目录
一、Filebeat 基本介绍
1.1 Filebeat 是什么
Filebeat 是用于“转发”和“集中日志数据”的“轻量型数据采集器”Filebeat会监视指定的日志文件路径,收集日志事件并将数据转发到 ElasticSearch、Logstash、Redis、Kafka 存储服务器。
Filebeat 官网传送门:Filebeat overview | Filebeat Reference [8.6] | Elastic
1.2 Filebeat 主要组件
Filebeat 包含两个主要组件,输入和收割机,两个组件协同工作将文件尾部最新数据发送出去。
-
输入 Input:输入负责管理收割机从哪个路径查找所有可读取的资源。
-
收割机 Harvester:负责逐行读取单个文件的内容,然后将内容发送到输出。
1.3 Filebeat 工作流
当 filebeat 启动后,filebeat 过 Input 读取指定的日志路径,然后为该日志启动一个收割进程harvester,每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序spooler,处理程序会集合这些事件,最后 filebeat 会发送集合的数据到你指定的位置。
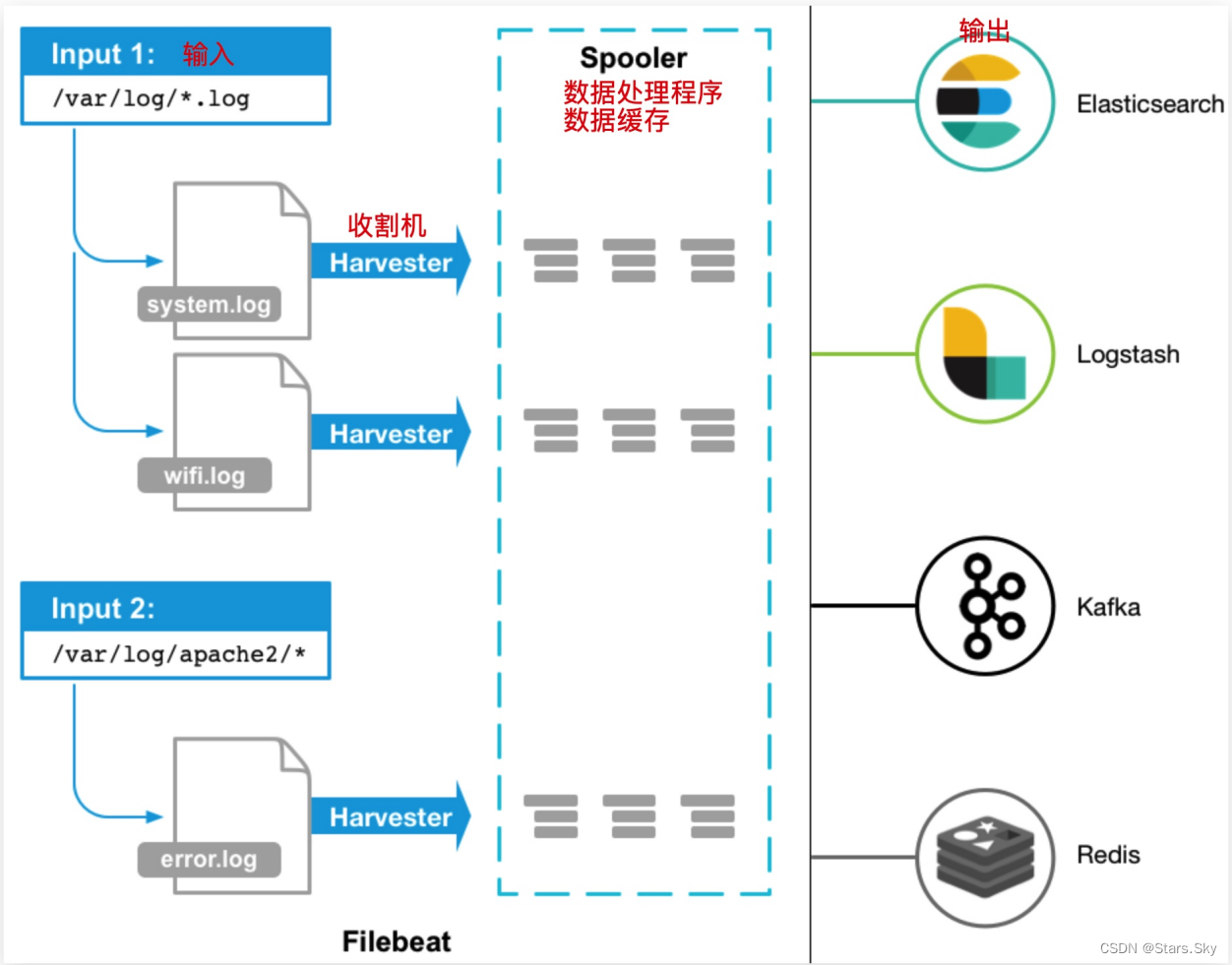
1.4 Filebeat 配置说明
 二、Filebeat 基本使用
二、Filebeat 基本使用
2.1 Filebeat 安装
Filebeat 7.8.1 下载地址:Filebeat 7.8.1 | Elastic

# 可以安装在任意节点(生产环境中则安装在需要收集日志的机器中)
[root@se-node3 ~]# rpm -ivh filebeat-7.8.1-x86_64.rpm
