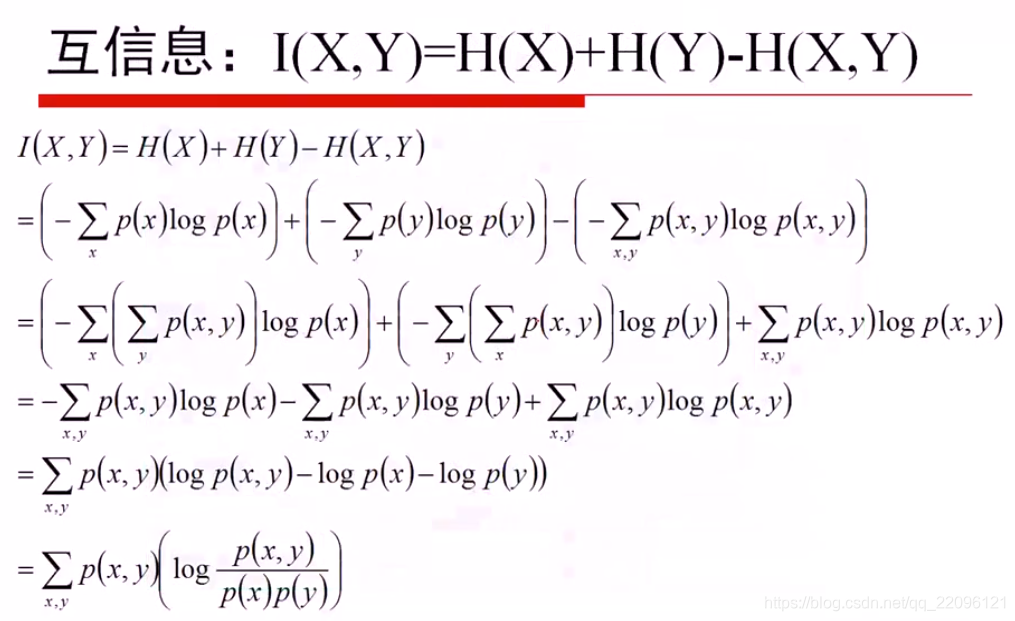决策树的好处
训练速度快
如何建立树?
-
假设有N个样本:[n1,n2,n3,...nn]将N个节点都列为root节点,
-
现在给出分类的标准(切一刀分成两部分),讲样本分类成左边有N1个样本,右边有N2个,则N1+N2=N,重点在于选择哪个特征将样本分类。
-
然后将N1和N2中的样本在根据指定分类标准进行分类。
-
如此进行下去。
决策树前置知识
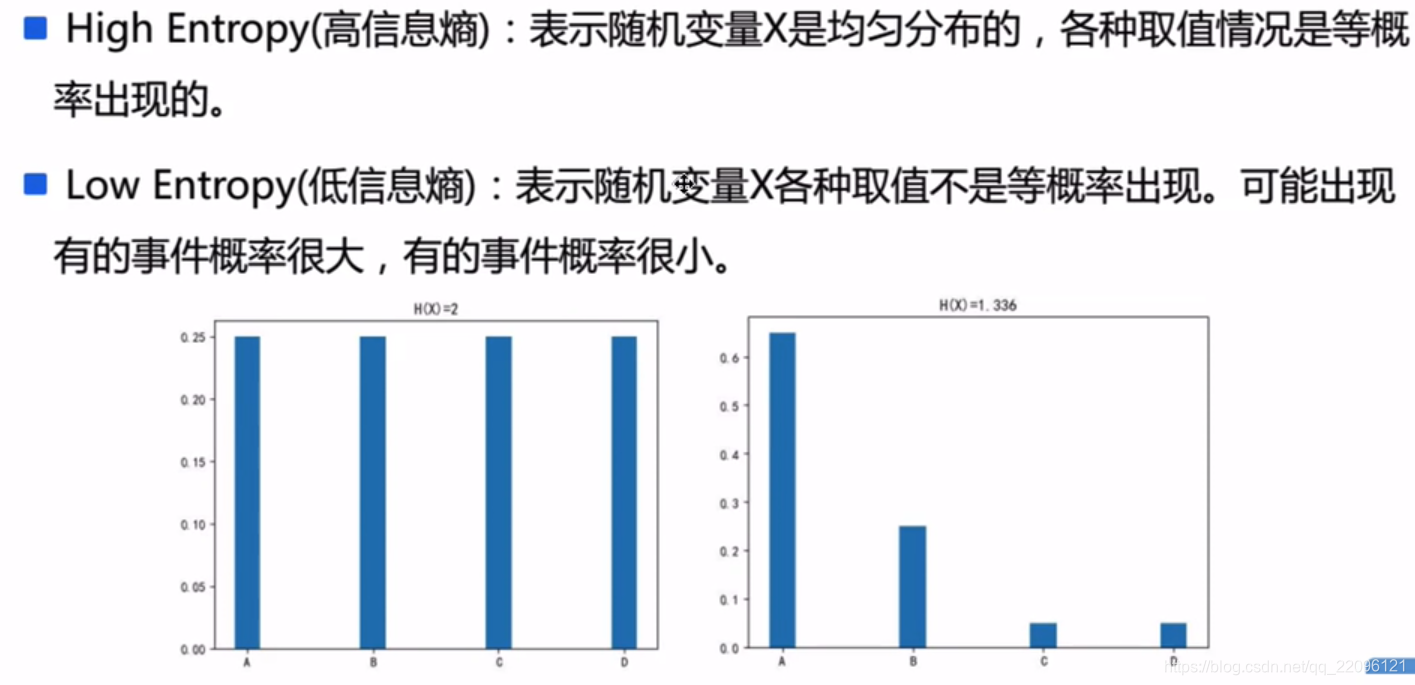
