分类与监督学习
现实中,我们经常会遇到这样的问题:银行收到用户的信用卡申请表。当然,这是一张带有用户丰富信息的申请表,比如年龄,学历,收入,信用记录等等。那么银行的工作人员如何根据这些信息判别这个用户是否是诚信的,是否应该通过他的信用卡申请呢?人工的判断显然耗时耗力,且不一定准确,比较靠谱的办法是通过已有的,大量用户的使用记录,分析得到一个模型(或一个方程,一种工具),利用这个模型,可以判别出大量用户属性与用户是否诚信的关联关系。从而用一种科学的计算方式,得到一个相对准确的判断。而获得这种模型的方法,就是分类问题的核心。
形式化的,分类是这样一种数据分析的形式:现在有大量的数据对象,构成了一个数据集,数据集用
- 通过对已有类标号的数据集(也称为“训练集”)进行学习,构建分类器;
- 利用分类器,对未分类的数据(也称为“测试集”)分类;
我们工作的核心,在于使用某种算法,通过大量的训练集,“学习”出一种分类器。之后,通过分类器,对新的未分类的数据做分类预测。这里插一句闲话,预测问题大致上分为两类:
- 数值预测。比如商店通过顾客信息预测他大概能消费多少钱,这涉及到了具体的数值,常见的方法有“回归分析”。
- 分类。常见的方法有今天要说的决策树,朴素贝叶斯等等
信用卡的例子中,一旦完成了这种分类器的学习,就可以根据新用户的属性处理新的用户申请,做出这个用户可能“诚信”或“不诚信”的判别。可见,分类需要给出一定量的有类标号的训练集,这不同于之前我曾经提到的聚类(详见:聚类分析: k-means算法)。聚类没有类标号,完全是只有属性的原始数据,甚至连分成几类也是不确定的。而分类的过程则似乎更“靠谱”一些。这种先给出训练集的学习模式,在机器学习中也叫“监督学习”,它与聚类所代表的“无监督学习”有着本质区别。
决策树的结构
本篇博客中,我将介绍分类中最基础,也是最简单的学习过程:决策树(Decision Tree)归纳。它从有类标号的训练元组中学习得到决策树。决策树是一种树形结构,一个典型的决策树如下图所示,这张图也是《数据挖掘》中的一个例子,根据顾客信息,对是否会”buys_computer”做判别。

下面对决策树做几点说明:
每个内部节点代表一个属性上的测试,而他的每个分支代表这种属性测试的结果,比如上图中,根节点代表的就是对”age”这个属性的测试,三个分支”youth”, “middle_aged”,”senior”,分别代表测试的结果
每个叶子节点代表一个类标号,这里,只有”yes”和”no”两种,即买计算机或者不买
做分类预测时,将新的数据对象自根节点向下遍历决策树,比如现在有这样的数据对象:{age: youth; student: yes; …}无论省略号所代表的属性如何,都可以判断出,这个用户买计算机的概率很大。
需要注意的是,决策树的分类大多是对新的数据对象的类做概率性的判断,当然,也有些时候做的是确定性的判断,这需要根据具体问题做具体分析。
决策树归纳
1. 树节点
当前,主流的决策树归纳算法有三种:ID3, C4.5, CART,虽然这3种算法在细节上有所差异,但主要的思想都是自顶向下,采用贪心方法,递归地分治构造决策树。算法将整个训练集同时读入,随着构造的决策树深度的增加,训练集被每个分支分裂成更多更小的子集,在讲解具体的算法之前,先给出对一个决策树节点类的定义,如下:(注意:本文所有函数及类的定义均用Python实现)
class DecisionTreeNode(object):
def __init__(self):
# tag is the class name
self.tag = None
self.isLeaf = True
# pointers is a dictionary, {attributeValue: child, ...}
self.pointers = {}
# the best attribute that used to split dataset
self.splitCriterion = None我们设定一个决策树节点应该有上面所示的四个属性,下面具体说一下:
splitCriterion:分裂准则。即这个节点是按照哪个属性对数据集划分的,比如上面图中根节点的分裂准则是”age”。splitCriterion是只有内部节点才拥有的属性,叶子节点的splitCriterion设为None;
tag:叶子节点所对应的类标号,比如上图中,从左至右,叶子节点的tag值分别为”no”,”yes”,”yes”,”no”,”yes”,所有内部节点的tag值为None
isLeaf:节点是否为叶子,是叶子,设为True;不是,设为False
