7.0 ETH挖矿算法篇2
7.1 伪代码理解以太坊挖矿算法
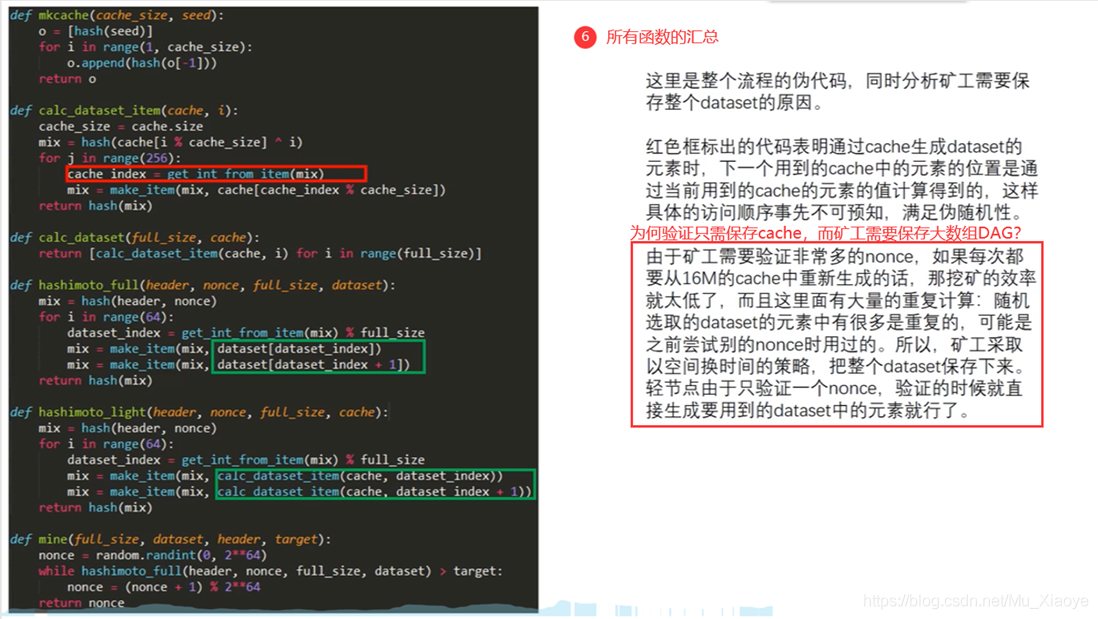
mkcache:根据一个seed,填充整个cache数组。

calc_dataset_item:通过cache来生成大数据集中的第i个元素,基本思想是通过伪随机的顺序读取cache中的256个数,每次读取的位置是由上一个读取的数计算得到的。第一个要从cache读取的数据的位置由初次mix决定,而mix是由"i'决定的,“i”每次都是不同的,所以mix也一定不同。(不同的mix可能对应初次读取的cache数组下标一样的,但是第二个读取的数字下标mix也会参与,所以第一个读取的位置虽然可以相同,但后续的读取顺序是不同的。也就是mix决定了初始读取的位置也决定了读取顺序。)
get_int_from_item:从哈希值解析出位置下标,就是用当前算出来的哈希值mix求出下一个要读取的位置cache_index。
