1 决策树
决策树是一种能解决分类或回归问题的机器学习算法。
其有良好的扩展性,可以产生多种变种。
并且结合模型融合方法扩展新的算法AdaBoost,GBDT等算法。
参考文章:
C4.5算法详解(非常仔细):https://blog.csdn.net/zjsghww/article/details/51638126
解释很详细:http://www.saedsayad.com/decision_tree.htm
决策树算法原理(上):https://www.cnblogs.com/pinard/p/6050306.html
2 决策树算法

- 算法思想
决策树训练的过程就不段选择分裂属性将样本拆分到子树的子节点。最佳分裂属性应该是能让树分裂完成后,每棵子树的样本类别更纯,所以衡量不纯度的属性适合作为分裂的评价指标。
- 算法实例
以一个算法代入实例帮助理解决策树算法ID3,其他算法代入和使用方式类似。
A Step by Step ID3 Decision Tree Example:
https://sefiks.com/2017/11/20/a-step-by-step-id3-decision-tree-example/
2.1 ID3
2.1.1 信息熵
熵越大,样本类别越多。使用信息熵衡量分裂后的不纯度。信息增益相当于看分裂前后的熵的减少量。
We can summarize the ID3 algorithm as illustrated below
信息熵:
Entropy(S) = ∑ – p(I) . log2p(I)
信息增益:
Gain(S, A) = Entropy(S) – ∑ [ p(S|A) . Entropy(S|A) ]
These formulas might confuse your mind. Practicing will make it understandable.
2.1.2 算法流程
以下是算法描述:其中T代表当前样本集,当前候选属性集用T_attributelist表示。
(1)创建根节点N
(2)为N分配类别
(3)if T都属于同一类别or T中只剩下一个样本则返回N为叶节点,为其分配属性
(4)for each T_attributelist中属性执行该属性上的一个划分,计算此划分的信息增益
(5)N的测试属性test_attribute=T_attributelist中最大信息增益的属性
(6)划分T得到T1 T2子集
(7)对于T1重复(1)-(6)
(8)对于T2重复(1)-(6)
2.2 C4.5
2.2.1 信息增益率
算法倾向选择特征中属性值角度的特征。这时可以规范化信息增益,除以这个属性的熵值(注意:之前算法算的都是一堆样本类别的熵。这个算的是这个属性中属性值的熵。也是算的是当前所在树节点上的样本的值,每次算的不一样)。
2.2.2 算法流程

参考:
2.3 CART
2.3.1 算法流程:
以下是算法描述:其中T代表当前样本集,当前候选属性集用T_attributelist表示。
(1)创建根节点N
(2)为N分配类别
(3)if T都属于同一类别or T中只剩下一个样本则返回N为叶节点,为其分配属性
(4)for each T_attributelist中属性执行该属性上的一个划分,计算此划分的GINI系数
(5)N的测试属性test_attribute=T_attributelist中最小GINI系数的属性
(6)划分T得到T1 T2子集
(7)对于T1重复(1)-(6)
(8)对于T2重复(1)-(6)
2.3.2 基尼系数
基尼系数和信息熵关系;
信息熵一阶泰勒展开推导基尼系数:https://blog.csdn.net/YE1215172385/article/details/79470926
基尼系数相比信息熵,计算代价更小,相当于一阶泰勒展开的近似。首先不用算上一步的信息熵,其次不用计算log了。
原始基尼系数:

将基尼系数的P乘以进公式,就可以展开如下计算公式:
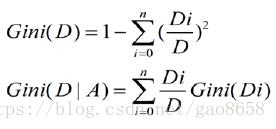
2.3.3 MSE
扩展决策树可以解决回归问题:
以二叉分叉为例,每个节点样本点计算和这个节点样本点均值误差。
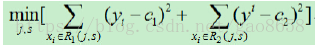
3 随机森林
3.1 OOB
The RandomForestClassifier is trained using bootstrap aggregation, where each new tree is fit from a bootstrap sample of the training observations  . The out-of-bag (OOB) error is the average error for each
. The out-of-bag (OOB) error is the average error for each  calculated using predictions from the trees that do not contain in their respective bootstrap sample. This allows the
calculated using predictions from the trees that do not contain in their respective bootstrap sample. This allows theRandomForestClassifier to be fit and validated whilst being trained [1].
http://scikit-learn.org/stable/auto_examples/ensemble/plot_ensemble_oob.html
3.2 随机森林算法流程
(1)原始训练集为 N,应用 bootstrap法有放回地随机抽取 k个新的 自助样本集,并由此构建 k棵分类树,每次未被抽到的样本组成了 k个袋外数据
(2)设有 Mall 个变量,则在每一棵树的节点处随机抽取 Mtry个 变量,然后在 Mtry中选择一个最具有分类能力的 变量,阈值通过检查每一个分类点确定
(3)每棵树最大限度地生长 , 不做任何修剪
(4)将生成的多棵分类树组随机森林,预测时,每棵树都对样本产生预测。预测的结果求平均,代表相应结果。
4 Adaboost
- 训练完一棵树,准备训练下一棵树考虑:
重视上一次分错的样本
- 在最终使用Boost模型的所有树进行预测时考虑:
重视准确度更高的树


