import torch.nn as nn
import torch.nn.functional as F
import torch
import torchtext
from torchtext.legacy.data import Field, NestedField, LabelField, TabularDataset, BucketIterator
# from torchtext import data
from torchtext import datasets
from torchtext import vocab
import spacy
import pkuseg
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torchtext预处理流程
- 定义Field:声明如何处理数据;
- Field,定义一个接收要求,或者说是处理条件。用于处理文本数据。
- 定义Dataset:得到数据集,此时数据集里每一个样本是一个经过Field声明的预处理后的 wordlist;
- TabularDataset,接受的数据集,就是pytorch中Dataset翻版,不过里面定义了一些文本处理操作,然后存储数据。相比自定义的Dataset而言,TabularDataset里一些预定义功能省去我们nlp中文本处理时间,但有些时候不如Dataset灵活。
- 建立vocab:在这一步建立词汇表,词向量(word embeddings);
- Field().build_vocab()
- 构造迭代器:构造迭代器,用来分批次训练模型;
- BucketIterator,是pytorch中DataLoader翻版,可以进行批次训练。
下面来看具体代码,假数据如下:
train_demo.jsonl
{"idx": "1", "text": "东5环海棠公社230-290平2居准现房98折优惠", "label": 0}
{"idx": "2", "text": "海淀区领秀新硅谷宽景大宅预计10月底开盘", "label": 0}
{"idx": "3", "text": "柴志坤:土地供应量不断从紧 地价难现07水平(图)", "label": 0}
{"idx": "4", "text": "融景城2010年中期将推2居80-90平16000起(图)", "label": 0}
{"idx": "5", "text": "燕京航城形象代言人正式签约李小璐", "label": 0}
{"idx": "6", "text": "朝阳苹果派10-70平地下室均价13000元", "label": 0}
{"idx": "7", "text": "密云檀府家园125平米3居在售均价7千全款98折", "label": 0}
{"idx": "8", "text": "昌平准现房湾流汇推出双拼及独栋别墅16500元起", "label": 0}
{"idx": "9", "text": "东5环海棠公社170平3居26000元别墅600万起", "label": 0}
{"idx": "10", "text": "华侨城46亿开建武汉巴登城", "label": 0}
{"idx": "11", "text": "金证顾问:过山车行情意味着什么", "label": 1}
{"idx": "12", "text": "美股评论:科技行业财测消失为哪般", "label": 1}
{"idx": "13", "text": "美国保级三缺一:看标普脸色", "label": 1}
{"idx": "14", "text": "三新股今日上市 赣锋锂业大涨194.2%居首", "label": 1}
{"idx": "15", "text": "欧洲三大股市上升 英国股市升0.08%", "label": 1}
{"idx": "16", "text": "港交所推出中移动等5股票期权标准组合交易", "label": 1}
{"idx": "17", "text": "申银万国:上调准备金符合预期 对股市影响不大", "label": 1}
{"idx": "18", "text": "奥巴马将考虑签署短期调高借债上限协议", "label": 1}
{"idx": "19", "text": "世界经济靠什么避免大灾难", "label": 1}
{"idx": "20", "text": "国都香港:预测光汇石油中报盈利增长82%", "label": 1}
{"idx": "21", "text": "中华女子学院:本科层次仅1专业招男生", "label": 2}
{"idx": "22", "text": "北京考生需注意:英语考试14:45禁入场", "label": 2}
{"idx": "23", "text": "教育部通报一起涉嫌虚假招生宣传案件", "label": 2}
{"idx": "24", "text": "北京9场校园高招咨询会周末举行", "label": 2}
{"idx": "25", "text": "2010年高考文综试题(浙江卷)", "label": 2}
{"idx": "26", "text": "广西2010年成考报名时间及办法", "label": 2}
{"idx": "27", "text": "四六级19日开考 有学生为得高分多次报考", "label": 2}
{"idx": "28", "text": "2011年成考期间网上监控有害信息", "label": 2}
{"idx": "29", "text": "贴近生活 计算房价折扣成了中考试题", "label": 2}
{"idx": "30", "text": "自考故事:不走寻常路 自考毕业1年当老板", "label": 2}
{"idx": "31", "text": "大学生应征忙 征兵要求素质逐步提高(图)", "label": 2}
{"idx": "32", "text": "两天价网站背后重重迷雾:做个网站究竟要多少钱", "label": 3}
{"idx": "33", "text": "出色卡片!佳能IXUS 115竟不到1400元", "label": 3}
{"idx": "34", "text": "山东旅游局联手携程邀网友答问题赢礼品", "label": 3}
{"idx": "35", "text": "多款Windows Phone7手机现身台北电脑展", "label": 3}
{"idx": "36", "text": "儿童摄影团购遭遇“选片圈套”", "label": 3}
{"idx": "37", "text": "卖点一览无余 超低价热销平板电视导购", "label": 3}
