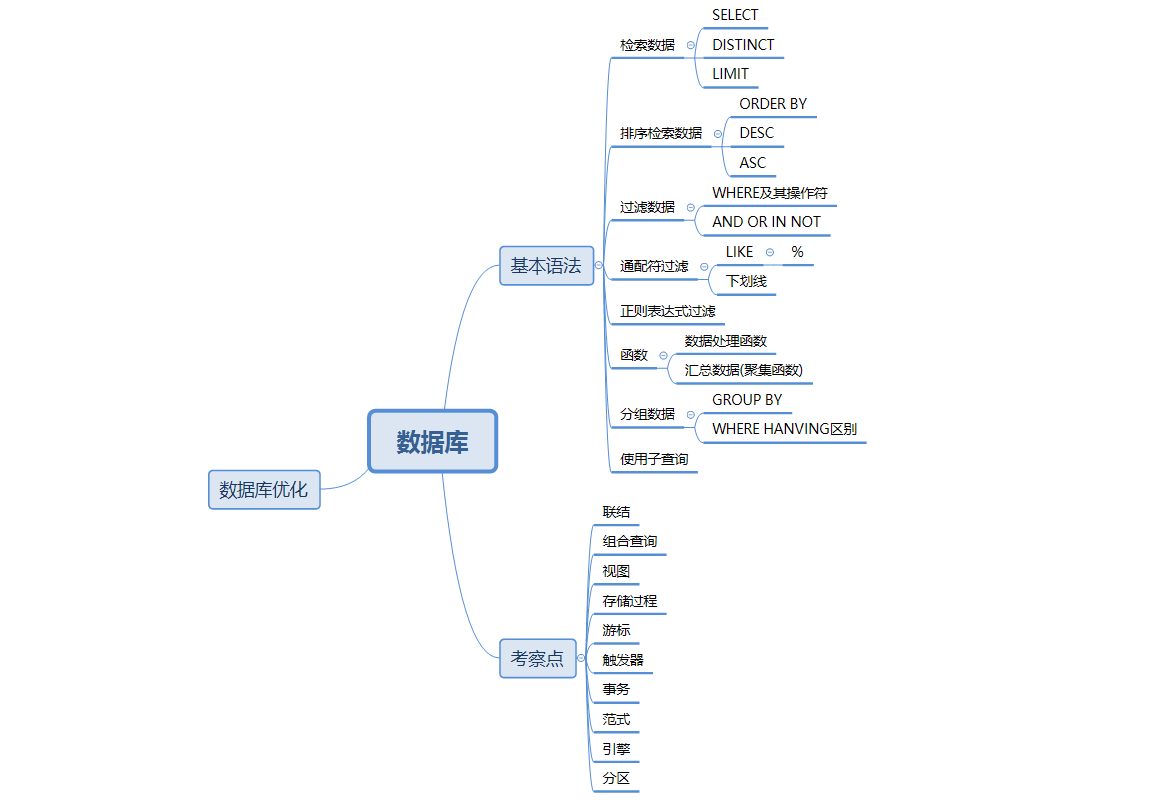
一、考察点
1.联结
1.1 联结的概念:
简单的说,联结是一种机制,用来在一条SELECT语句中关联表,因此称之为联结。
1.2 联结的分类
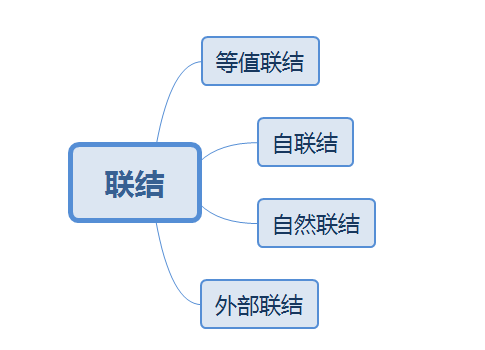
注意:联结并不代表只有使用join关键字的才算是联结,where也算是联结的一种实现方式。
1.2.1内部联结
内部联结也成为等值联结,它基于两个表之间的相等测试,基本实现方式由以下两种格式:
1.SELECT name,price FROM 表1 INNER JOIN 表2 ON 表1.id = 表2.id
2.SELECT name,price FROM 表1,表2 WHERE 表1.id = 表2.id
1.2.2 自联结
自联结的使用情形是在同一张表中进行查询,自联结通常作为外部语句用来替代从相同表中检索数据时使用的子查询语句。虽然最终结果是相同的,但有时候处理联结远比处理子查询快得多。
1.select id,name from 表1 where id = (select id from products where id = ‘DTNTR’)(子查询方式)
2.select p1.id,p1.name from products as p1, products as p2 where p1.id = p2.id and p2.id = 'DTNTR'(自联结方式)
1.2.3 自然联结
当对表进行联结时,可能会出现一个列出现在不止一个表中,标准的联结返回所有数据,甚至相同的列多次出现。自然联结排除多次出现,使得每个列只返回一次。
实现方法:一般是通过对表使用通配符,对所有其他表的列使用明确的子集完成的(个人理解是使用全限定表明)。
1.2.4 外部联结
许多联结将一个表中的行与另一个表中的行相关联,但有时候会需要包含没有关联行的那些行,包含了那些在相关表中没有关联行的行,这种联结称为外部联结
外部联结的类型:外部联结存在两种基本类型:左外部联结和右外部联结,他们之间的唯一差别是所关联的表的顺序不同
外部联结的实现:使用OUTER JOIN来实现,细分为两种格式: 1.
