目录
四、ELK+Filebeat+ZooKeeper+Kafka搭建部署
引言
ELK和Filebeat原理和搭建在前面已经说过了
ELK日志分析系统(一)之ELK原理_IT.cat的博客-CSDN博客ELK日志分析(二)之ELK搭建部署_IT.cat的博客-CSDN博客[ELFK]日志分析系统搭建---Filebeat_IT.cat的博客-CSDN博客
但是我这里是重新搭建,所以IP地址会有所改变
server 192.168.130.70 kibana elasticsearch node #es集群就省略了
server 192.168.130.60 logstash filebeat
#zookeeper+kafka集群
server 192.168.130.50 zookeeper+kafka
server 192.168.130.40 zookeeper+kafka
server 192.168.130.30 zookeeper+kafka所以我们直接从zookeeper和kafka开始讲起

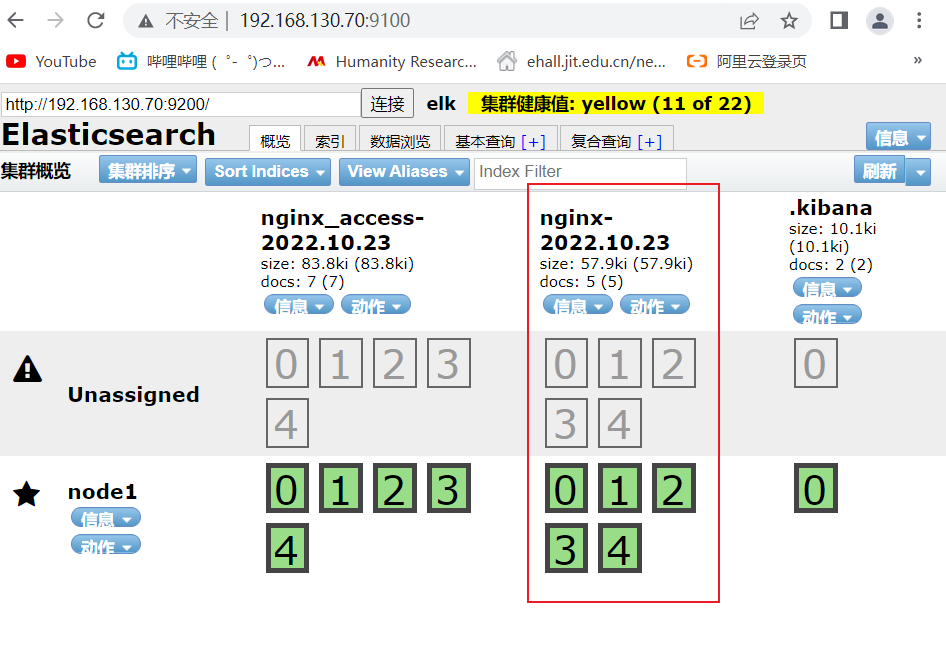
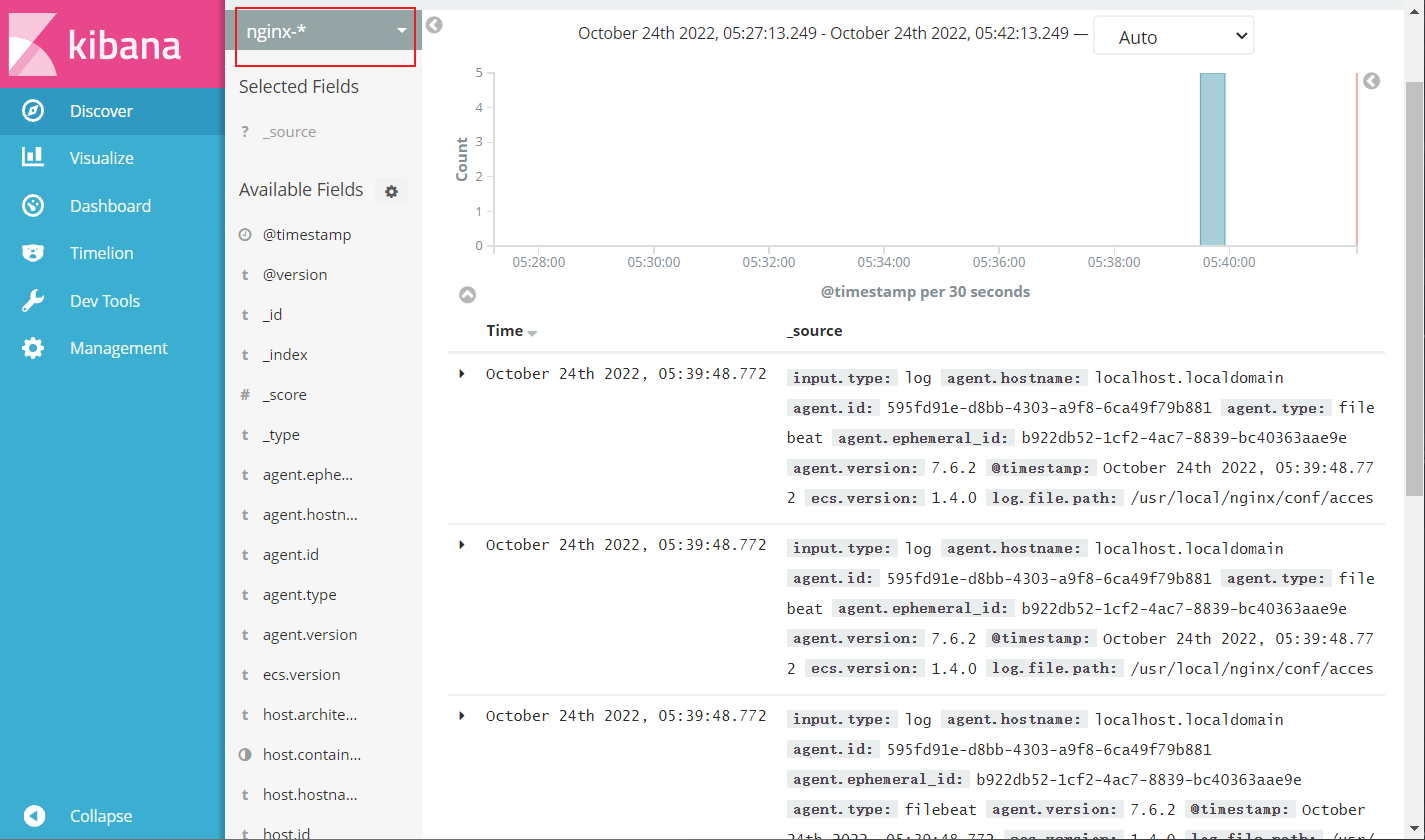
这里是elfk已经将nginx中的access日志获取到了
一、ZooKeeper介绍
Zookpper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。分布式应用开源基于它实现更高级的服务,实现诸如同步服务、配置维护和集群管理或者命名的服务。
Zookeeper服务自身组成一个集群,2n+1个(奇数)服务允许n个失效,集群内一半以上机器可用,Zookeeper就可用。
假设3台机器组成的集群,可用有允许一台失效,如果有2台失效,这个集群就不可用,1<1.5,一般的搭建zookeeper集群时,以奇数台机器来搭建。目的:是为了提高容错能允许多损失一台。
二、Kafka介绍