{"idx": "38", "text": "17英寸游戏强本 华硕X71独显现售7795", "label": 3}
{"idx": "39", "text": "德国眼镜熊患皮疹全身脱毛变裸体熊(组图)", "label": 3}
{"idx": "40", "text": "细节显品质 热门全能型实用本本推荐", "label": 3}
{"idx": "41", "text": "前程无忧周四大跌19.97%创52周新低", "label": 3}
{"idx": "42", "text": "82岁老太为学生做饭扫地44年获授港大荣誉院士", "label": 4}
{"idx": "43", "text": "妻子照顾植物人丈夫6年教会其吃饭(图)", "label": 4}
{"idx": "44", "text": "饭店因物价上涨无法定菜价 订年夜饭改收餐位费", "label": 4}
{"idx": "45", "text": "少年患进行性肌肉萎缩11年考上大学(图)", "label": 4}
{"idx": "46", "text": "百余名英国母亲参加快闪活动当众喂奶(图)", "label": 4}
定义Field
Torchtext采用了一种声明式的方法来加载数据:你来告诉Torchtext你希望的数据是什么样子的,剩下的由torchtext来处理。
实现这种声明的是Field,Field确定了一种你想要怎么去处理数据:
data.Field(…)
常用参数如下:
- tokenize:传入一个函数,表示如何将文本str变成token
- lower:是否将此字段中的文本小写。默认值:False
- include_lengths:是否返回填充小批量的元组和包含的列表
- fix_length:使用此字段的所有示例都将被填充到的固定长度,或 None 用于灵活的序列长度。默认值:None。
- tokenizer_language:要构造的标记器的语言。目前仅在 SpaCy 中支持的各种语言。
- use_vocab:表示是否使用词典对象,用在要分词的语料内容上。后续将对应词转化为词向量需要。
- sequential:表示是否展示成序列,用在要分词的语料内容上。
数据类型是否表示顺序数据,如果数据已经是序列化的了而且是数字类型的,则应该传递参数use_vocab = False和sequential = False
field在默认的情况下都期望一个输入是一组单词的序列,并且将单词映射成整数。这个映射被称为vocab。如果一个field已经被数字化了并且不需要被序列化, - pad_token:用作填充的字符串标记,Default: “”
- unk_token:用于表示 OOV 词的字符串标记,Default: “”
# 定义分词函数,采用北大的pkuseg
seg = pkuseg.pkuseg()
def tokenizer(text):
return seg.cut(text)
# word_field = Field(tokenize='spacy', lower=True, include_lengths=True, fix_length=32, tokenizer_language='en_core_web_sm')
word_field = Field(tokenize=tokenizer, lower=True, include_lengths=True, fix_length=32, tokenizer_language='en_core_web_sm')
label_field = Field(sequential=False, use_vocab=False)
定义Dataset
Field知道当给定原始数据的时候要做什么。现在,我们需要告诉fields它需要处理什么样的数据。这个功能利用Datasets来实现。
TabularDataset官网介绍: Defines a Dataset of columns stored in CSV, TSV, or JSON format.
fields = {
'text': ('text_word', word_field),
'label': ('label', label_field)
}
train, val = TabularDataset.splits(path='./data/THUCNews', train='train_demo.jsonl', validation='val_demo.jsonl', format='json', skip_header=True, fields=fields)
# train, val = TabularDataset.splits(path='./data/THUCNews', train='train_demo.tsv', validation='val_demo.tsv', format='tsv', skip_header=True, fields=fields)
print(train[5])
print(train[5].__dict__.keys())
print(train[5].text_word, train[5].label)
print()
<torchtext.legacy.data.example.Example object at 0x7fe0581e6340>
dict_keys(['text_word', 'label'])
['密云', '檀府', '家园', '125', '平米', '3', '居', '在', '售均价', '7千', '全款', '98', '折'] 0
建立vocab
上面打印的,我们可以看到第6行的输入,它是一个Example对象。Example对象绑定了一行中的所有属性,句子已经被分词了,但是没有转化为数字。
扫描二维码关注公众号,回复:
14521286 查看本文章

这是因为我们还没有建立vocab,我们将在下一步建立vocab。
Torchtext可以将词转化为数字,但是它需要被告知需要被处理的全部范围的词。
‘glove.840B.300d’ 为torchtext支持的词向量名字,第一次使用是会自动下载并保存在当前目录的 tmp_cache里面。
torchtext支持的词向量:
charngram.100d
fasttext.en.300d
fasttext.simple.300d
glove.42B.300d
glove.840B.300d
glove.twitter.27B.25d
glove.twitter.27B.50d
glove.twitter.27B.100d
glove.twitter.27B.200d