make_item:利用两个哈希值得到新的哈希值,是用cache中这个位置cache_index的数和当前的哈希值mix计算出下一个哈希值也叫mix。

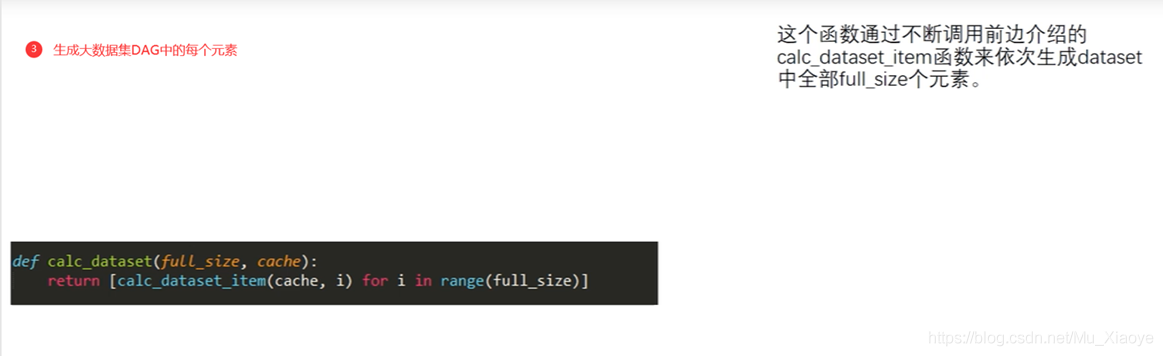
calc_dataset:填充完整个DAG数组,就是不断调用calc_dataset_item。
hashimoto_full:矿工用来挖矿的函数,header是当前要生成的区块的块头,(挖矿只需要用到块头是因为这样轻节点只需要保存块头就可以验证这个区块是否符合挖矿难度。)nonce就是当前尝试的nonce值,full_size是大数据集中元素的个数,元素的个数每3万个区块会增加一次,增加原始大小的1/128,dataset就是前面生成的大数据集DAG。
挖矿过程:首先根据块头的信息和初始的nonce生成一个哈希值mix,然后要经过64轮循环,每次循环中首先根据当前哈希值mix值得到大数据中的元素下标,然后读取下标所指向的元素数据再和当前哈希值mix更新哈希值mix,与生成DAG类似使用了make_item函数。