信息熵
| x |
0 |
1 |
| P |
1-p |
p |
| log P |
-log (1-p) |
-log p |
- 信息熵的定义
E[logP]=−(1−p)∗log(1−p)−p∗logp=−i=1∑npi∗logp
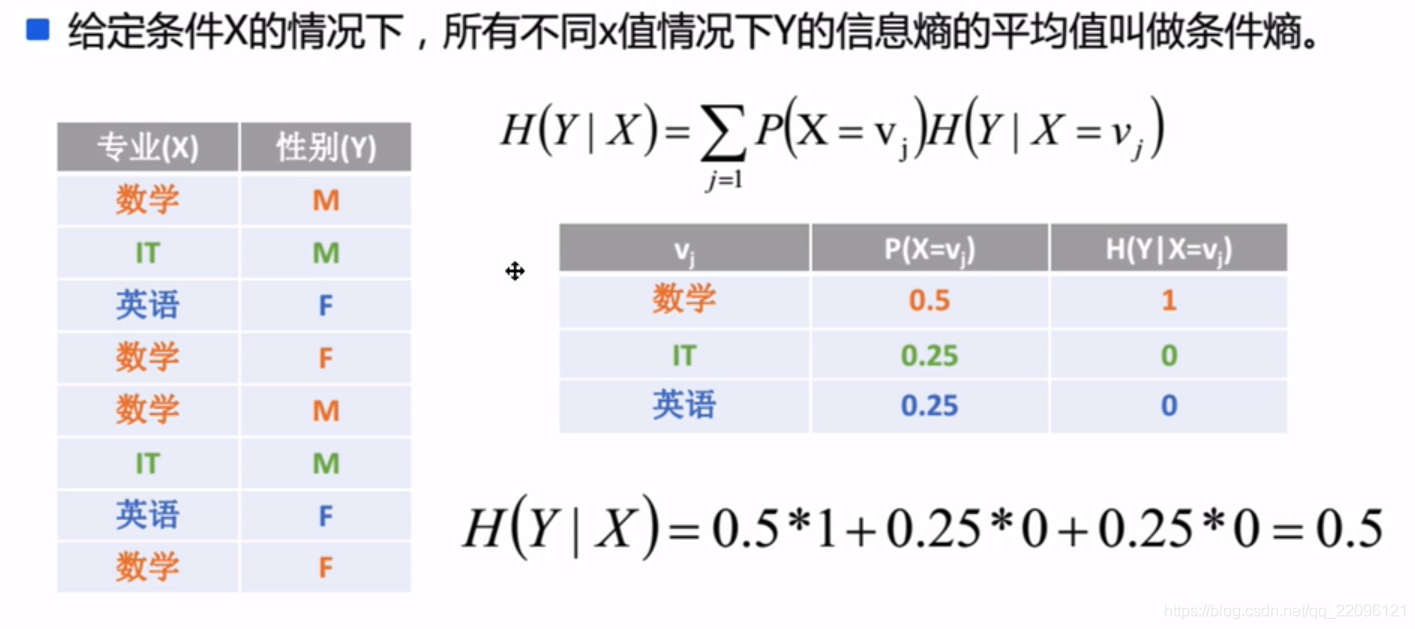
条件熵

联想全概率公式:x条件下y发生的概率等于x,y同时发生的概率初一x发生的概率。
P(y∣x)=P(x)P(x,y)