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。既然是消息队列,那么Kafka也就拥有消息队列的相应的特性了。可以在系统中起到“削峰填谷”的作用,也可以用于异构、分布式系统中海量数据的异步化处理。
2.1、为什么需要消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最好请求线程会堆积过多,从而触发too mang connection错误,英法雪崩效应。
我们通过使用消息队列,通过以读处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的MQ中间件有ActiveMQ、RabbitMQ、RocketMQ、Kafka等
2.2、消息队列的好处
解耦合
耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能。
异步处理
异步处理替代了之前的同步处理,以部处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可
流量削峰
高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止系统的高请求,减轻服务器的请求处理压力
2.3、Kafka的特性
2.4、Kafka作为存储系统
2.5、Kafka消费模式
Kafka的消费模式(两种)
一种是一对一的消费,也即点对点的通信,即一个发送一个接收
第二种为一对多的消费,即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费
一对一

消息生产者发布消息到Queue队列中,通知消费者从队列中拉取消息进行消费。消息被消费之后则删除,Queue支持多个消费者,但对于一条消息而言,只有一个消费者可以消费,即一条消息只能被一个消费者消费
一对多
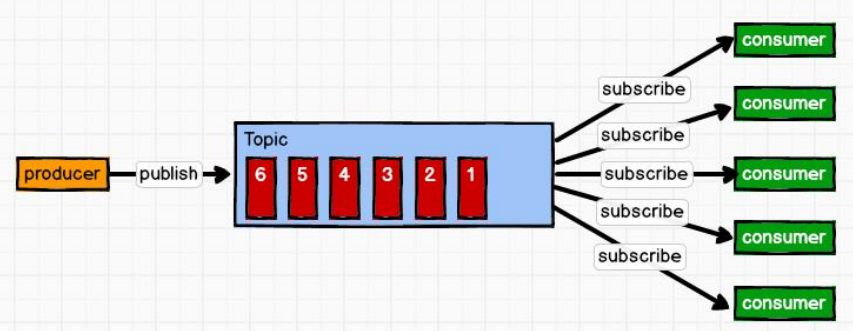