对分类问题相当于每轮最小化指数loss,推导出的权重更新和分类器权重更新公式。
参考:
adaboost推导公式参考:https://en.wikipedia.org/wiki/AdaBoost
对分类问题相当于每轮最小化指数loss。
将loss更换应该可以推导出regression loss:
5 GBDT
思想:
当前训练的树弥补上一棵树预测不准确的残差
方法:
- 通过梯度下降让预测值Y能最快的收敛到目标值。相比之前的BGD,这里考虑的是损失函数对Y的BGD。
- 让决策树每次拟合Y进行梯度下降中的梯度(Gradient)。
GBDT分为两种:
(1)残差版本
残差其实就是真实值和预测值之间的差值,在学习的过程中,首先学习一颗回归树,然后将“真实值-预测值”得到残差,再把残差作为一个学习目标,学习下一棵回归树,依次类推,直到残差小于某个接近0的阀值或回归树数目达到某一阀值。其核心思想是每轮通过拟合残差来降低损失函数。总的来说,第一棵树是正常的,之后所有的树的决策全是由残差来决定;
(2)梯度版本
与残差版本把GBDT说成一个残差迭代树,认为每一棵回归树都在学习前N-1棵树的残差不同,Gradient版本把GBDT说成一个梯度迭代树,使用梯度下降法求解,认为每一棵回归树在学习前N-1棵树的梯度下降值。总的来说两者相同之处在于,都是迭代回归树,都是累加每颗树结果作为最终结果(Multiple Additive Regression Tree),每棵树都在学习前N-1棵树尚存的不足,从总体流程和输入输出上两者是没有区别的。
两者的不同主要在于每步迭代时,是否使用Gradient作为求解方法。前者不用Gradient而是用残差—-残差是全局最优值,Gradient是局部最优方向*步长,即前者每一步都在试图让结果变成最好,后者则每步试图让结果更好一点。
两者优缺点。看起来前者更科学一点–有绝对最优方向不学,为什么舍近求远去估计一个局部最优方向呢?原因在于灵活性。前者最大问题是,由于它依赖残差,cost function一般固定为反映残差的均方差,因此很难处理纯回归问题之外的问题。而后者求解方法为梯度下降,只要可求导的cost function都可以使用。

参考:
https://en.wikipedia.org/wiki/Gradient_boosting
The Evolution of Boosting Algorithms From Machine Learning to Statistical Modelling
GBDT与Adaboost的区别与联系(对adaboost和GBDT推导有个较好解释):https://zhuanlan.zhihu.com/p/31639299
5 模型融合
The goal of ensemble methods is to combine the predictions of several base estimators built with a given learning algorithm in order to improve generalizability / robustness over a single estimator.
Two families of ensemble methods are usually distinguished:
-
In averaging methods, the driving principle is to build several estimators independently and then to average their predictions. On average, the combined estimator is usually better than any of the single base estimator because its variance is reduced.
Examples: Bagging methods, Forests of randomized trees, …
-
By contrast, in boosting methods, base estimators are built sequentially and one tries to reduce the bias of the combined estimator. The motivation is to combine several weak models to produce a powerful ensemble.
5.1 Bagging
同模型融合,预测结果投票
A Bagging classifier is an ensemble meta-estimator that fits base classifiers each on random subsets of the original dataset and then aggregate their individual predictions (either by voting or by averaging) to form a final prediction. Such a meta-estimator can typically be used as a way to reduce the variance of a black-box estimator (e.g., a decision tree), by introducing randomization into its construction procedure and then making an ensemble out of it.
参考:http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html
5.2 Stacking
不同模型融合,预测结果投票
5.3 Boosting
线性训练每棵树,不能并行训练,每棵树对上棵树训练不好的地方进行优化。
参考:http://scikit-learn.org/stable/modules/ensemble.html#voting-classifier
参考:http://scikit-learn.org/stable/modules/ensemble.html
友情推荐:ABC技术研习社
为技术人打造的专属A(AI),B(Big Data),C(Cloud)技术公众号和技术交流社群。