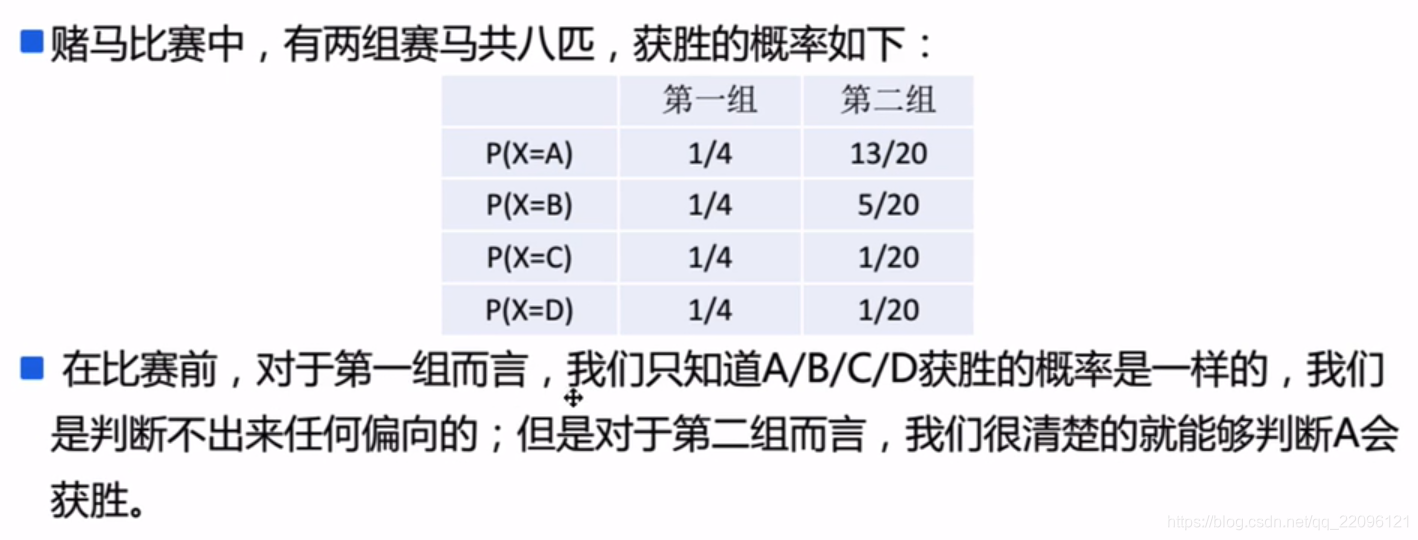
一个例子:

信息熵H(X)计算:
P(X=数学)=21,P(X=英语)=41,P(X=IT)=41
H(X)=−21log221−41log241−41log241
H(X)=0.5+0.5+0.5=1.5
信息熵H(Y)计算:
P(Y=F)=21,P(Y=M)=21
H(Y)=−21log221−21log221
H(Y)=0.5+0.5=1
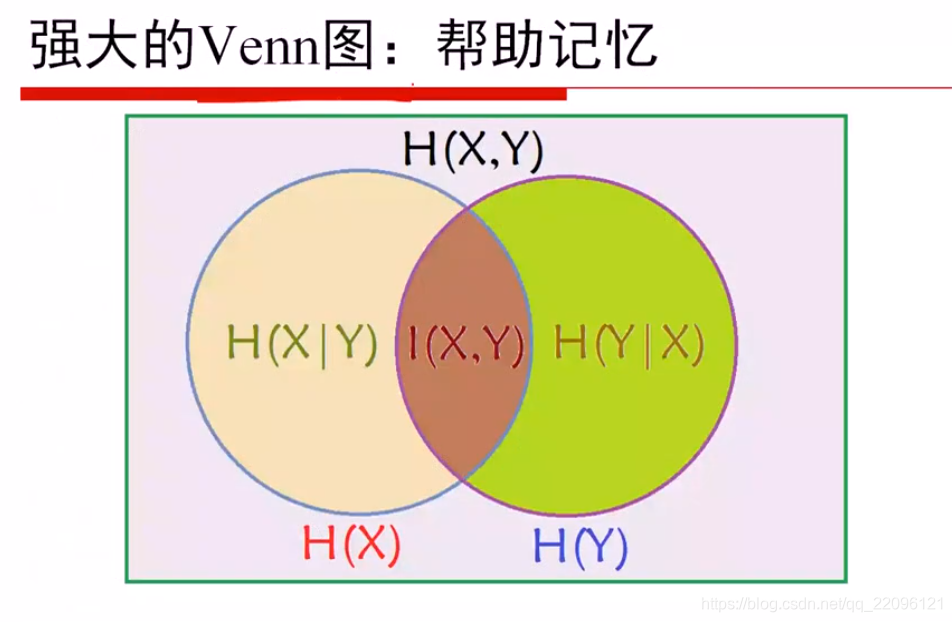