利用刚更新好的mix和数组下标,得到数组下标后一位的值和mix更新后的mix。循环64次结束后返回一个哈希值用来和目标阈值做比较。虽然每次循环中读取DAG的两个相邻位置的哈希值,但这两个哈希值的生成过程是独立的,每个都是由16M的cache中256个数生成的,而且这256个数读取顺序是按照伪随机的顺序产生的,没什么联系。
hashimoto_light是轻节点用来验证的函数,header是收到矿工挖到区块的块头,nonce是包含在这个块头里的nonce,而full_size仍然是大数据集中的元素个数,cache是用来验证用的16M的cache。calc_dataset_item是通过cache计算大数据中第dataset_index的元素,轻节点虽然没能保存大数据集,但是它能每次独立的计算具体位置的元素是什么。它与挖矿的区别在于,DAG的某个位置的元素是从cache推出来的,而挖矿是直接取读取DAG的。

mine: 挖矿函数,就是不断的修改nonce值,从0到2的64次方。先随机生成一个nonce值,再不断+1尝试。
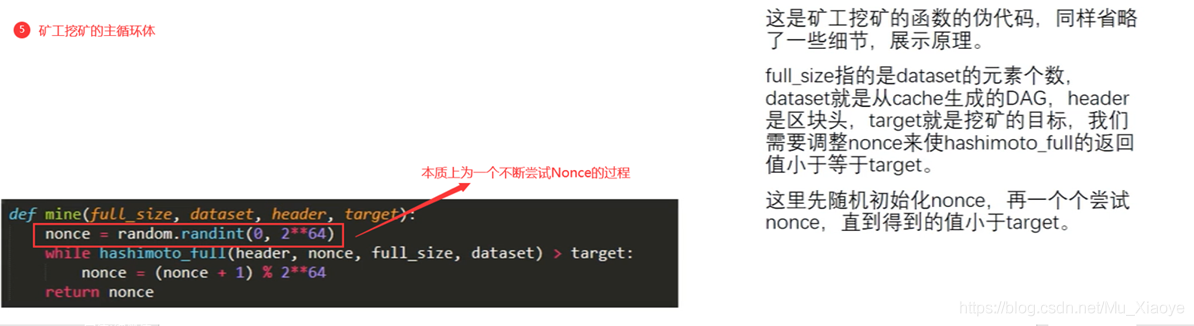
所有函数的汇总,解释了读取顺序的随机性,和验证只需要保存cache,而挖矿需要DAG输入。
目前以太坊挖矿以GPU为主,可见其设计较为成功,这与以太坊设计的挖矿算法(Ethash)所需要的大内存具有很大关系。 1G的大数组与128k相比,差距8000多倍,即使是16MB与128K相比,也大了一百多倍,可见对内存需求的差距很大(况且两个数组大小是会不断增长的)。 当然,以太坊实现ASIC Resistance除了挖矿算法设计之外,还存在另外一个原因,即其预期从工作量证明(POW)转向权益证明(POS)
7.2 权益证明(POS:Proof of State)
权益证明:按照所占权益投票进行共识达成,类似于股份制有限共识按照股份多少投票,权益证明不需要挖矿。 而这对于ASIC矿机厂商来说,就好比一把悬在头上的达摩克利斯之剑。因为ASIC芯片研发周期很长,成本很高,如果以太坊转入权益证明,这些投入的研发费用将全部白费(ASIC矿机只能用于挖特定的加密货币)。 