决策树算法的定义
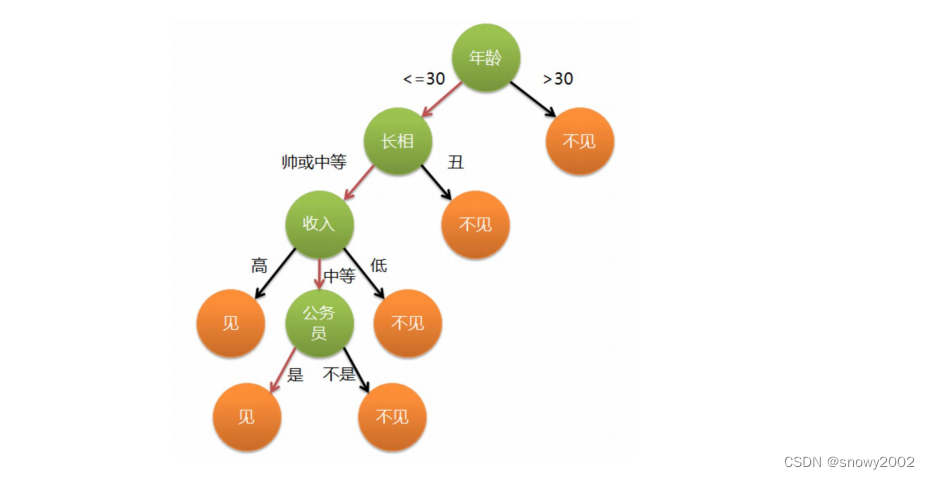
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
发展历程
决策树的发展先后经历了ID3、C4.5已经CART三种算法。

适用范围及其优缺点
适用范围
决策树算法比较适合用于离散型的数据分布,比如当特征的取值只有0和1时,使用决策树算法往往会取得很好地效果,如果处理的数据为连续型分布,在分类决策时,同样还需要将其变成离散型分布,比如设置一个中间值,将所有数据变为与中心值比较的大小关系。
优点
- 决策树易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
- 对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
- 易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
缺点
- 对连续性的字段比较难预测。
- 对有时间顺序的数据,需要很多预处理的工作。
- 当类别太多时,错误可能就会增加的比较快。
- 一般的算法分类的时候,只是根据一个字段来分类。
代码实现
数据下载:https://pan.baidu.com/s/1debtGBe-J4-7eQJh6pVU2w?pwd=z91e
# 导入各种包,其中决策树所在的包为tree
import numpy as np
from sklearn import tree
import graphviz
#导入数据
data=np.genfromtxt("cart.csv",delimiter=',')
x_data=data[1:,1:-1]
y_data=data[1:,-1]
x_data,y_data
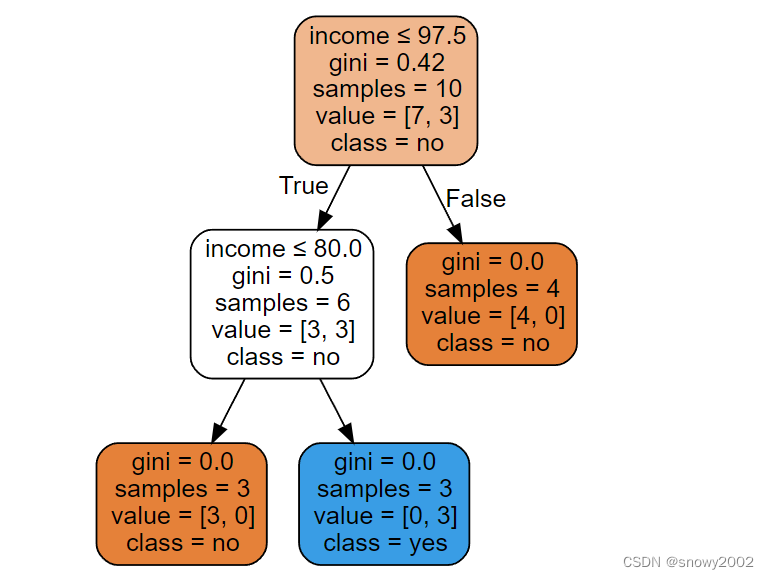
model=tree.DecisionTreeClassifier() #建立决策树模型,默认分类到叶子结点
model.fit(x_data,y_data)
#导出决策树图形
dot_data=tree.export_graphviz(model,
feature_names=['house_yes','house_no','single','married','divorced','income'],
class_names=['no','yes'],
filled=True,
rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data) #绘图
graph.render('cart') #保存为pdf文件
graph #输出决策树图形