pointers:内部节点的指针集合。在后面的代码实现中,我将pointers以字典的形式表示,这个字典的键值对为{attribute_value: child, …},表示内部节点的每个孩子是有分裂准则下的哪个属性值分裂而成的,比如上图中,根节点的pointers为{“youth”: 最左的孩子, “middle_aged”: 中间的孩子, “senior”: 最右的孩子}。这样设计的目的是为了决策树生成之后,方便于对新的数据分类。
2. 学习步骤
决策树构造的步骤如下:
输入:数据集(每个数据对象都有一个或多个属性);属性列表(所有出现在数据集中的属性)
输出:一棵决策树
新建一个决策树节点
u 。初始时生成的节点就是决策树的根节点,根节点对应的是全体数据集。根据当前节点所对应的数据集,选择一个“最好的”属性作为数据集的分裂准则,按照这个属性的不同属性值(简单起见,这里我假设属性值都是离散的,连续的情况后面单另说),对数据进行分割。这里,所谓“最好的”属性,是指按照这个属性分割数据集之后,生成的每个数据子集都尽可能地“纯”。也就是说,最好每个子集都属于同一类(拥有相同的类标号)。
在属性列表中,删除当前使用为分裂准则的属性。
根据数据分割后的数据子集,以及删除了一个属性的属性列表,递归地执行决策树算法。新生成的决策树(实际上是子树)的根节点被
u 对应的指针指向。
当然,这里面有三种“触底”生成叶子节点的情况:
如果此时对应节点的数据集全部属于同一类C,那么此时的这个节点就是叶子节点,其tag为C;
如果此时属性列表为空,那么此时的这个节点就是叶子节点。然后采用“多数投票”的方法为这个叶子节点选择tag。即此时节点所对应的数据集中,拥有最多数据对象的类为这个叶子节点的tag;
如果此时对应节点的数据集为空,那么此时的这个节点就是叶子节点。且采用数据分割前(也就是其父亲节点)所对应的数据集中“多数投票”的结果作为其tag;
从上面的过程可以看出,这是一个思路非常清晰的递归算法。先将全体数据集读入,选择“最好的”属性,按照这个属性,对数据分割。同时,将已经“用过”的属性删除出列表,再对于每个数据子集和此时剩余的属性集合再做类似的过程。最终,遇到上面三个“触底”的条件时,形成叶子,结束这一分支的分裂过程。
这里插一句闲话,如果读者属于Kd-tree构建索引的过程(详见:Kd-tree原理与实现),会发现,决策树这种分裂的思路和Kd-tree非常类似,只不过用途上就大相近庭了:Kd-tree是为了能实现对于多维数据库的快速查询,而决策树,是在学习数据的特征和类别之间的关系。
在给出实现代码之前,先解决一个棘手的问题:怎样选择“最好的”属性作为分裂准则,让分裂的结果尽可能地“纯”呢?(其实就是构建一棵平衡或者相对平衡的决策树)这样做的目的有两个,一来, 相关文献表明平衡或者相对平衡的决策树在预测分类结果时会有更好的效果;二来,显然平衡的决策树无论是在构建还是在构建完成后对于数据分类的预测都更加高效。
目前,有三种比较主流的方法解决这个问题,这三种方法恰好也对应了上面说的三种决策树归纳的算法:1. 信息增益(ID3);2. 增益率(C4.5);3. 基尼指数(CART)。本文,我只介绍前两种方法,至于基尼指数,读者们可参考《数据挖掘》,那里面有着详细的介绍。
3. 分裂准则的选择
(1)信息增益
信息增益的基本思想来自于香农的信息理论,当中有一个非常重要的公式,就是信息熵的计算。信息熵表示的是一条消息所含信息量的多少,我这里简单说说,比如现在两条信息:
- 明天早上太阳从东边升起
- 抛掷一枚硬币,正面朝上
对于第一条消息来说,其信息量为0,因为这是必然事件,不用说,我们也知道的;但是对于事件2来说,就有点信息量了,因为发生的概率只有1/2。概率上的不确定性,才能给信息带来了信息量。此外,如果一个事件有
为了定量的刻画这种信息量的多少(计算信息熵),就出现了下面这个著名的公式:
其中,
把信息熵的概念用在决策树算法的最佳分裂准则(属性)的选择上,也能发挥作用。可以这样理解,如果按照一个属性分割数据集,那么可以针对每个数据集都按照信息熵的公式计算信息量,如果分得越“纯”,那显然每个数据子集的信息熵就越小,当然,每个子集根据其大小不同,在原数据集上占据的权重也就不同,我们可以依照下式计算出,经过属性
其中,
age有3个属性值。而
根据信息论的原理,信息的作用是消除事件的不确定性,决策树归纳中,每一次按照属性对数据集的分割,都相当于是我们借助了一些信息,最终到每个叶子节点归为了同一类,则是完成了对这种不确定性的彻底消除。所以,
显然,应该选择信息增益最大的属性作为分裂准则,这样,就能使分裂后的数据集都尽可能地“纯”。下面,我们以《数据挖掘》中的例子来说明选择最佳分裂属性的计算过程,首先我们给出数据集的形式:
| RID | student | income | age | credit_rating | class |
|---|---|---|---|---|---|
| 1 | no | high | youth | fair | no |
| 2 | no | high | youth | excellent | no |
| 3 | no | high | middle_aged | fair | yes |
| 4 | no | medium | senior | fair | yes |
| 5 | yes | low | senior | fair | yes |
| 6 | yes | low | senior | excellent | no |
| 7 | yes | low | middle_aged | excellent | yes |
| 8 | no | medium | youth | fair | no |
| 9 | yes | low | youth | fair | yes |
| 10 | yes | medium | senior | fair | yes |
| 11 | yes | medium | youth | excellent | yes |
| 12 | no | medium | middle_aged | excellent | yes |
| 13 | yes | high | middle_aged | fair | yes |
| 14 | no | low | senior | excellent | no |
按照上面的公式(1),可以先计算出整个数据集
接下来,根据公式(2),(3)分别计算以属性age,income,student,credit_rating分割数据集所产生的信息期望,以及信息增益。先看属性age的:
同理,可得:
不难发现,属性age的信息增益最大,因此,对于根节点(原始全体数据集)的分割应该首先以age为分割属性。我们就得到了下面这张图:
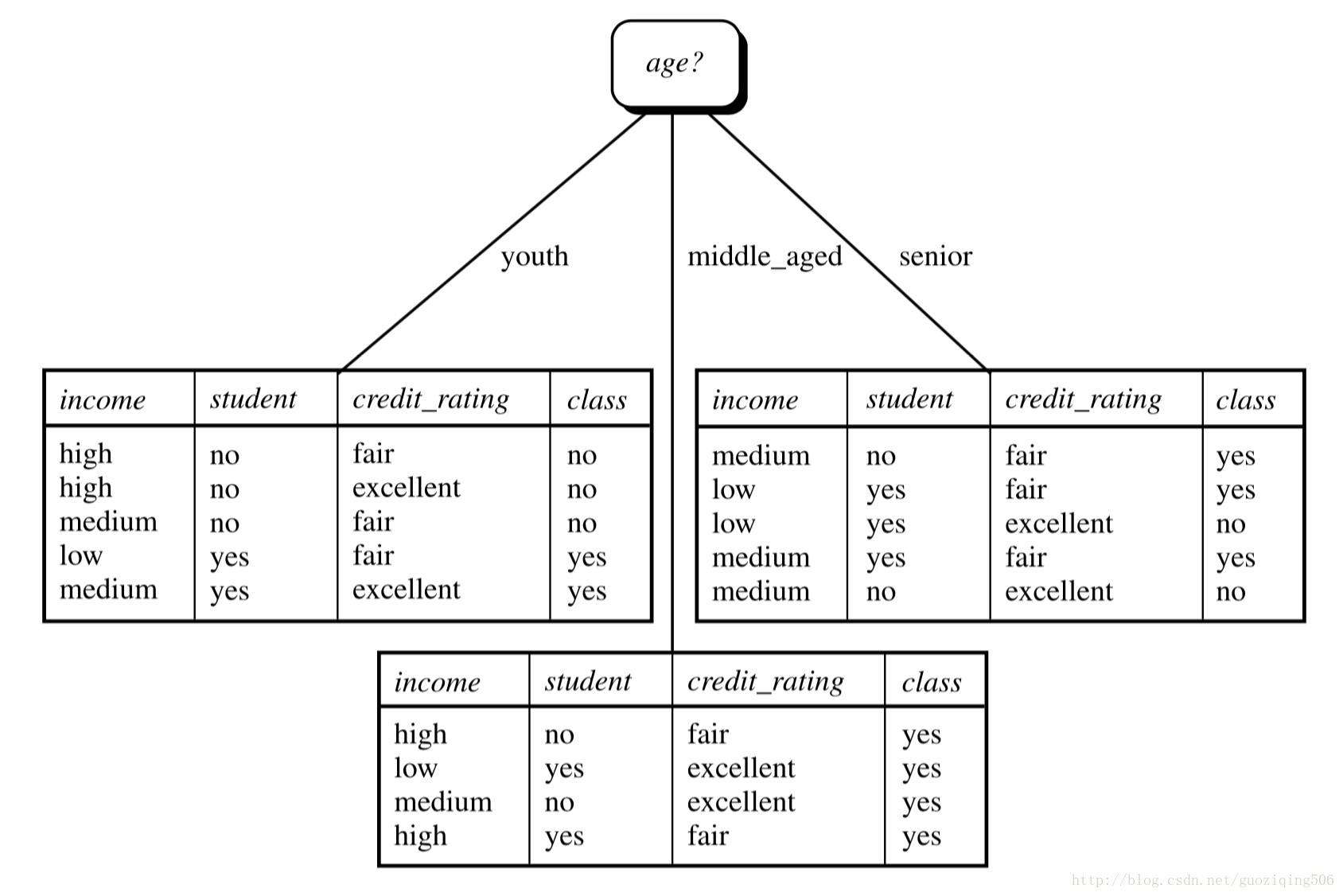
这时候,middle_aged属性值所对应的数据子集都是属于同一类,那么根据上面讲的递归的“触底”条件,这个节点直接变成叶子,并且拥有类标记tag = yes。之后,将属性age从属性列表中删除,对于此时youth所对的节点及数据子集再次进行类似的决策树学习,只不过用的数据集是age属性为youth的数据子集,且属性列表少了一个age,对于senior所对的节点及数据子集也进行这样的过程,最终得到的决策树如本文最上面的图所示。
当然,上面所展示的方法,都是应对这种最简单的离散属性值的情况,对于连续属性值的处理,会稍微复杂一点,步骤如下:
将数据集中出现的属性
A 的值按递增序排列,每个相邻值得中点看做是可能的分裂点。假设数据集中,属性A 一共出现了v 个值,那么需要比较的是这v−1 个分裂点。比较的方法是计算
InfoAD ,按照分裂点将数据集分成两部分,一部分属性A 的值大于分裂点,另一部分小于或等于分裂点。对于每个分裂点都做如此计算,找到信息增益最大的分裂点。
其实,只要解决了最佳属性的选择问题,决策树归纳算法就算是完成了一大半的工作了。我们在本文的最后给出了决策树归纳的完整代码。然而,这种信息增益的方法选择分裂属性在某些时候,也有它的问题,所以,虽然早期的ID3算法使用了信息增益技术,但是在随后更加成熟的C4.5算法中,则采用了“增益率”的方法,具体如下。
(2)增益率
使用“信息增益”的算法会面临这样一个问题,就是有些属性会导致一些毫无意义的数据分割。比如上面的例子中,我们将数据对象的属性”RID”排除在外了,如果没有排除,那么”RID”一定会是第一个最佳的分裂属性。他把大小为
首先计算分裂后的数据子集的信息量:
再计算信息增益所带来的增益率:
实际上就是一个简单的比率计算,但是却克服了之前按”RID”划分时产生的问题。
程序设计
1. 数据类型
首先,设计一下读入的数据形式。我用的是Python中的字典。将上面表格中所示的数据对象读成一个字典,再将所有的字典构成一个元组,这个元组的所有元素如下:
{'RID': '1', 'student': 'no', 'class': 'no', 'income': 'high', 'age': 'youth', 'credit_rating': 'fair'},
{'RID': '2', 'student': 'no', 'class': 'no', 'income': 'high', 'age': 'youth', 'credit_rating': 'excellent'},
