样本数据除以自身的标准差
zca_whitening=False, # 是否对输入数据施以ZCA白化
rotation_range=20, # 数据提升时图片随机转动的角度(范围为0~180)
width_shift_range=0.2, # 数据提升时图片水平偏移的幅度(单位为图片宽度的占比,0~1之间的浮点数)
height_shift_range=0.2, # 同上,只不过这里是垂直
horizontal_flip=True, # 是否进行随机水平翻转
vertical_flip=False) # 是否进行随机垂直翻转
# 计算整个训练样本集的数量以用于特征值归一化、ZCA白化等处理
datagen.fit(dataset.train_images)
# 利用生成器开始训练模型
self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels,
batch_size=batch_size),
samples_per_epoch=dataset.train_images.shape[0],
nb_epoch=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels),
verbose = 1)
训练结果
最后识别效果也达到了99.28%。
Epoch 1/10
- 45s - loss: 1.5003 - accuracy: 0.4488 - val_loss: 0.2484 - val_accuracy: 0.9661
Epoch 2/10
- 45s - loss: 0.5669 - accuracy: 0.8032 - val_loss: 0.1429 - val_accuracy: 0.9331
Epoch 3/10
- 46s - loss: 0.3572 - accuracy: 0.8778 - val_loss: 0.3107 - val_accuracy: 0.8703
Epoch 4/10
- 45s - loss: 0.2577 - accuracy: 0.9139 - val_loss: 0.0277 - val_accuracy: 0.9940
Epoch 5/10
- 46s - loss: 0.2046 - accuracy: 0.9350 - val_loss: 0.0275 - val_accuracy: 0.9940
Epoch 6/10
- 45s - loss: 0.1824 - accuracy: 0.9400 - val_loss: 0.0242 - val_accuracy: 0.9930
Epoch 7/10
- 46s - loss: 0.1512 - accuracy: 0.9473 - val_loss: 0.1970 - val_accuracy: 0.9341
Epoch 8/10
- 46s - loss: 0.1426 - accuracy: 0.9541 - val_loss: 0.0149 - val_accuracy: 0.9960
Epoch 9/10
- 46s - loss: 0.1474 - accuracy: 0.9541 - val_loss: 0.0391 - val_accuracy: 0.9930
Epoch 10/10
- 45s - loss: 0.1103 - accuracy: 0.9666 - val_loss: 0.0133 - val_accuracy: 0.9928
评估模型
用于确认模型的精度是否能达到要求。
加载模型
def load_model(self, file_path=MODEL_PATH):
self.model = load_model(file_path)
评估测试
def evaluate(self, dataset):
score = self.model.evaluate(dataset.test_images, dataset.test_labels, verbose=1)
print("%s: %.2f%%" % (self.model.metrics_names[1], score[1] * 100))
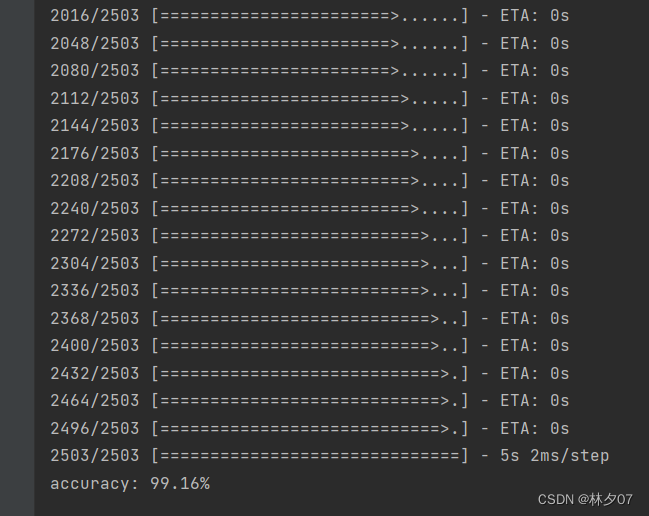
测试结果
正确率99.16%。
总结
本章节 主要的难度在于模型的设计上,一直需要微调模型。再就是需要了解一些什么是损失函数、激活函数等等一些概念性东西。