右外联结:A right outer join B 实现效果:选中右表中的所有行
左外联结:A left outer join B 实现效果:选中左表中的所有行
2.视图
概念:视图是虚拟的表,个人理解是:访问频次最高的不是整个表,而是表中经过某些条件筛选出来的结果集,而将这些数据使用视图的方式创建后,首先提高了访问的速度,因为不再需要查询全表了,只需要在视图的结果集上操作即可,另一方面大大简化了SQL书写的复杂度,避免了子查询等实现方式带来的冗余查询时间了。
视图的基本操作:
创建:CREAT VIEW AS +SELECT语句 =>视图中即存储了SELECT语句查询出来的结果集
使用:使用视图名访问,与表的使用相同
删除:DROP VIEW viewname
注意:视图中的数据能否更新?答案视情况而定,其实对视图增加或者删除行,实际上是对基表增加行或者删除行。视图中有定义以下操作,则不能进行更新,比如联结,子查询,并等等。
3.存储过程
概念:简答来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。
优点:简单、安全、高性能。简单:不再需要反复建立一系列的处理步骤,简化了复杂的操作,类似封装,但是存储过程的编写比基本SQL要复杂得多。安全:减少了其他原因对数据的错误修改。高性能:查找速度块。
建立:CREATE PROCEDURE productpricing(OUT A1,IN A2)
BEGIN
SQL CODE
INTO
END
调用:call productpricing(@参数1(输出变量名),2000(传入数据))
删除: drop 名字
4.游标
概念:当我们需要在检索出来的行中前进或者后退一行,就需要使用游标了。游标是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。
注意:游标只能用于存储过程和函数
使用步骤:
1.声明游标 DECLARE 游标名 CURSOR
2.打开投标 OPEN
3.使用循环或判断语句等结合FETCH对检索的结果集操作,根据需求可存进不同的变量中返回
4.关闭游标 CLOSE
5.触发器
概念:触发器是MySQL相应DELETE,INSERT,UPDATE时自动执行的一条MySQL语句(或位于BEGIN和END之间的一组语句)
创建触发器需要给出四条信息:唯一触发器名、触发器关联的表、应该响应的活动(delete/insert /update)、触发器何时执行(处理之前或之后)
eg:CREATE TRIGGER 触发器名 AFTER INSERT ON 表名
FOR EACH ROW 触发操作
6.事务
关于事务的几个术语:
事务:指一组SQL语句
回退:撤销指定SQL语句的过程
提交:将未存储的SQL语句结果写入数据库表
保留点:指事务处理中设置的临时占位符,可以对它发布或回退
7.范式
首先三范式是关系型数据库的设计规范,为了保持数据完整性的同时最小化数据冗余。各种范式呈递次规范(即第一范式是第二范式的基础,第二范式是第三范式的基础),越高的范式数据库冗余越小,但实际情况应该根据当时场景、需求、模型等来决定。
1)第一范式(1NF)
每个属性(每个列值)具有原子性,不可再分。即表中的每一行只包含一个实体的信息,而每一行的每一列只能存放实体的一个属性。
例:学号 姓名 性别 班级
201202031078 梁子轩 男 12级2班
以上违反1NF,班级这一列可拆为:
学号 姓名 性别 年级 班级
201202031078 梁子轩 男 12级 2班
2)第二范式(2NF)
在1NF的基础上,实体的属性完全依赖主关键字(主键),即不能存在仅依赖主关键字的一部分属性。
例:表A: 主键 属性
员工编号、岗位 →(决定)→ 姓名、年龄、学历、基本工资
以上违反2NF,关系可拆为两个表:
表B:员工编号 →(决定)→ 姓名、年龄、学历
表C:岗位 →(决定)→ 基本工资
3)第三范式(3NF)
在2NF的基础上,任何非主属性不依赖于其他非主属性(消除传递函数依赖)。所谓传递函数依赖,就是关键字段A决定非关键字段B,非关键字段B决定非关键字段C,则非关键字段C传递函数依赖于关键字段A。
例:员工编号 →(决定)→ 姓名、年龄、部门编号、部门经理
以上满足2NF,但违反了3NF,因为存在以下传递函数依赖,
员工编号 →(决定)→ 部门编号 →(决定)→ 部门经理
可拆分为以下两种关系(表):
A:员工编号 →(决定)→ 姓名、年龄、部门编号
B:部门编号 →(决定)→ 部门经理
8.引擎
9.分区