互信息
相对熵

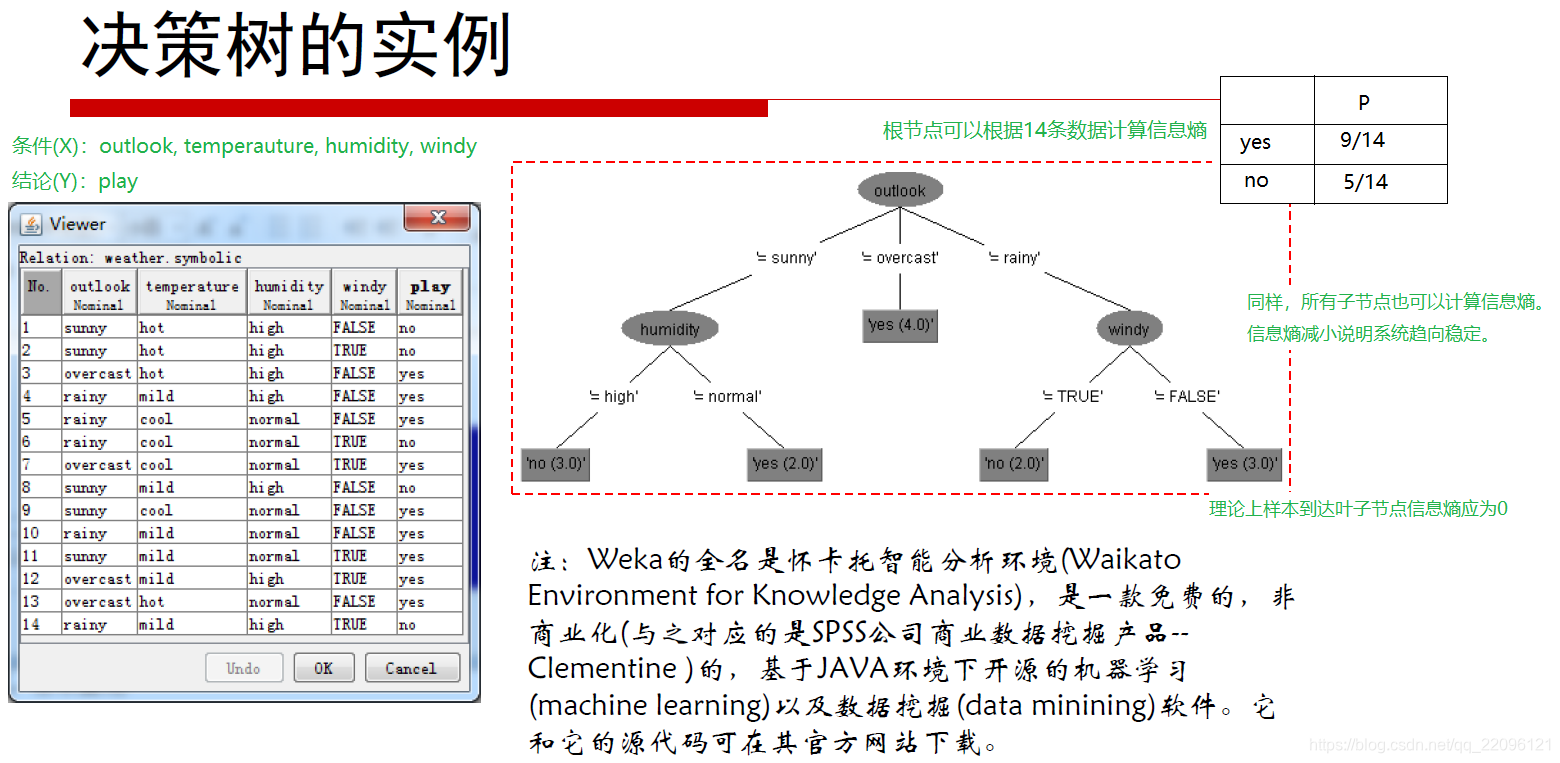
从熵到决策树
所谓决策树,就是熵从根节点到叶子节点不断下降的一棵树。

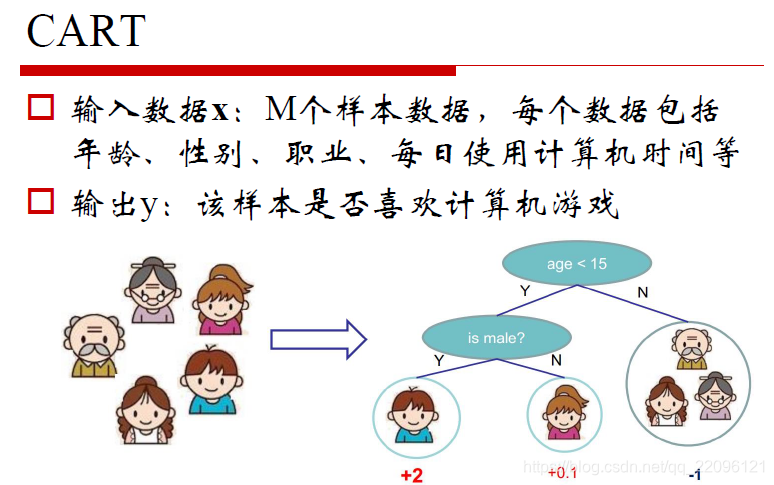
CART(C&RT)
如下例中,根据年龄和性别分类,叶子节点为最终结果。
还是上例,在根据使用使用时间创建一个决策树:
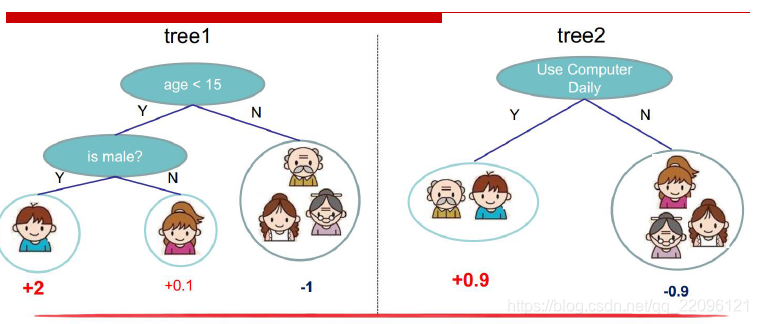