这种模式也成为发布/订阅模式,即利用Topic(一个消息集合)存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此Topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清楚,Kafka会默认保留一段时间,然后再删除。
三、Kafka的基础架构
3.1、Kafka架构
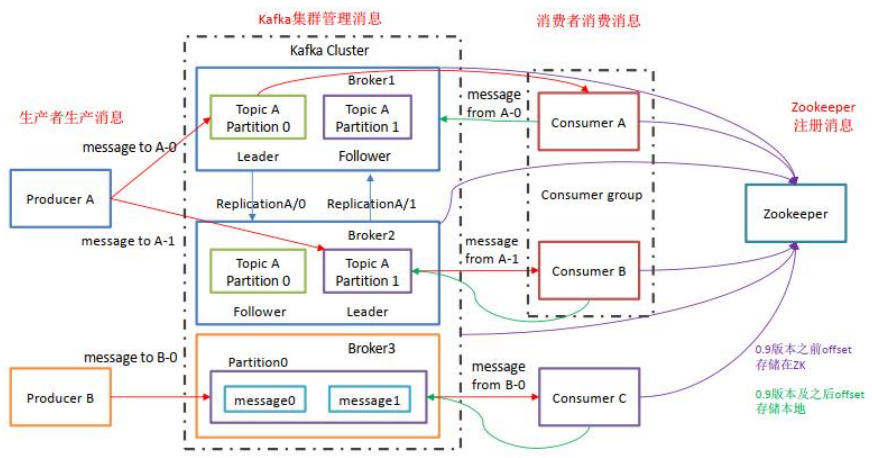
Producer:Producer即生产者,消息的产生者,是消息的入口
Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个 broker 对应一台服务器。每个 kafka 集群内的 broker 都有一个不重复的编号.
Topic:消息的主题,可以理解为消息的分类,kafka 的数据就保存在 topic。在每个broker上都可以创建多个 topic。
Partition:Topic 的分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。同一个 topic 在不同的分区的数据是不重复的,partition 的表现形式就是一个一个的文件夹!
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader故障的时候会选择一个备胎(Follower)上位,成为 Leader。在 kafka 中默认副本的最大数量是 10 个,且副本的数量不能大于Broker 的数量,follower 和 leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message:每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。
Consumer Group:我们可以将多个消费组组成一个消费者组,在 kafka 的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个 topic 的不同分区的数据,这也是为了提高 kafka 的吞吐量!