{'RID': '3', 'student': 'no', 'class': 'yes', 'income': 'high', 'age': 'middle_aged', 'credit_rating': 'fair'},
...我不写全了,总之,每个数据对象被读成一个字典,数据的每个特征(包括RID和class,这两个不算数据属性)都作为键,其对应的特征值作为键对应的值。
2. 分裂准则(属性)选择
现在,根据前面说的信息增益的原理,我们将分裂属性选择的过程(select Attribute)的代码表示如下(非主要函数只是给出汉语的功能说明):
def classCount(data):
对数据集data中的数据对象做类别统计,得到一个字典{class_name: number, ...}
def getAttributeList(data):
得到数据集data的所有属性的列表
def info(data):
"""
calculate the entropy of dataset
:param data: dataset that contains data objects, is a tuple: (obj_1, ..., obj_n)
:return: the entropy of dataset
"""
classRecord = classCount(data)
n = len(data)
result = 0
for classTag in classRecord:
pi = classRecord[classTag] / n
result += (-pi * math.log(pi, 2))
return result
def infoForAttribute(dataSize, attributeValue_subset):
"""
calculate the expectation of information if we split data with the attribute
:param dataSize: the number of objects in dataset
:param attributeValue_subset: a dictionary, as form as {attributeValue_1: subset_1,... }
:return: the sum of weight x entropy
"""
result = 0
for subset in attributeValue_subset.values():
weight = len(subset) / dataSize
result += weight * info(subset)
return result
def dataPartition(data, attribute):
"""
Partitioning the data according to an attribute
:param data: dataset that contains data objects, is a tuple: (obj_1, ..., obj_n)
:param attribute: an attribute
:return: a dictionary attributeValue_subset, as form as {attributeValue_1: subset_1,... }
"""
attributeValue_subset = {}
for obj in data:
attributeValue = obj[attribute]
if attributeValue not in attributeValue_subset:
attributeValue_subset[attributeValue] = [obj]
else:
attributeValue_subset[attributeValue].append(obj)
for key in attributeValue_subset:
attributeValue_subset[key] = tuple(attributeValue_subset[key])
return attributeValue_subset
def selectAttribute(data, attributeList):
"""
:param data:
:param attributeList:
:return: the attribute that denotes the split criterion
"""
attributeValue_subset = dataPartition(data, attributeList[0])