[root@se-node3 ~]# systemctl enable --now filebeat.service
2.2 Filebeat 配置
配置 Filebeat 从终端读入,从终端输出:
[root@se-node3 ~]# vim /etc/filebeat/test1.yml
filebeat.inputs:
- type: stdin
enabled: true
output.console:
pretty: true
enable: true输出一条测试语句:
[root@se-node3 ~]# filebeat -e -c /etc/filebeat/test1.yml
# -e:指定 Filebeat 在启动后将日志输出到控制台(标准输出)。
# -c:指定 Filebeat 加载配置文件的路径。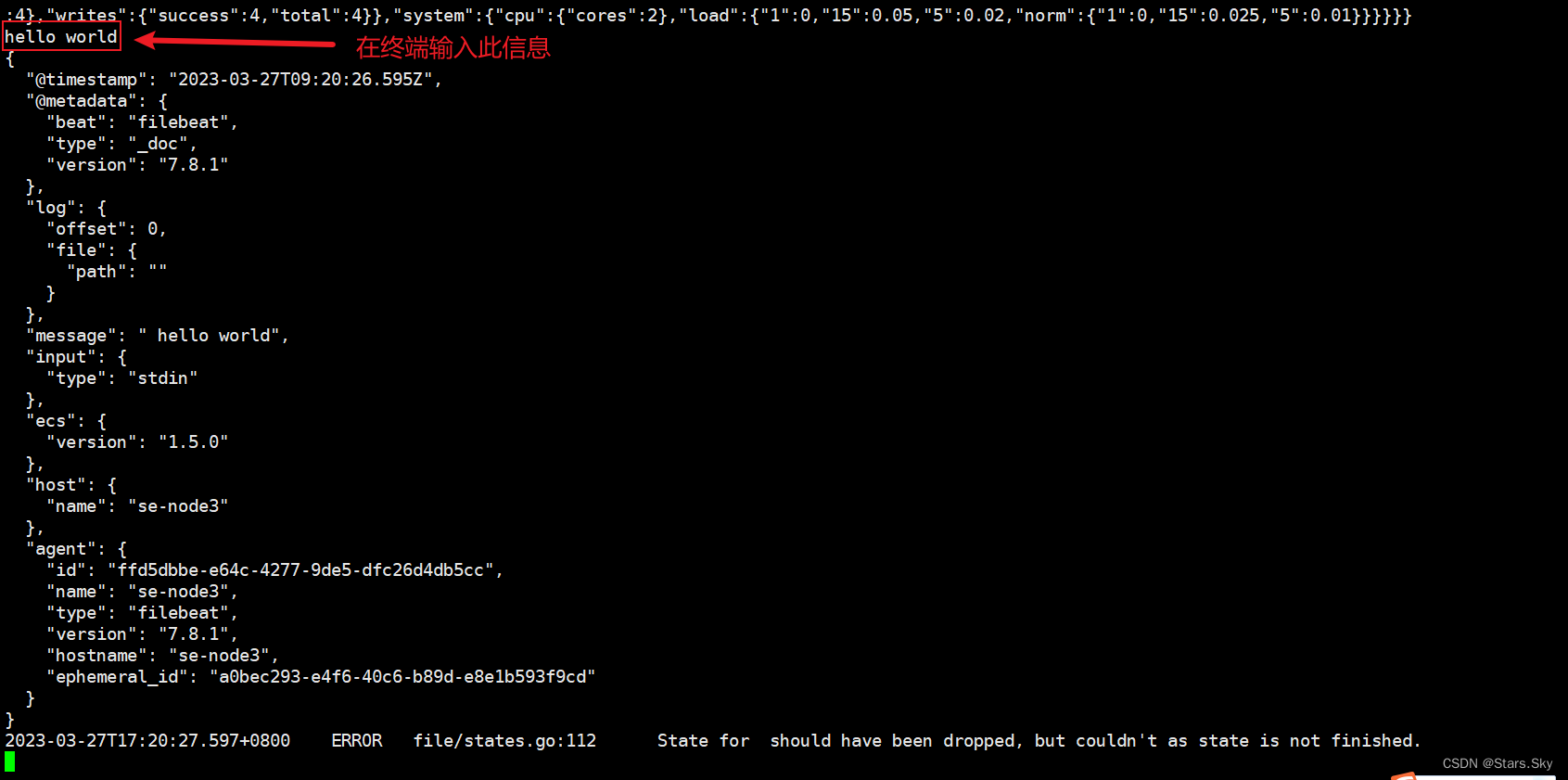
2.3 Filebeat 从文件读取
配置 filebeat 从文件中读取数据:
[root@se-node3 ~]# vim /etc/filebeat/test2.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
output.console:
pretty: true
enable: true
[root@se-node3 ~]# filebeat -e -c /etc/filebeat/test2.yml
新开一个终端,写入一个文件:
[root@se-node3 ~]# echo 123 >> /var/log/test2.log
可以看到收集到日志内容了:

2.4 Filebeat 输出至 ES 集群
输出读取内容至 ETasticsearch:
[root@se-node3 ~]# vim /etc/filebeat/test3.yml
filebeat.inputs:
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/*.log # 日志所在路径
output.elasticsearch: # 输出日志至 es
hosts: ["192.168.170.132:9200", "192.168.170.133:9200", "192.168.170.134:9200"] # es 集群 ip 和端口
enabled: true
[root@se-node3 ~]# filebeat -e -c /etc/filebeat/test3.yml
# 在另一个终端输入
[root@se-node3 ~]# echo 567 >> /var/log/test3.log
[root@se-node3 ~]# echo 567890 >> /var/log/test3.log查看数据:

2.5 Filebeat 自定义索引名称
默认 Filebeat 写入 ES 的索引名称为 filebeat-*,如果希望修改索引名称:
-
修改 filebeat 配置文件;
-
删除 ES 的索引;删除 kibana 的索引;
-
重启 filebeat 服务重新产生新的索引。
# 备份原来的文件
[root@se-node3 ~]# cp /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml_bak
[root@se-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/*.log # 日志所在路径
output.elasticsearch: # 输出日志至 es
hosts: ["192.168.170.132:9200", "192.168.170.133:9200", "192.168.170.134:9200"] # es 集群 ip 和端口
enabled: true
index: "system-%{[agent.version]}-%{+yyyy.MM.dd}" # 自定义索引名称
setup.ilm.enabled: false # 索引生命周期 ilm 功能默认开启,开启情况下索引名称只能为 filebeat-*
setup.template.name: "system" # 定义模板名称
setup.template.pattern: "system-*" # 定义模板的匹配索引名称
[root@se-node3 ~]# systemctl restart filebeat.service
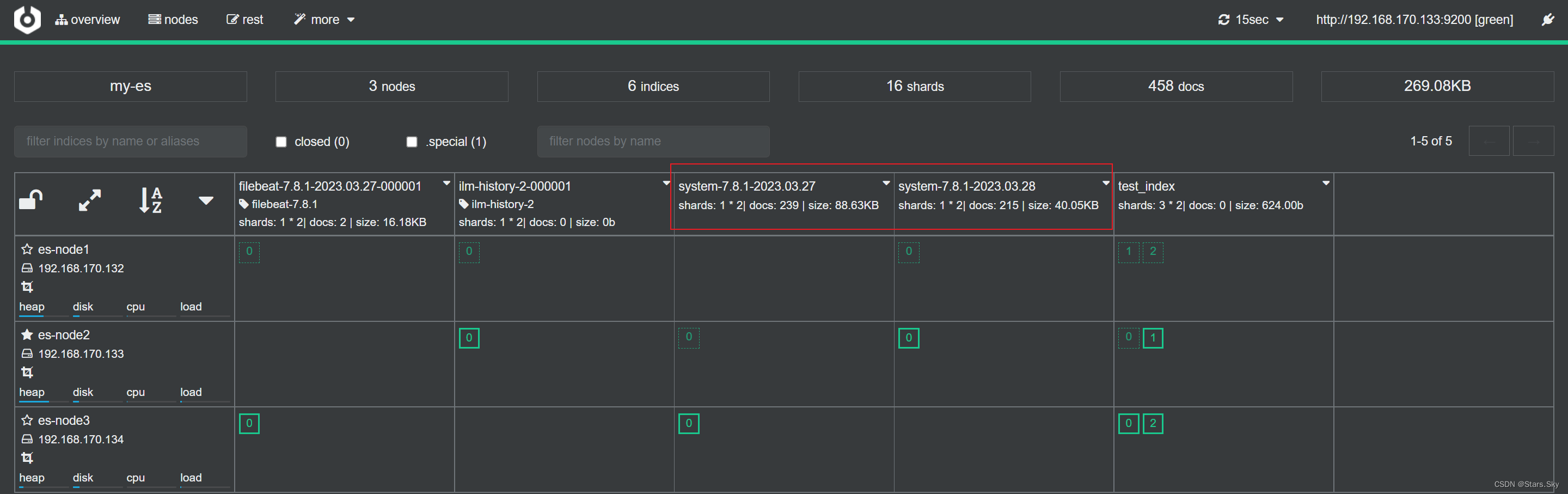
默认情况下 Filebeat 写入到 ES 的索引分片为 1,如果需要修订分片,可以通过如下两种方式:
方式一:修改 filebeat 配置文件,增加如下内容然后删除索引的模板,以及索引,重新产生数据:
setup.template.settings:
index.number_of_shards: 3 # 主分片数量
index.number_of_replicas: 1 # 副本数量方式二:使用 cerebro web页面修改
-
修改模板 settings 配置,调整分片以及副本;
-
删除模板关联的索引;
-
重启 filebeat 产生新的索引。
三、Filebeat 收集系统日志实践
3.1 系统日志有哪些
系统日志其实很宽泛、通常我们说的是 messagessecure、cron、dmesg、ssh、boot 等日志。
3.2 系统日志收集思路
系统中有很多日志,挨个配置收集就变得非常麻烦了。所以我们需要对这些日志进行统一、集中的管理。可以通过 rsyslog 将本地所有类型的日志都写入 /var/1og/xxx.log 文件中,然后使用 filebeat 对该文件进行收集即可。