Zookeeper:kafka 集群依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性。
Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
Follower:每个分区多个副本的从角色,实时的从 Leader 中同步数据,保持和Leader 数据的同步,Leader 发生故障的时候,某个 Follower 会成为新的 Leader。3.2、分区的原因
- 便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个topic 又可以有多个 Partition 组成,因此整个集群就可以适应任意大小的数据了;
- 可以提高并发,因为可以以 Partition 为单位读写了。
3.3、工作流程

Producter 将消息发送给 leader
Leader 将消息写入本地文件
Followers 从 leader 同步消息
Follower 将消息写入本地后向 leader 发送 ACK 确认消息
Leader 收到所有副本的 ACK 后,向 producter 发送 ACK
注:消息写入 leader 后,follower 是主动的去 leader 进行同步的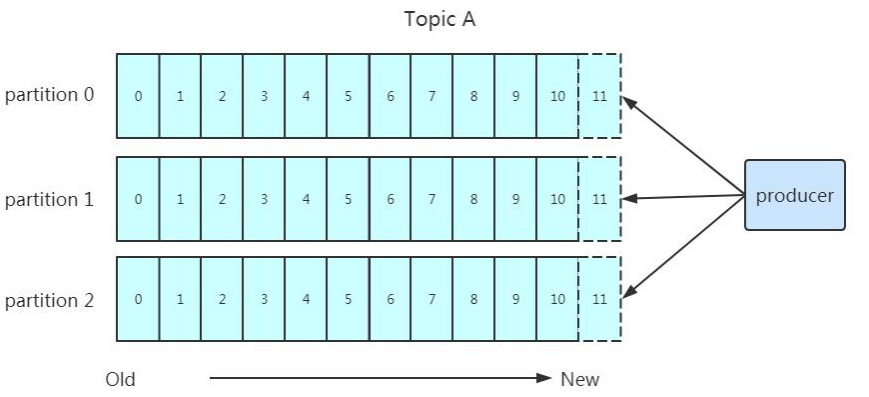
数据会写入到不同的分区,分区的目的是:
方便扩展:因为一个 topic 可以有多个 partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
提高并发:以 partition 为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。partition 在写入的时候可以指定需要写入的 partition,如果有指定,则写入对应的partition。
如果没有指定 partition,但是设置了数据的 key,则会根据 key 的值 hash 出一个partition。
如果既没指定 partition,又没有设置 key,则会轮询选出一个 partition。- 0 代表 producer 往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1 代表 producer 往集群发送数据只要 leader 应答就可以发送下一条,只确保leader 发送成功。
- all 代表 producer 往集群发送数据需要所有的 follower 都完成从 leader 的同步才会发送下一条,确保 leader 发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
四、ELK+Filebeat+ZooKeeper+Kafka搭建部署
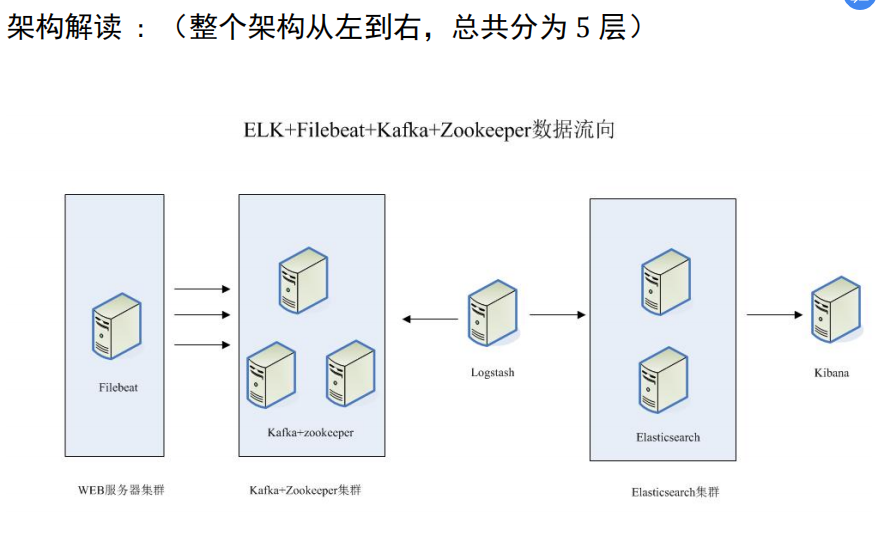
这个架构图从左到右,总共分为 5 层,每层实现的功能和含义分别介绍如下:
第一层、数据采集层
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat 做日志收集,然后把采集到的原始日志发送到 Kafka+zookeeper 集群上。
第二层、消息队列层
原始日志发送到 Kafka+zookeeper 集群上后,会进行集中存储,此时,filbeat 是消息的生产者,存储的消息可以随时被消费。
第三层、数据分析层
Logstash 作为消费者,会去 Kafka+zookeeper 集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至 Elasticsearch 集群
第四层、数据持久化存储
Elasticsearch 集群在接收到 logstash 发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到 Elasticsearch 集群上。
第五层、数据查询、展示层
