场景
在智能AI流行的当下,主流的大型电商系统都有自己的个性化店铺首页产品。简单的理解就是先对每个用户进行打标(行业说法叫做 用户画像),每个店铺会针对这些不同的标签策略(多个标签的组合)创建多个店铺首页。用户在访问店铺时首先查询出用户的所属标签列表,再跟店铺的多个首页对应的标签组合进行匹配,获取匹配度最高的标签策略对应的页面展示给用户即可。但如何获取到匹配度最高的标签策略呢?先来整理下思路:每个用户会对应多个标签,比如 性别:男性,购买力:高,促销敏感度:高 等等,这里把用户的标签列表长度记为:L0;每个店铺会对应多个标签策略,比如:男性新用户,这里把每个店铺的标签策略列表记为:L1;每个标签策略对应了多个标签,比如:性别:男性、用户类型:新用户,这边把标签策略的标签列表记为:L2。现在有三类列表:
用户标签列表:L0(为了简单起见,L0、L1、L2这里即表示长度,也表示类型)
店铺策略列表:L1(每个策略,对应一个不同的页面,即个性化页面)
策略标签列表:L2
回到开头的问题,实际上就是通过L0与L2进行匹配,以从L1中找出最合适的标签策略。一种简单而且最容易想到的做法(java伪代码):
String ret = null;
Int maxScore = 0;
L0 = get标签(userId); //获取用户的标签列表
L1 = get策略(shopId);//获取店铺的策略列表
for(策略 in L1){
L2 = get标签(策略) ; //获取策略对应的标签列表
Int score = 0;
for(标签 in L2){
if(L0. contain(标签)){
score +=1; //得分+1
}
}
if(score > maxScore) {
maxScore = score;
ret = 策略;
}
}
return ret;
这种算法就是轮询,如果匹配到的标签,就对策略的得分+1,最后的得分最高的策略对应的首页 就是该用户对应的个性化首页。不难看出这种算法有两个问题:1、时间复杂度为O(L0*L1*L2),相对于O(log n)来说是偏高的;2、如果有多个策略得分相同,就没办法区分。如果使用机器学习算法中"决策树",可以很好的解决上述两个问题。先来看看,什么是决策树,再来看看如果使用决策数据解决问题。
决策树
决策树的目标就是通过对多特征的样本数据进行训练,找出各个特征相互作用下的关系,最终构造成一棵树。根据算法的不同,可以是二叉树,也可以是多叉树,《机器学习实战》中采用的ID3算法,生成的是多叉树。对树进行搜索的时间复杂度,取决是树的高度,比如高度为n,时间复杂度为O(log n)。如果能用决策树算法,解决文章开头的问题,至少在在时间复杂度对比上优势是很明显的。下面来看一个简单的决策树:
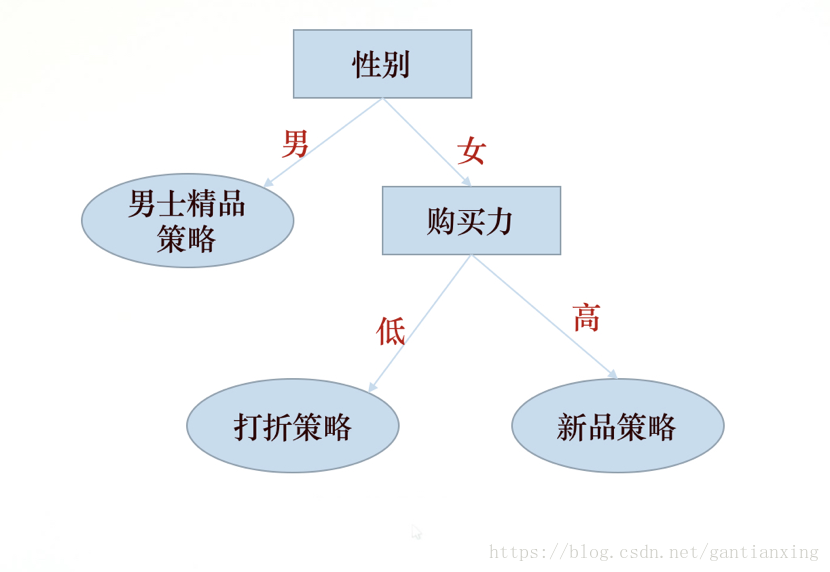
这里只展示了两个标签的情况,标签即对应决策树的特征,用做判断条件。要判断一个用户使用哪个决策,只需要根据这颗树从上到下进行判断比较即可。
相比普通算法除了有时间复杂度的优势外,决策树可以找出各个特征之间潜在的关系。假设一个用户的标签为:男性、低购买力,采用前面的普通算法,"男士精品策略"和"打折策略"的得分相同,这时就不知道选择哪个策略。而使用决策树,第一步判断就可以得出,应该选择"男士精品策略"。
为什么第一个节点选择"性别",而不是"购买力",这其实就是训练决策树 需要解决的问题。这里就涉及到"信息论"的概念,在使用某个特征划分数据之前和之后信息发生的变化称为"信息增益",计算出按照每种特征划分数据的"信息增益",选择"信息增益"最高的的特征作为决策树的第一个节点;选择第二节点也采用相同的方法,直到数据不可再分 或者 所有特征都判断完毕,这棵"决策树"就创建完成。 在判断某个用户属于哪种策略时,直接使用 这棵树(也叫经验树)从上到下进行判断即可。
现在问题的重点就集中到,如何计算"信息增益",有个叫 克劳德·香农的大牛是这样来定义的:待分类的事务(或者说数据样本)可能划分到多个分类中,符号xi的信息定义为:
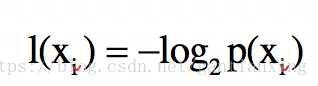
其中p(xi )是选择该分类的概率,要计算这些数据的所有信息(又称为 熵或香农熵),需要计算所有类别所有可能值包含的信息期望值,通过下面的公式计算得到(注意每项向前面都要乘概率):
H = p(x1 ) * log2 p(x1) p(x2 ) * log2 p(x2)… p(xn) * log2 p(xn),也就是:

其中n为分类的个数,也就是策略个数(注意不是特征个数)。假设没有分类前的熵为 H0,按照某个特征分类后的熵为H1,则"信息增益"=H0-H1。依次按照每个特征进行划分,取信息增益最大的作为 当前划分节点。
决策树实现
创建一颗决策树的,代码实现大致分为四步:第一步:实现计算香农熵函数
使用python实现的计算香农熵代码如下(截取自《机器学习实战》):
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
#为所有可能分类创建字典
for featVec in dataSet:
currentLabel = featVec[-1]
#计算每个分类选择次数
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
#计算分类概率
prob = float(labelCounts[key])/numEntries
#以2为底的对数
shannonEnt -= prob * log(prob,2)
return shannonEnt