现在得到两棵树,同时对两棵树的结果做和。得到新的结果,实际上多棵树就可以称为森林。
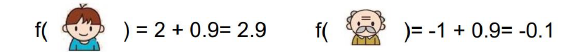
ID3
使用熵下降最快的特征。
C4.5 信息增益率



其他目标
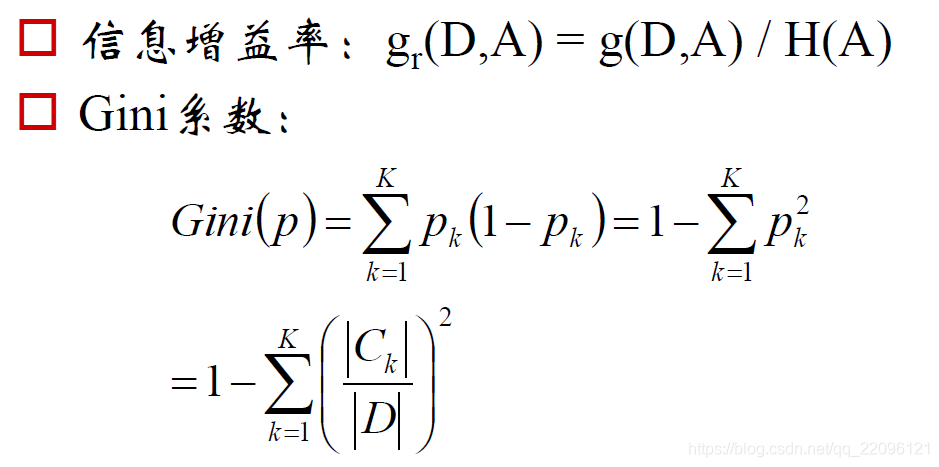
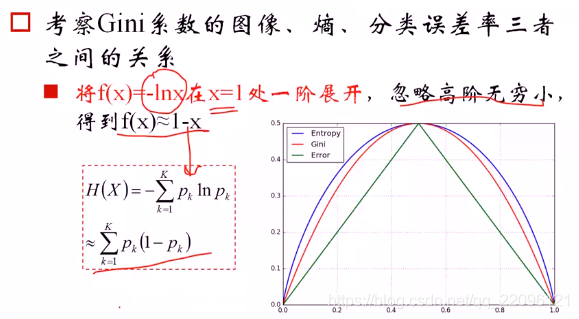
在第一定义中:
Gini越大 贫富差距越大
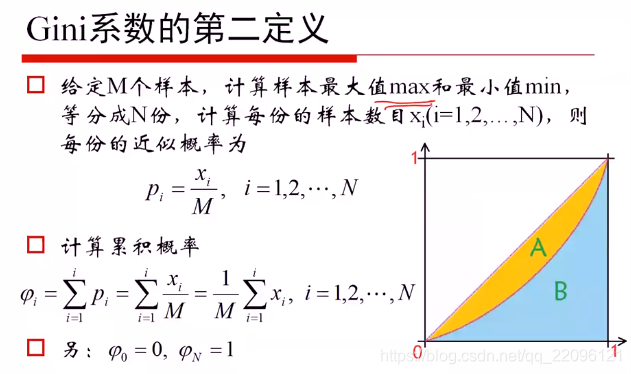
在第二定义中
Gini->0 平均
Gini->1 最不平均
小结




- N个样本N次采集,每次采样被采集到的概率为
N1
- N次采样每次没有被采集到的概率为
1−N1
- N次采样都没有被采集到的概率为
(1−N1)N
- N次采样有被采集到的概率为
1−(1−N1)N
N→0lim[1−(1+−N1)−N]
1−e1≈63.2%
约有63.2%的数据会参与建树,没有参与建树的36.8%的数据称为OOB可用于做测试数据。

随机森林