Kibana 是一个可视化的数据展示平台,当有数据检索请求时,它从 Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。由于条件限制,我们将logstash和Filebeat部署在一台服务器上,并且少一台es集群
server 192.168.130.70 kibana elasticsearch node #es集群就省略了
server 192.168.130.60 logstash filebeat
#zookeeper+kafka集群
server 192.168.130.50 zookeeper+kafka
server 192.168.130.40 zookeeper+kafka
server 192.168.130.30 zookeeper+kafka前面的ELK已经搭好,Filebeat后续还要更改配置
4.1、zookeeper安装配置
下载,解压zookeeper安装包
#zookeep下载地址
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
#解压安装包
tar -zxf apache-zookeeper-3.8.0-bin.tar.gz
mv apache-zookeeper-3.8.0-bin /usr/local/zookeeper-3.8.0
cd /usr/local/zookeeper-3.8.0/conf/
cp zoo_sample.cfg zoo.cfg
修改配置文件
vim zoo.cfg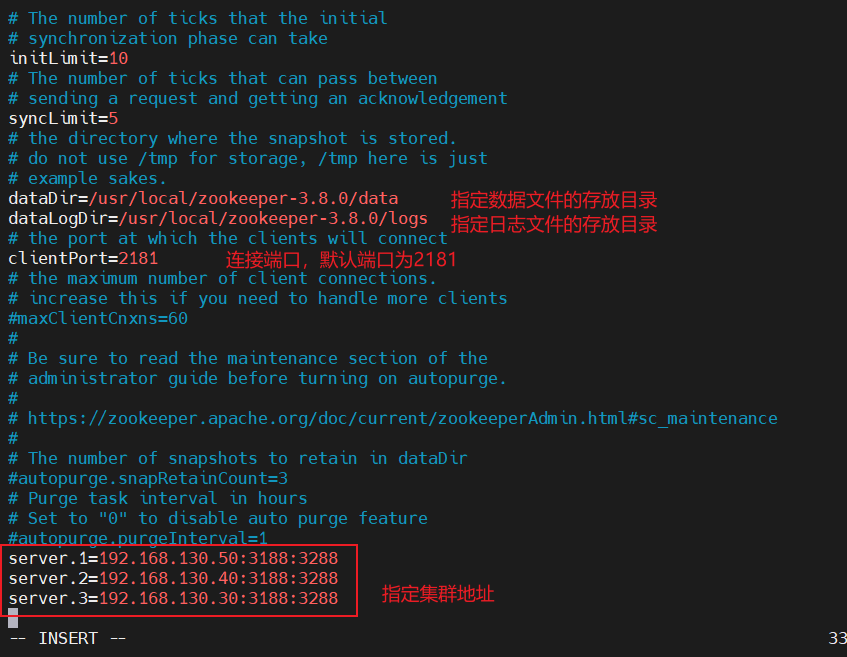
其他两台都执行以上的部署和修改文件,配置文件可以通过scp进行传输
scp zoo.cfg 192.168.130.40:/usr/local/zookeeper-3.8.0/conf 192.168.130.30:/usr/local/zookeeper-3.8.0/conf
去另外两台看一下
![]()
都有了,并且内容一致
每台机器都指定对应的节点号
cd /usr/local/zookeeper-3.8.0
mkdir data logs
echo 1 > data/myid注意:每台都要执行,并且节点号不能相同



启动zookeeper
cd /usr/local/zookeeper-3.8.0/bin
./zkServer.sh start #启动
./zkServer.sh status #查看状态


4.2、Kafka安装配置
下载解压Kafka
#下载kafka
cd /opt
wget http://archive.apache.org/dist/kafka/2.7.1/kafka_2.13-2.7.1.tgz
tar zxf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
修改配置文件
cd /usr/local/kafka/config/
vim server.properties
三台相同设置,但是id号不能一样


添加系统环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile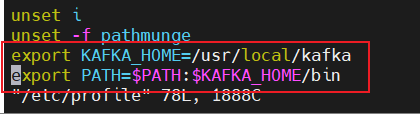
启动kafka
cd /usr/local/kafka/config/
kafka-server-start.sh -daemon server.properties
netstat -antp | grep 9092
Kafka命令行操作
创建topic
kafka-topics.sh --create --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181 --replication-factor 2 --partitions 3 --topic test
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称查看当前服务器中的所有topic