但实际上,以太坊目前仍然是POW挖矿共识机制。在设计之初,以太坊开发者就设想要从POW转向POS,并为了防止有矿工不愿意转埋下了一颗“难度炸弹”。但截至目前,以太坊仍然基于POW共识机制。
其实很多时候,面对一些问题转换思路就能得到很好的解决方案。如这里,如果按照原本思想,通过不断改进挖矿算法来达成ASIC Resistance,无疑是比较难的。而这里通过不停宣传要转向POS来不断吓阻矿工,使得矿工不敢擅自转入ASIC挖矿,从而实现了ASIC Resistance。
7.3 预挖矿(Pre-Mining)
以太坊中采用的预挖矿的机制。这里“预挖矿”并不挖矿,而是在开发以太坊时,给开发者预留了一部分货币。以太坊的早期开发者,目前就很有钱了。 而比特币并未采用这一模式,所有比特币都是通过挖矿产生的。但早期挖矿难度容易,所有中本聪本人本来就有很多币。 和Pre-Mining对应,还有Pre-Sale,Pre-Sale指的是将预留的货币出售掉用于后续开发,类似于拉风投或众筹。目前,各类加密货币很多,存在一部分货币就在采用Pre-Sale来获取资金,如果此时买入,后续如果该货币取得成功,同样可以获得很大收益。
7.4 以太坊统计数据
-
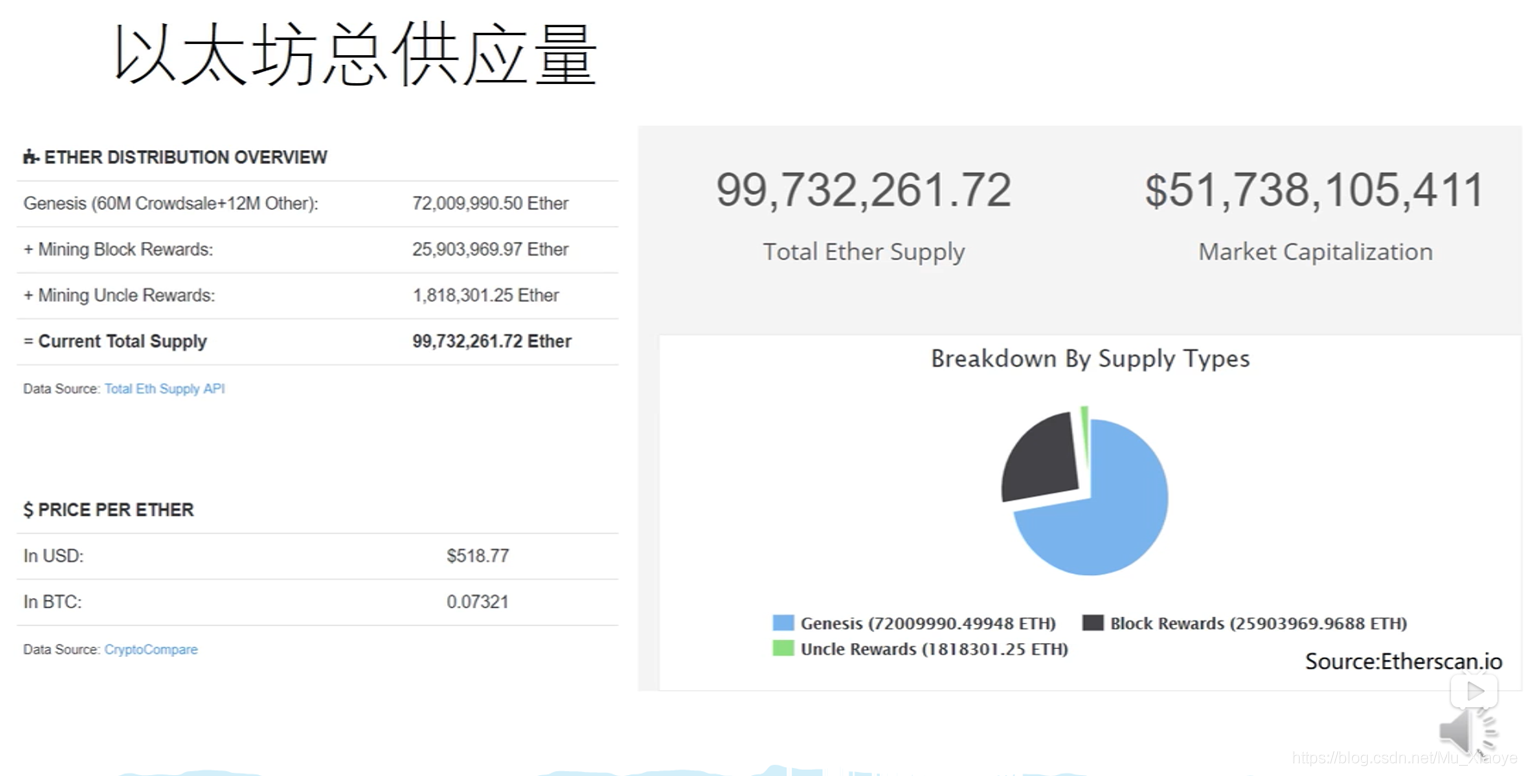
以太坊中以太币供应量(2018年) 饼状图中,总量大约1亿,蓝色部分都是Pre-Mining产生的(接近3/4)。黑色部分为出块奖励产生的以太币,绿色为叔父区块产生的奖励以太币。挖矿挖的再努力,关键还是不能输在起跑线上。。
-
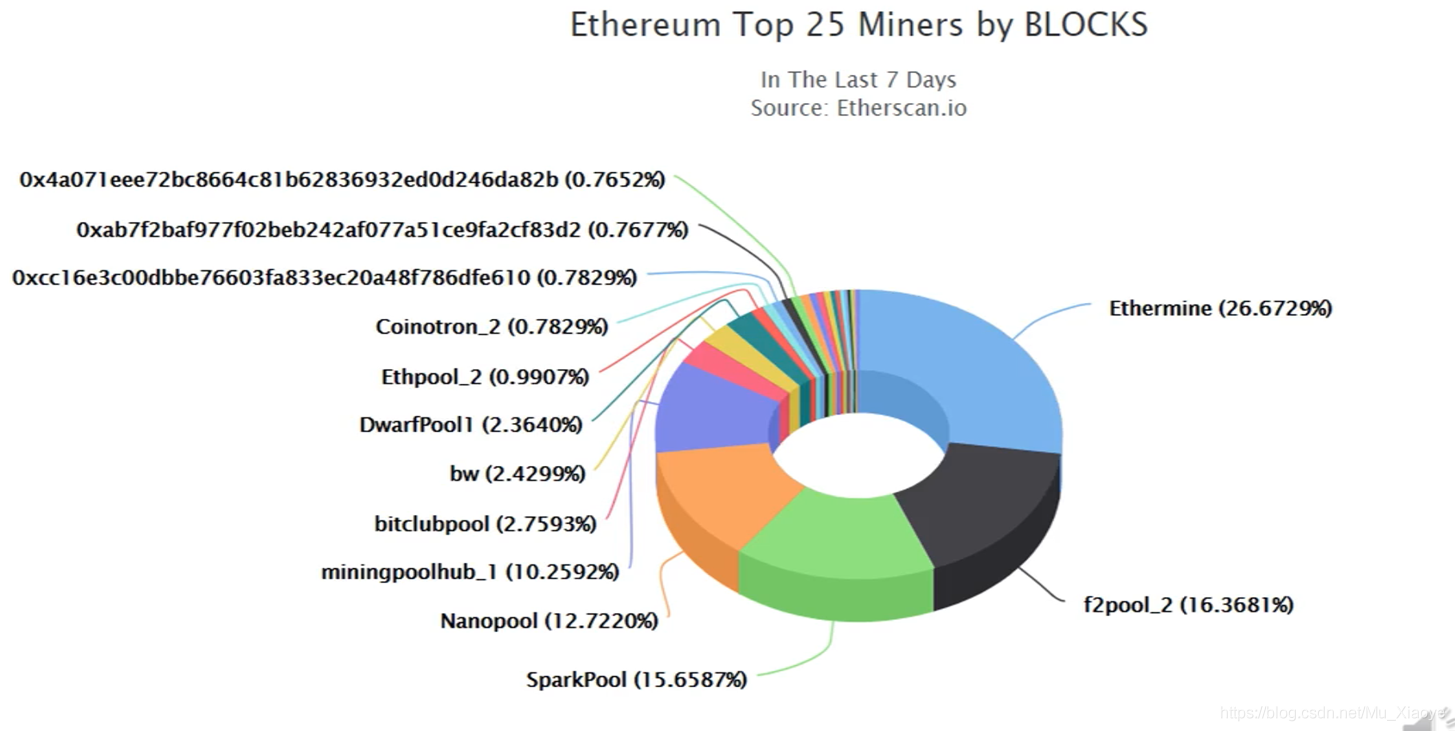
最大的25个矿池挖矿算力比重(2018年)
可以看出挖矿集中化比较高。
-
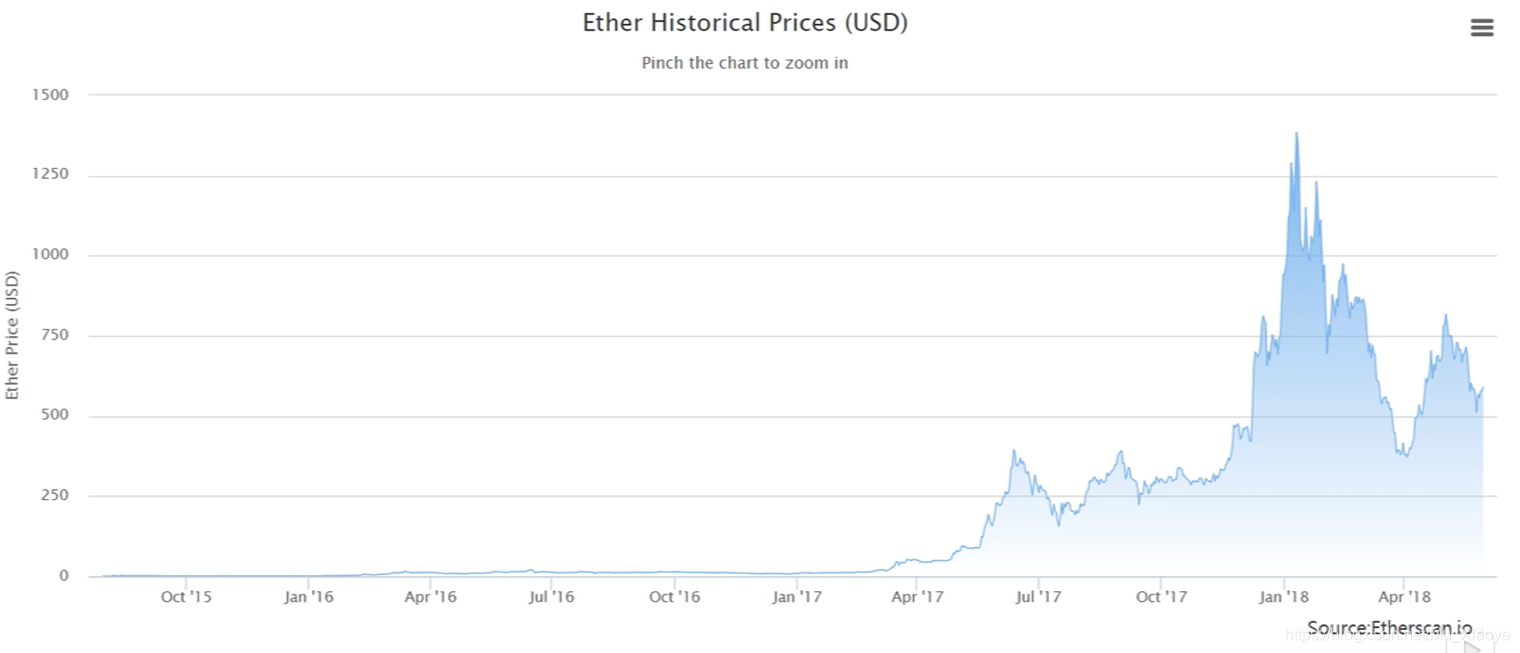
以太币价格变化情况(至2018年) 可见,2017年以太坊才开始大涨。
-
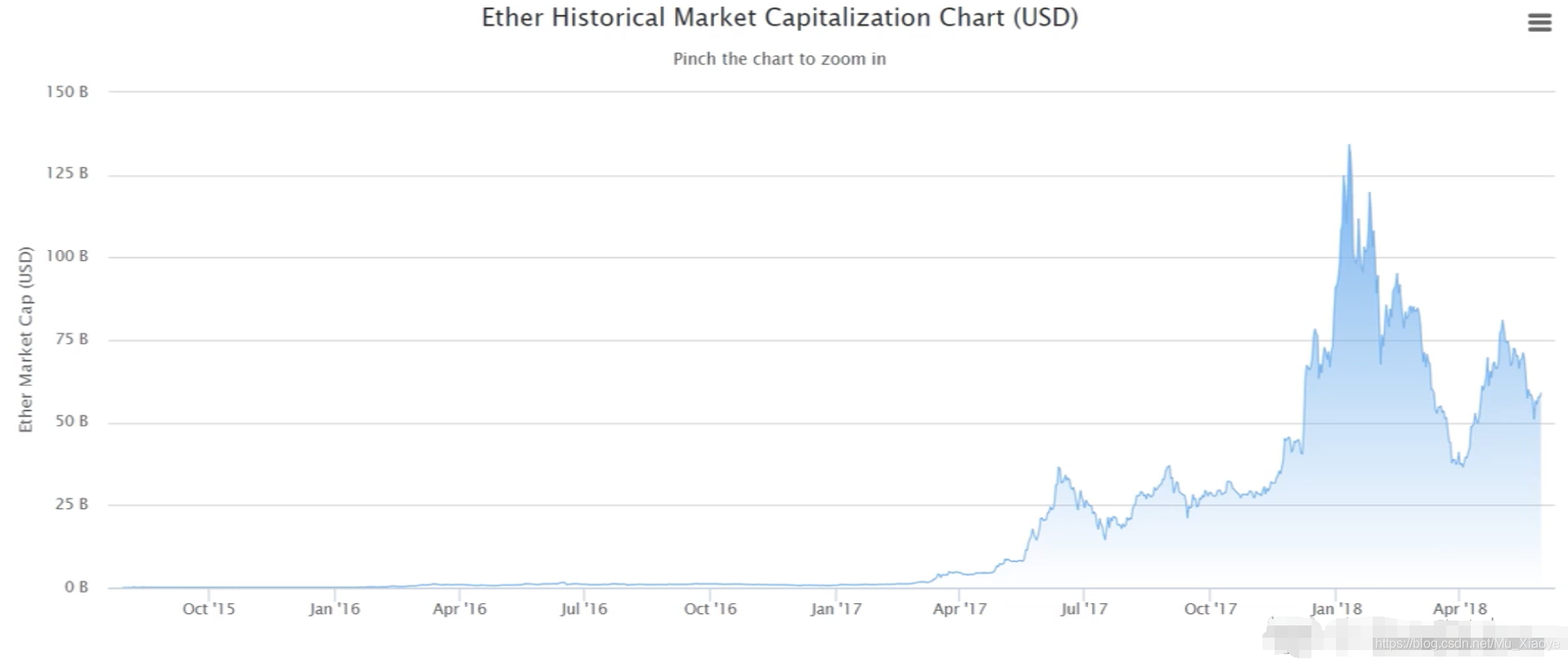
以太币市值变化情况(至2018年)
