基本介绍
在java中,LinkedList就是使用双向链表存储元素,既然是链表,那么也就知道了该数据结构擅长添加和删除。对于需要频繁添加和删除的,我们应该使用LinkedList而表示ArrayList
在开始介绍LinkedList之前,我们先来看一下该类的属性
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
这三个属性就分别表示集合元素个数,头节点,尾节点。
然后需要查看的就是类图,这是必不可少的!!!
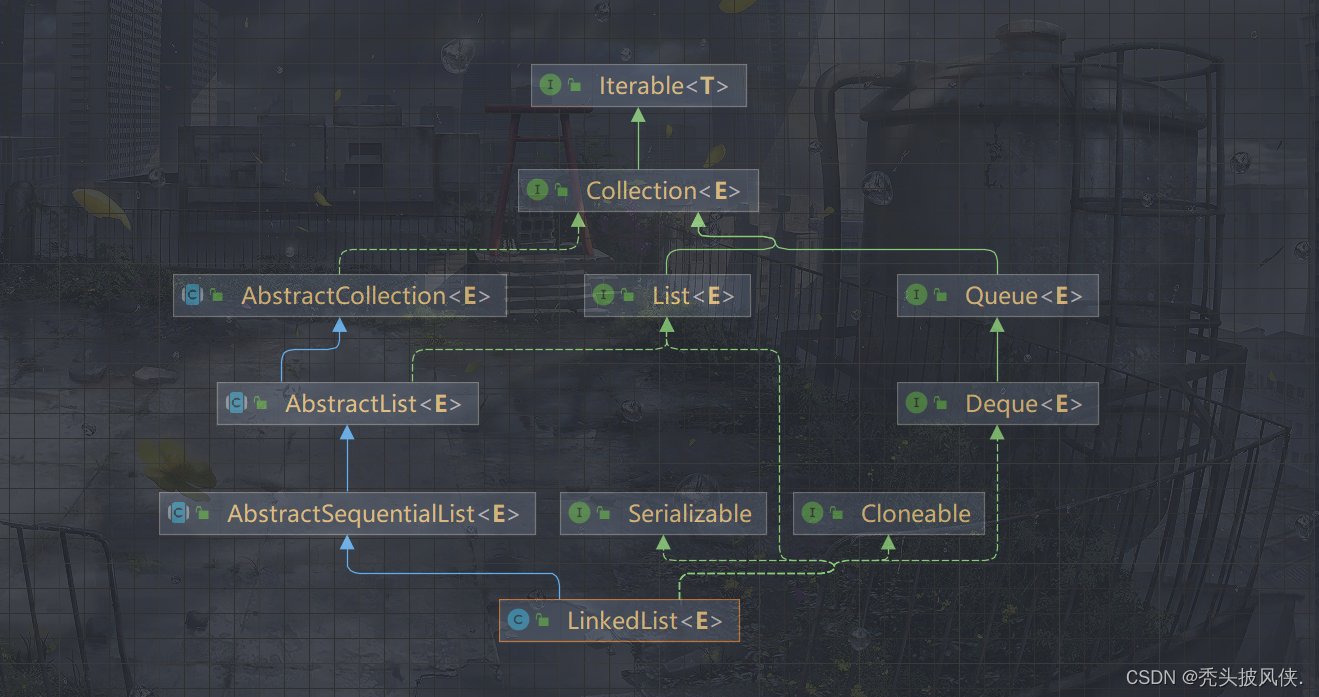
对于上面的类图,大家自行查看即可
还有一个需要说明,在LinkedList里面有一个内部类为Node,链表实际存储的就是Node
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
构造器
在LinkedList中,构造器就只有2个
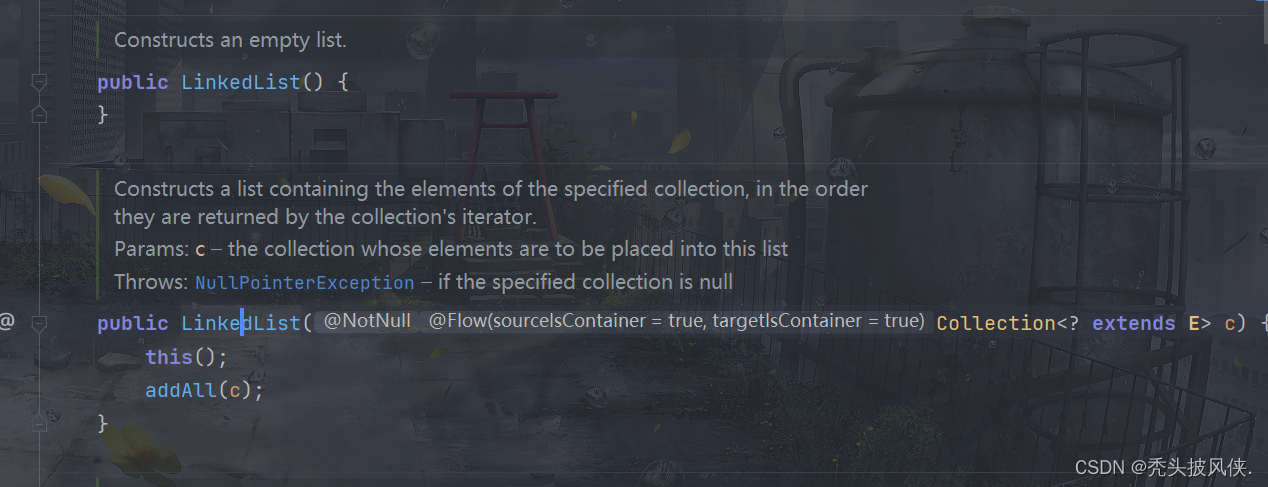
一个为无参构造器,一个传入一个集合,根据集合初始化,addAll方法后面说明
对于链表的操作都很简单,这里就简单看一下一些主要方法的源码,其他大家自行查看
基础方法
LinkedList基本所有的方法都用到了下面的几个基础方法,下面就来了解一下吧
linkFirst
void linkFirst(E e) 这个方法会将元素添加到链表作为表头
/**
* Links e as first element.