kafka-topics.sh --list --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181查看某个topic的详情
kafka-topics.sh --describe --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181发布消息
kafka-console-producer.sh --broker-list 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test --from-beginning
--from-beginning:会把主题中以往所有的数据都读取出来修改分区数
kafka-topics.sh --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --alter --topic test --partitions 6删除topic
kafka-topics.sh --delete --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --topic test4.3、创建topic
cd /usr/local/kafka/bin
kafka-topics.sh --create --zookeeper \
192.168.130.50:2181,192.168.130.40:2181,192.168.130.30:2181 \
--partitions 3 \
--replication-factor 2 \
--topic test
kafka-topics.sh --describe --zookeeper 192.168.130.50:2181
#查看详情
4.4、测试topic
发布消息
kafka-console-producer.sh --broker-list 192.168.130.50:9092,192.168.130.40:9092,192.168.130.30:9092 --topic test
kafka-console-producer.sh --broker-list 192.168.130.40:9092 --topic test
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.130.30:9092 --topic test --from-beginning
4.5、配置数据采集层filebeat
定制nginx日志格式
vim /usr/local/nginx/conf/nginx.conflog_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
access_log /usr/local/nginx/conf/access.log json;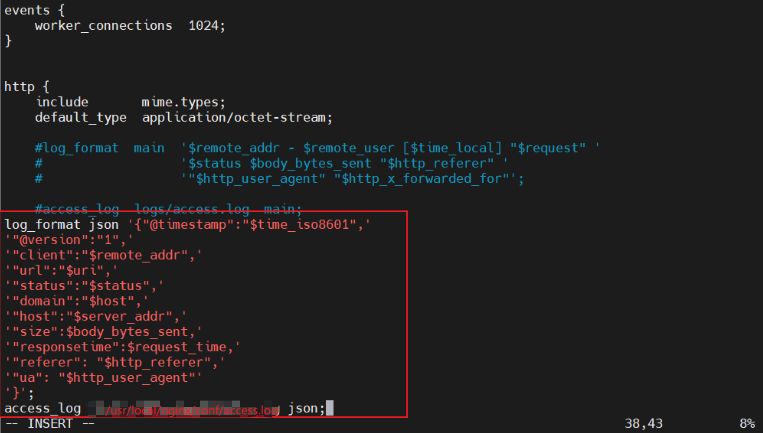
再重启一下nginx
修改filebeat配置文件
vim /usr/local/filebeat/filebeat.yml其他不变
这里的path指向位置一定要与上面nginx指定的日志路径一样


启动filebeat
./filebeat -c filebeat.yml &
4.6、在kafka上创建一个话题nginx-es
kafka-topics.sh --create --zookeeper 192.168.130.50:2181,192.168.130.40:2181,192.168.130.30:2181 --replication-factor 1 --partitions 1 --topic nginx-es
修改logstash的配置文件
vim /etc/logstash/conf.d/logstash.conf
systemctl restart logstash
4.7、查看网页认证