dataSize = len(data)
maxGain = info(data) - infoForAttribute(dataSize, attributeValue_subset)
result = attributeList[0]
for attribute in attributeList[1:]:
attributeValue_subset = dataPartition(data, attribute)
temp = info(data) - infoForAttribute(dataSize, attributeValue_subset)
if temp > maxGain:
maxGain = temp
result = attribute
return result3. 决策树构建
到此,解决了属性选择的问题,那就可以着手完成整个决策树的构建了,代码如下,同样的,我省略了有些简单函数的代码,只是给出汉语的功能说明。具体详细的决策树代码请参考我的github主页:Decision_Tree
def isSameClass(data):
判断data中的数据对象是否属于同一类
def majorityVoting(data):
多数投票。返回data中,对象数量最多的类
def genDecisionTree(data, attributeList):
"""
:param data: dataset that contains data objects, is a tuple: (obj_1, ..., obj_n)
:param attributeList: a list that contains all attributes occurred in data
:return: the root of decision tree
"""
root = DecisionTreeNode()
if isSameClass(data):
root.tag = data[0]["class"]
return root
# majority voting
if len(attributeList) == 0:
root.tag = majorityVoting(data)
return root
# find the split criterion of root
root.splitCriterion = selectAttribute(data, attributeList)
root.isLeaf = False
# Partitioning the data for several blocks
# attributeValue_subset: a dictionary, {attributeValue: (data_object_1, data_object_2...)},
# where data_object_i is also a dictionary: {attribute_1: value, attribute_2: value...}
attributeValue_subset = dataPartition(data, root.splitCriterion)
attributeList.remove(root.splitCriterion)
for attributeValue in attributeValue_subset:
child = DecisionTreeNode()
subset = attributeValue_subset[attributeValue]
if len(subset) == 0:
child.tag = majorityVoting(data)
else:
attributeList_ForThisChild = copy.deepcopy(attributeList)
child = genDecisionTree(subset, attributeList_ForThisChild)
# pointers: a dictionary, as form as:
# {"youth": child_1, "middle_aged": child_2, "senior": child_3}
root.pointers[attributeValue] = child
return root以上,就是决策树构建的全过程了,也是ID3算法的实现过程。C4.5算法原理与之类似,不同点在于对最佳分裂属性的选择上。它使用了“增益率”来替代“信息增益”。
有关本文的详细代码请参考我的github:Decision_Tree