*/
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
上面代码就不用解释了吧,很简单,就是根据传入的元素创建Node,然后将其作为链表头
linkLast
void linkLast(E e) 就是将元素添加到链表尾部,作为新的表尾
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
该方法和linkFirst基本一样,不解释了。
linkBefore
void linkBefore(E e, Node succ),将元素e插入到非空节点succ之前
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
这个方法也容易理解,就是根据传入元素创建Node,然后修改对应Node的执行即可
unlinkFirst
E unlinkFirst(Node f) 这个方法会删除掉表头
/**
* Unlinks non-null first node f.
*/
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
该方法就是改变fisrt指针的指向即可
unlinkLast
unlinkLast(Node l) 这个方法就会删除掉链表尾部的那个元素
/**
* Unlinks non-null last node l.
*/
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
和unlinkFirst大同小异
unlink
E unlink(Node x) 会删除指定的节点
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
可以发现,该方法其实就是改变要删除节点的前一个节点和后一个节点的指针指向。
node
Node node(int index) 返回指定索引位置的Node
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
可以发现该方法实际就是遍历链表,有一个小优化就是如果index超过size的一半,那么就会从后面开始查找
indexOf
int indexOf(Object o) 返回某个元素在链表中第一次出现的位置
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
这个方法就是遍历链表,找到就返回索引
方法分析
上面说的那些方法,全部都是其他方法的基础,其他方法基本都是通过上面的那几个方法实现的。对于其他api,请参考下面内容
第一个是关于双端队列的方法,如果学过数据结构,那么这些方法也就知道是什么意思了
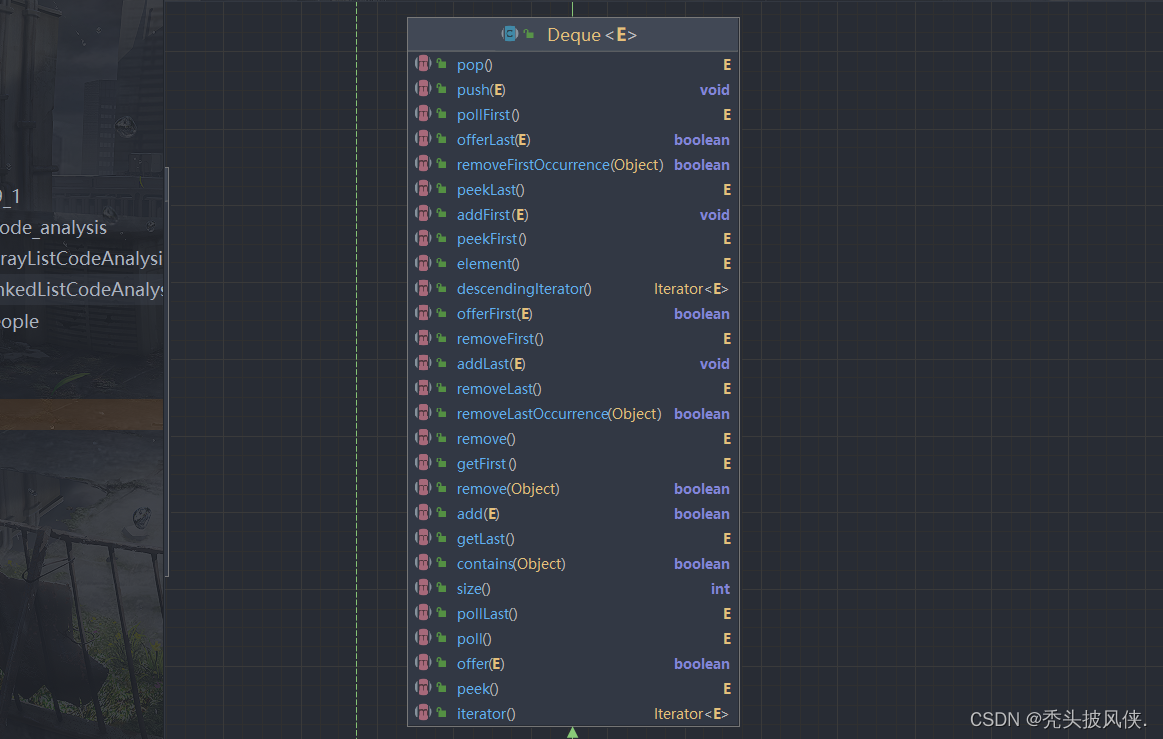
主要还有List里面的方法
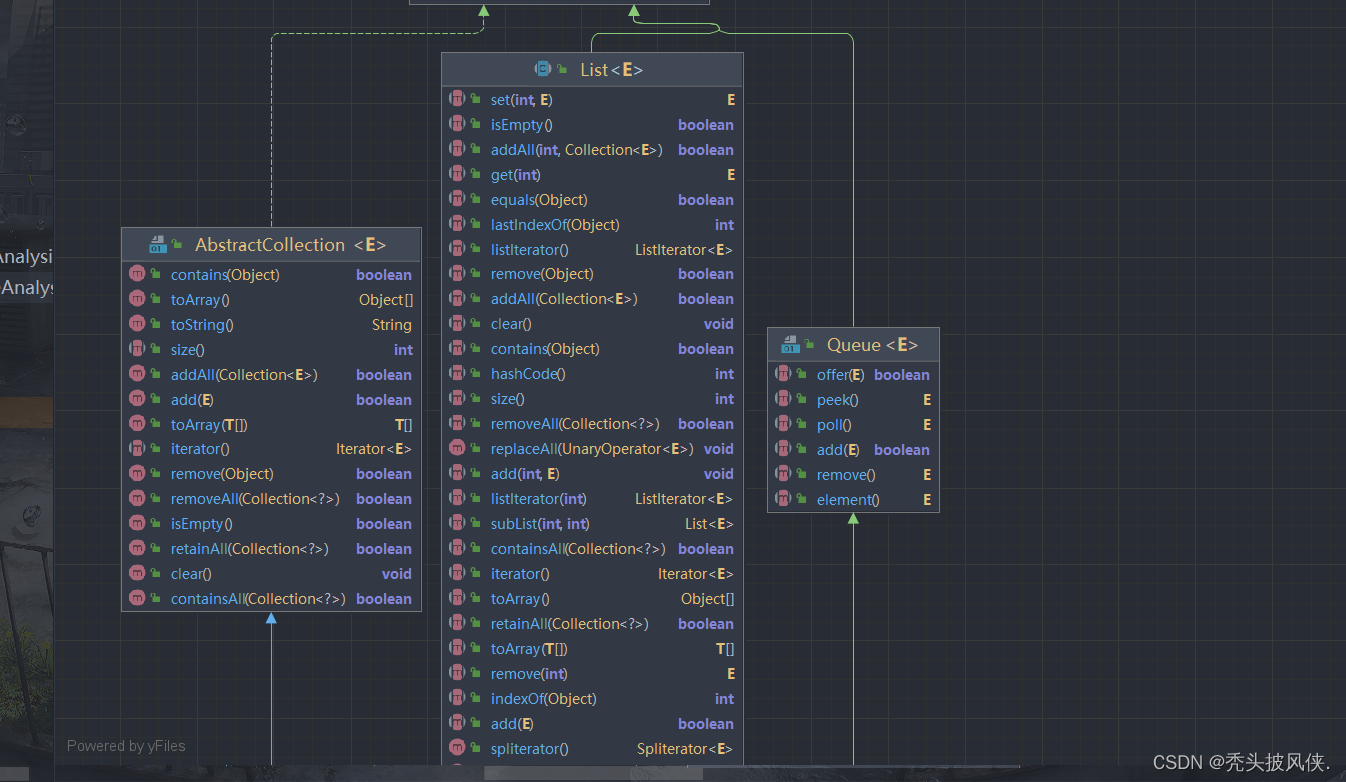
LinkedList实现了所有的方法,基础就是上面介绍的方法,其实就是通过移动链表的指向完成的
总结
LinkedList比较简单,就是关于链表的各种操作,学过数据结构那么就是小菜一碟了。