glove.6B.50d
glove.6B.100d
glove.6B.200d
glove.6B.300d
word_vectors = vocab.Vectors('./data/glove/glove.840B.300d.txt', './data/glove/tmp_cache')
print('glove.840B.300d维度:', word_vectors.vectors.shape)
# glove.840B.300d维度: torch.Size([2196017, 300])
下面这行代码使得 Torchtext遍历训练集中的绑定word_field的数据,将单词注册到vocabulary,并自动构建embedding矩阵
min_freq表示最短词频,低于其的词语不会进行训练
# word_field.build_vocab(train, val, max_size=25000, vectors=word_vectors, min_freq=1, unk_init=torch.Tensor.normal_)
word_field.build_vocab(train, val, max_size=25000, vectors=word_vectors, min_freq=1, unk_init=torch.nn.init.xavier_uniform)
到这一步,我们已经可以把词转为数字,数字转为词,词转为词向量了:
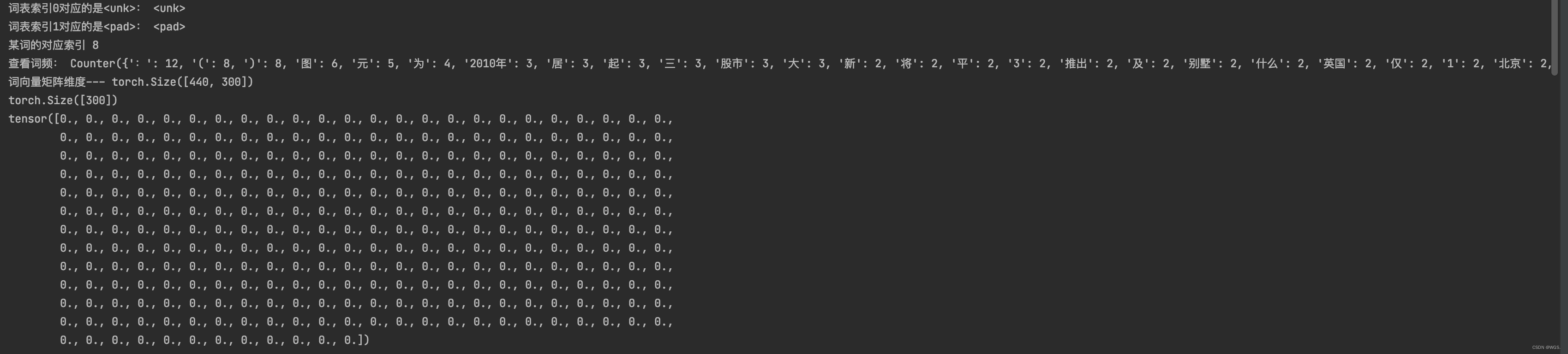
print('词表索引0对应的是<unk>:', word_field.vocab.itos[0])
print('词表索引1对应的是<pad>:', word_field.vocab.itos[1])
# word 到 id 的映射
print('某词的对应索引', word_field.vocab.stoi['2010年'])
print('查看词频:', word_field.vocab.freqs)
# 词向量矩阵: TEXT.vocab.vectors
print('词向量矩阵维度---', word_field.vocab.vectors.shape)
word_vec = word_field.vocab.vectors[word_field.vocab.stoi['2010年']]
print(word_vec.shape)
print(word_vec)
print()
构造迭代器
和Dataset一样,torchtext有大量内置的迭代器,我们这里选择的是BucketIterator,官网对它的介绍如下:
- Defines an iterator that batches examples of similar lengths together.
- Minimizes amount of padding needed while producing freshly shuffled batches for each new epoch.
train_iter, dev_iter = BucketIterator.splits(
(train, val), batch_sizes=(3, len(val)), sort_key=lambda x: len(x.text_word),
sort_within_batch=True, repeat=False, shuffle=True, device=device
)
woed_embeddings = word_field.vocab.vectors
emb = nn.Embedding.from_pretrained(woed_embeddings, freeze=False)
for batch, batch_data in enumerate(train_iter):
text_word, y = batch_data.text_word, batch_data.label
print(text_word)
print(y)
print(text_word[0].shape) # [seq_len, batch_size]
x = text_word[0].permute(1, 0)
print(x)
print(x.shape) # [batch_size, seq_len]
# embedding
x = emb(x)
print(x)
print(x.shape)
break
(tensor([[141, 171, 188],
[266, 434, 29],
[160, 2, 365],
[ 10, 429, 347],
[402, 126, 334],
[ 55, 335, 393],
[138, 105, 122],
[ 67, 330, 95],
[159, 178, 148],
[261, 75, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1],
[ 1, 1, 1]]), tensor([10, 10, 9]))
tensor([3, 1, 1])
torch.Size([32, 3])
tensor([[141, 266, 160, 10, 402, 55, 138, 67, 159, 261, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1],
[171, 434, 2, 429, 126, 335, 105, 330, 178, 75, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1],
[188, 29, 365, 347, 334, 393, 122, 95, 148, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1]])
torch.Size([3, 32])
tensor([[[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
[[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[-0.0042, 0.3527, -0.3186, ..., 0.0935, 0.0106, 0.1928],
...,
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
[[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
grad_fn=<EmbeddingBackward>)
torch.Size([3, 32, 300])