calcShannonEnt方法本质上就是实现上面的H公式,即计算"熵"。要计算"信息增益",就是要在数据按照某个特征划分前后 分别调用该函数,让后求差值即可。第二步:实现划分数据集函数
#参数:待划分的数据集、划分数据集的列号(某个特征)、需要返回的特征的值
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
#去掉划分数据集的特征列
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
按照某个特征,划分样本数据集,比如特征为:性别,数据集会被划分为"男"数据集、"女"数据集。对划分之后计算香农熵 H,并且对每个特征都进行上述类似的计算过程。举个形象点的例子:

假设首先以"性别"进行划分,最后得到的就是 上图中1、2 两个子矩阵,对这两个子矩阵分别计算香农熵,再求和,即得到使用"性别"进行划分的熵H1。然后分别计算出,按照"购买力"和"促销敏感度"进行划分的熵H2,H3。假设,划分前的熵为H0,则每个划分的信息增益为:
H0 - H1 H0 - H2 H0 - H3
上述三个 值哪个最大就选择该特征进行划分。这个过程就是第三个函数选择最佳划分方式函数的实现。
第三步:实现最佳划分方式函数 实现如下:
#找到最好的划分特征
def chooseBestFeatureToSplit(dataSet):
#计算有多少个特征,最后一列是当前实例的类别标签,不是特征
numFeatures = len(dataSet[0])-1
#计算香农熵
baseEntopy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
#获取dataSet中的一列
featList = [example[i] for example in dataSet]
#去重
uniqueVals = set(featList)
newEntropy = 0.0
#计算每种划分方式的 信息熵
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
#计算"信息增益"
infoGain = baseEntopy - newEntropy
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
该函数返回的是,最佳划分的特征编号(就是矩阵的列号)。得到这个特征编号后,就下来就是构造决策树:按照这个特征进行划分,然后递归对其子集进行类似的划分,直到 数据集不能再分(所有数据额类别相同),或者 所有的特征都已经遍历完成。详见第四步。第四步 实现构造决策树函数,具体实现如下:
#创建决策树
def createTree(dataSet,lables):
#取出分类列
classList = [example[-1] for example in dataSet]
#类别相同 停止继续划分(count方法计算一个元素出现的次数,如果等于list长度 则完全相同)
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
# 遍历完所有特征 返回出现次数最多的一个分类
return majorityCnt(classList)
#选择最好的划分特征编号
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
#使用该特征,划分数据集后,递归调用 调用createTree继续划分
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
该函数会返回返回一个层层嵌套的字典。使用决策树进行策略分类选择:
#参数:决策树,分类标签,待预测分类的数据(某个用户的标签列表)
def classify(inputtree,featLabels,testVec):
firstStr = inputtree.keys()[0]
secondDict = inputtree[firstStr]
#定位第一个特征
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else: classLabel = secondDict[key]
return classLabel
构造训练样本数据:
def createDataSet():
dataSet = [
[1,0,0,0],
[1,1,1,1],
[0,1,0,2],
[0,0,0,2]
]
labels = ['男士折扣','男士精品','女士精品']
return dataSet,labels
编写main方法,运行测试程序:
if __name__ == "__main__":
myDat,labels = createDataSet()
myTree = createTree(myDat,labels)
# print myTree
print classify(myTree,['男士折扣','男士精品','女士精品'],[1,1,0])
打印结果为1,即说明用户标签如果为:男性、高购买力、低促销敏感,其对应的策略应该为"男士精品",选择该策略分类对应的个性化首页 进行展示即可。
总结
决策树算法的理论依据就是“信息增益”最大化,也就是划分后的熵最小,熵越小说明数据的纯度越高,也就是说越是容易进行分类。
另外决策树,难以处理连续型的特征,在算法选取时需要注意;决策树还存在过拟合问题(即 对训练样本的完全拟合,对其他数据训练效果不理想),通常还需要进行剪枝。