-
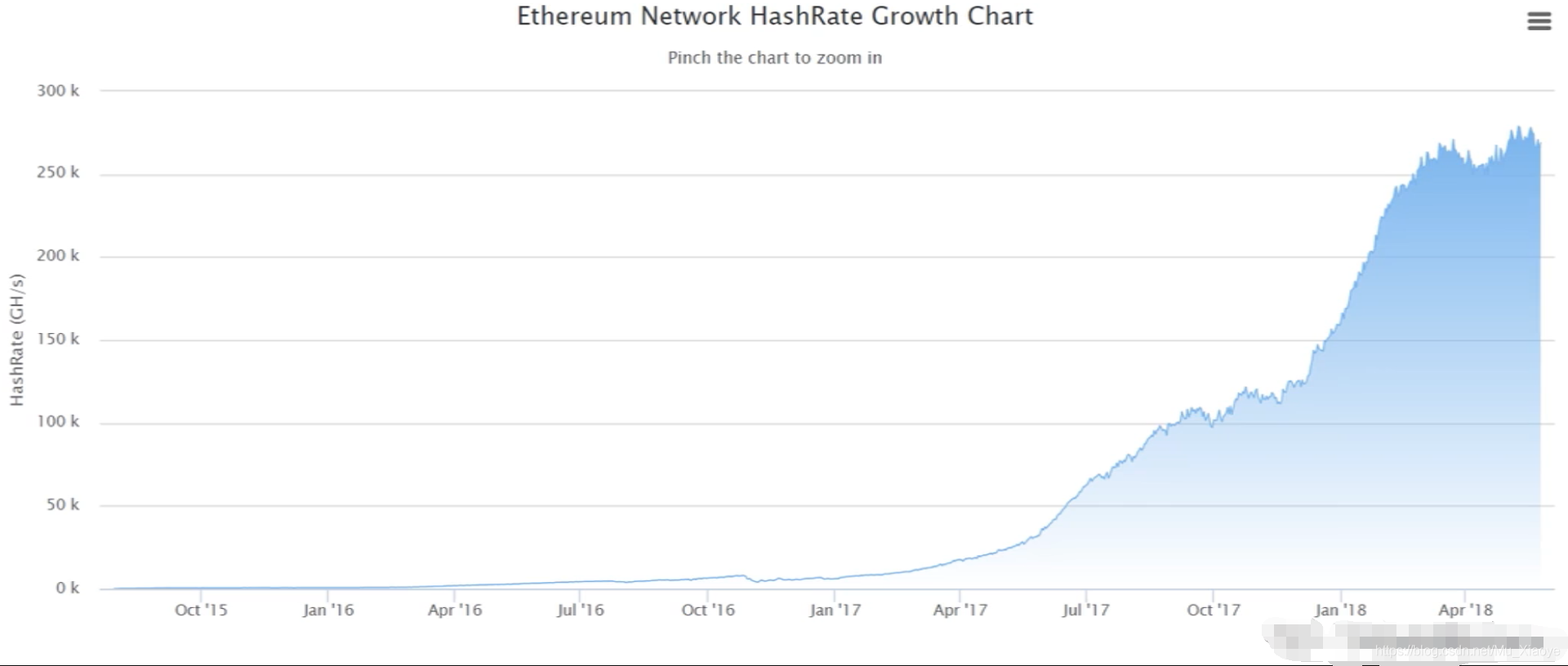
以太币Hash Rate变化情况(至2018年)
不同数字货币之间的哈希率是不能比的,比如以太坊中尝试一个nonce的难度比比特币的要大的多。
7.5 其他观点
本篇中挖矿算法设计一直趋向于让大众参与,这一才是公平的。且由于参与人员的分散,算力分散,也进一步使得系统更安全。 但同样一件事物,从不同观点看就有不同的看法。也有人认为让普通计算机参与挖矿是不安全的,像比特币那样,让中心化矿池参与挖矿才是安全的。为什么呢? 因为要攻击系统,需要购入大量只能进行特定货币挖矿的矿机通过算力进行强行51%攻击,而攻击成功后,必然导致该币种的价值跳水,攻击者投入的硬件成本将会全部打水漂。而如果让通用计算机也参与挖矿,发动攻击成本便大幅度降低,目前的大型互联网公司,将其服务器聚集起来进行攻击即可,而攻击完成后这些服务器仍然可以转而运行日常业务。因此,也有人认为,在挖矿上面,ASIC矿机“一统天下”才是最安全的方式。