决策树学习算法最著名的代表是ID3、C4.5、CART。下面不同的决策树学习算法对应着不同的代表,把不同算法的代表说出来,可以在面试或者交流中提高B格。
一、介绍
决策树是一种常见的机器学习方法。决策树顾名思义就是基于树结构来进行决策的,这恰是人类面临决策问题时一种很自然最常见的处理机制。例如:我们去超市买瓜,如何判断这个瓜是否是好瓜?面对这样一个问题,我们通常会进行一系列的判断,比如我们先看“它纹路是否清楚?”,如果“清楚”,我们再看“它的根蒂是什么形态?”,如果是“蜷缩”,我们再判断"它敲击起来是什么声音?",如果声音“浊响”,最后我们做出决策,这是个好瓜。这就是一个典型的决策树判断法。
决策树的目的是为了产生一颗泛化能力强,即处理未见示例 能力强的决策树,其基本流程遵循“分而治之”策略,如下图

二、划分选择
1、信息增益
首先要引入“信息熵”的概念,是度量样本及和纯度的一种指标。假定当前样本集合D中第k类(类指的是最终的结果,比如说好瓜,坏瓜)样本所占的比例为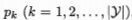
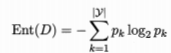
信息熵越小,表明集合的纯度越高。
假定离散属性a有V个可能的取值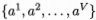

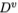


这个公式表示a属性的信息增益,也可以理解为信息增益等于集合D中所有属性得信息熵减去某个属性的信息熵,所有属性的信息熵肯定大于某个属性的信息熵,所以信息增益肯定为证,如果信息增益越大,说明这个属性的信息熵越小,说明这个属性越纯,也就是说如果我们用这个属性去划分,获得的“纯度提升”越大,因此我们可以用信息增益来进行决策树的划分属性的选择。
著名的ID3(Iterative Dichotomiser/迭代二分器)决策树学习算法就是以信息增益为准则来选择划分属性。
2、增益率
实际上,信息增益准则对可取值数目比较多的属性有所偏好,为了减少这种偏好可能带来的不利影响,著名的C4.5决策树算法不直接使用信息增益,而是使用“增益率”来选择最优化分属性,增益率公式为:
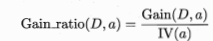
其中:
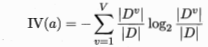
这个公式仔细去理解,其中第二个公式我的理解是求了权值的权值,可能这样表述不对,但是可以这样去理解,就像求导一样。
通过这个公式,我们可以看到,属性a可能取之数目越多,也就是V越大,IV(a)越大。需要注意的是增益率准则对可取值数目较少的属性有所偏好,因此C4.5算法并不是直接选择增益率最大的候选划分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3、基尼指数
CART决策树实用“基尼指数”来选择划分属性,采用与信息熵相同的符号,基尼指数计算公式如下:

Gini(D)反映了数据集D中随机抽取两个样本,其类别标记不一致的概率。因此Gini(D)越小,则数据集D的纯度越高。
若采用与信息增益相同的符号表示,公式为:
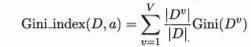
在候选属性集合A中,我们会选择使得基尼指数最小的属性作为最优的划分属性。
三、剪枝处理
“剪枝”顾名思义,就是去除决策树中对划分起副作用的枝。剪枝是决策树学习算法对付“过拟合”的主要手段。
这个地方有两个知识点,一是如何判断这个枝是否“过拟合”;二是如何剪枝。
我们首先来说第二个问题,如何剪枝,剪枝有两种策略,“预剪枝”和“后剪枝”。预剪枝是指在决策树生成过程中,对每个节点在划分前进行估计,如果当前节点划分不能带来决策树泛化性能的提升,则停止划分。后剪枝则是先生成一颗完整的决策树,然后自底向上的对非叶节点进行考察,如果该节点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。预剪枝降低了过拟合风险,但是也增加了欠拟合风险;后剪枝欠拟合风险很小,泛化性能往往优于预剪枝决策树,但是其训练时间以及资源消耗要比预剪枝大得多。
接下来说第二个问题,如何判断是否“过拟合”。首先你要对“过拟合”有个彻底的理解,过拟合指的就是泛化性能的变化,如果增加枝,但是决策树泛化性能没有提高或者是下降,这就是典型的过拟合。下面我们通过一个例子来看一下如何判断“过拟合”。
首先我们来看一下一个细化数据集,我们分为训练集和验证集:

下图就是基于上表生成的未剪枝决策树:

我们来看一下根节点1,如果没有节点1也就是没有划分,我们暂且认为都是好瓜,这样我们用验证集去验证的划分正确率是(3/7)42.9%,我们用训练集进行训练之后,发现脐部凹陷是好瓜,稍凹也是好瓜(你也可以训练位坏瓜,结果是一样的),平坦的是坏瓜,再用验证集验证,发现划分正确率是(5/7)71.4%,我们可以确定这个枝不是“过拟合”。我们现在看一下节点2,划分之后用验证集验证,发现划分精度是(4/7)57.1%,所以我们可以确定这个枝是“过拟合”,然后剪掉这个分支。如下所示:
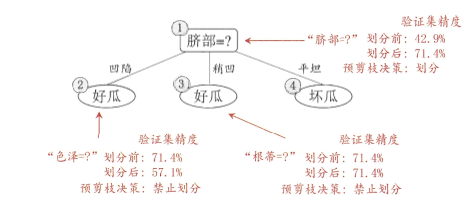
最后我们得到剪枝处理之后的决策树:

四、连续与缺失值
1、连续值处理
之前我们研究的都是基于离散属性来生成的决策树。现实任务中常常会遇到连续属性,所以接下来我们要讨论的是如何在决策树学习中实用连续属性。可能有人不知道什么是离散属性什么是连续属性,在这里介绍一下通俗的理解方式:离散属性是指有限的,连续属性是无穷尽的。举个连续属性的例子,比如西瓜中的含糖率。
由于连续属性可取值数目不再有限,因此,不能直接根据连续属性的可取值来对节点进行划分。此时,连续属性离散化技术可以派上用场,最简单的就是二分法,这也正是C4.5决策树算法中 采用的机制。
给定样本集D和连续属性a,假设a在D上出现了n个不同的取值,我们将这个数值从小到大排序,记为

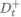
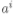

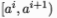
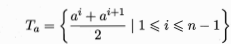
联系之前信息增益的公式,我们可以得到:
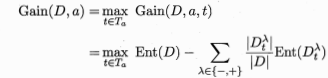
这个式子表示样本集D基于划分点t二分后的信息增益。于是,我们可选择使信息增益最大化的划分点。
2、缺失值处理
五、多变量决策树

在多变量决策树的徐熙过程中,不是为每个非叶结点寻找一个最有划分属性,二是试图建立一个合适的线性分类器。
最后考验一下大家对预剪枝理解的深度:为什么预剪枝会带来欠拟合风险?