3.3 系统日志收集架构图
rsyslog+filebeat --> elasticsearch 集群 --> kibana

3.4 系统日志收集实践
3.4.1 环境准备
| 主机名称 | IP | 已安装服务 |
| es-node1 | 192.168.170.132 | es、cerebro |
| es-node2 | 192.168.170.133 | es、Kibana |
| es-node3 | 192.168.170.134 | es、Filebeat |
3.4.2 配置 rsyslog
[root@es-node3 ~]# vim /etc/rsyslog.conf
*.* /var/log/allapp.log # 将本地所有类型的日志都保存到指定路径的文件里
[root@es-node3 ~]# systemctl restart rsyslog.service
3.4.3 配置 filebeat
编辑 filebeat 配置文件,将本地 /var/log./allapp.log 日志采集至 elasticsearch 集群中。
[root@se-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/allapp.log # 日志所在路径
output.elasticsearch: # 输出日志至 es
hosts: ["192.168.170.132:9200", "192.168.170.133:9200", "192.168.170.134:9200"] # es 集群 ip 和端口
enabled: true
index: "system-%{[agent.version]}-%{+yyyy.MM.dd}" # 自定义索引名称
setup.ilm.enabled: false # 索引生命周期 ilm 功能默认开启,开启情况下索引名称只能为 filebeat-*
setup.template.name: "system" # 定义模板名称
setup.template.pattern: "system-*" # 定义模板的匹配索引名称
[root@se-node3 ~]# systemctl restart filebeat.service
3.4.4 配置 Kibana
配置 kibana 读取 elasticsearch 索引中的数据,然后进行展示。
[root@es-node2 ~]# rpm -ivh kibana-7.8.1-x86_64.rpm
[root@es-node2 ~]# vim /etc/kibana/kibana.yml
# kibana 默认监听端口
server.port: 5601
# kibana 监听地址段
server.host: "0.0.0.0"
# kibana 内部域名
server.name: "elk.kibana"
# kibana 从 es 集群获取数据
elasticsearch.hosts:
- "http://192.168.170.132:9200"
- "http://192.168.170.133:9200"
- "http://192.168.170.134:9200"
# kibana 汉化
i18n.locale: "zh-CN"
[root@es-node2 ~]# systemctl enable --now kibana.service
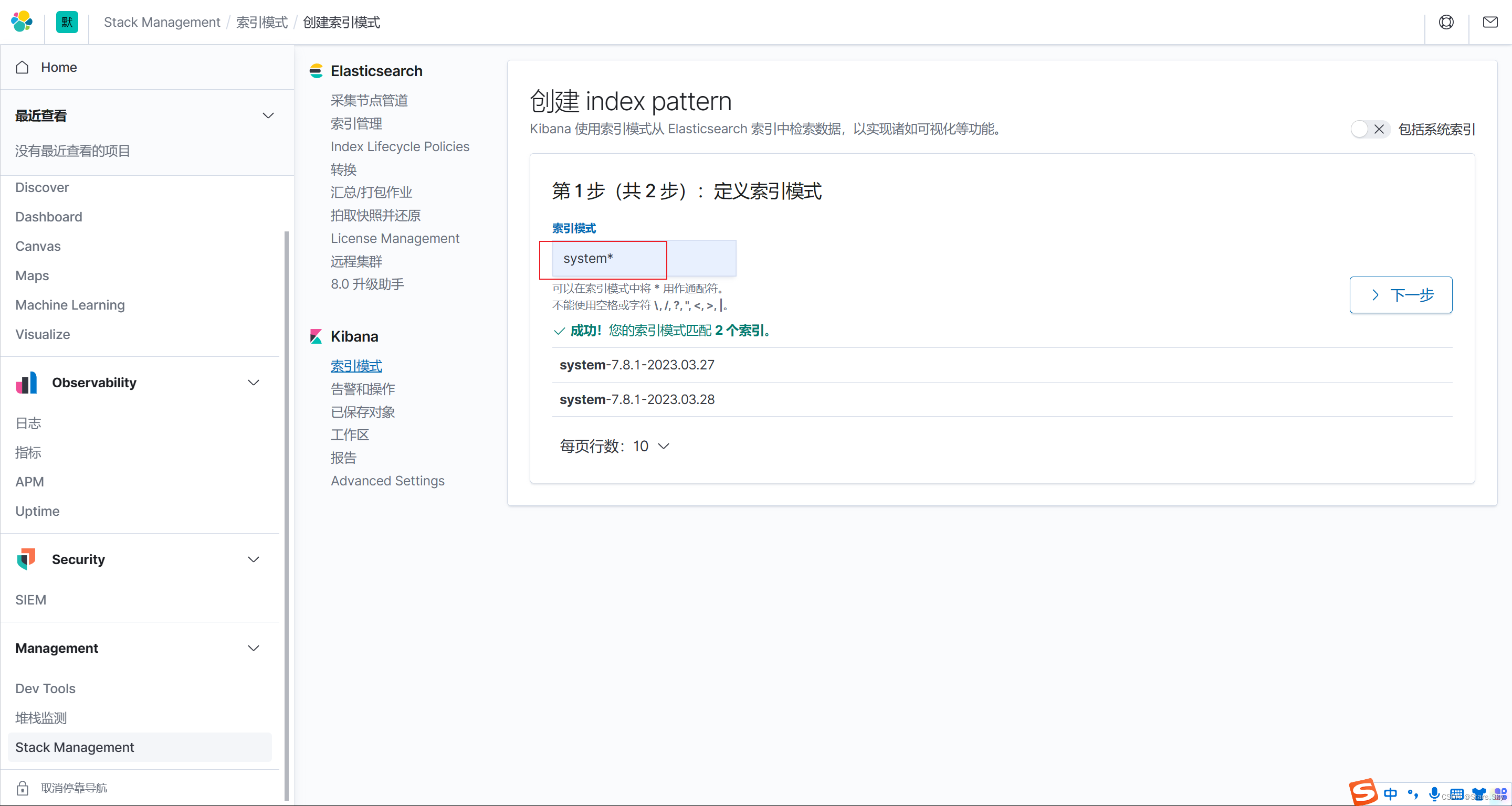
配置 kibana,创建索引:
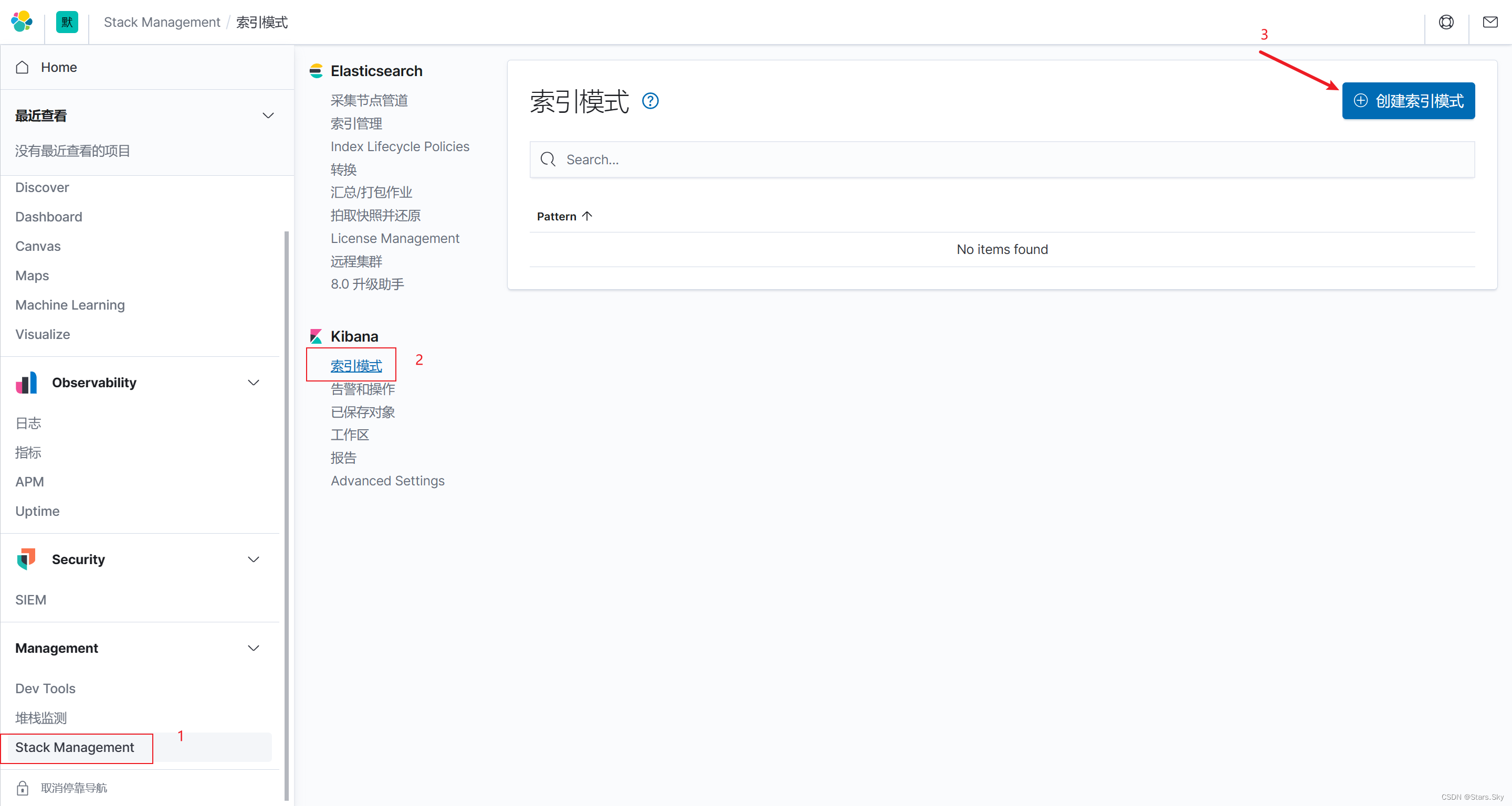
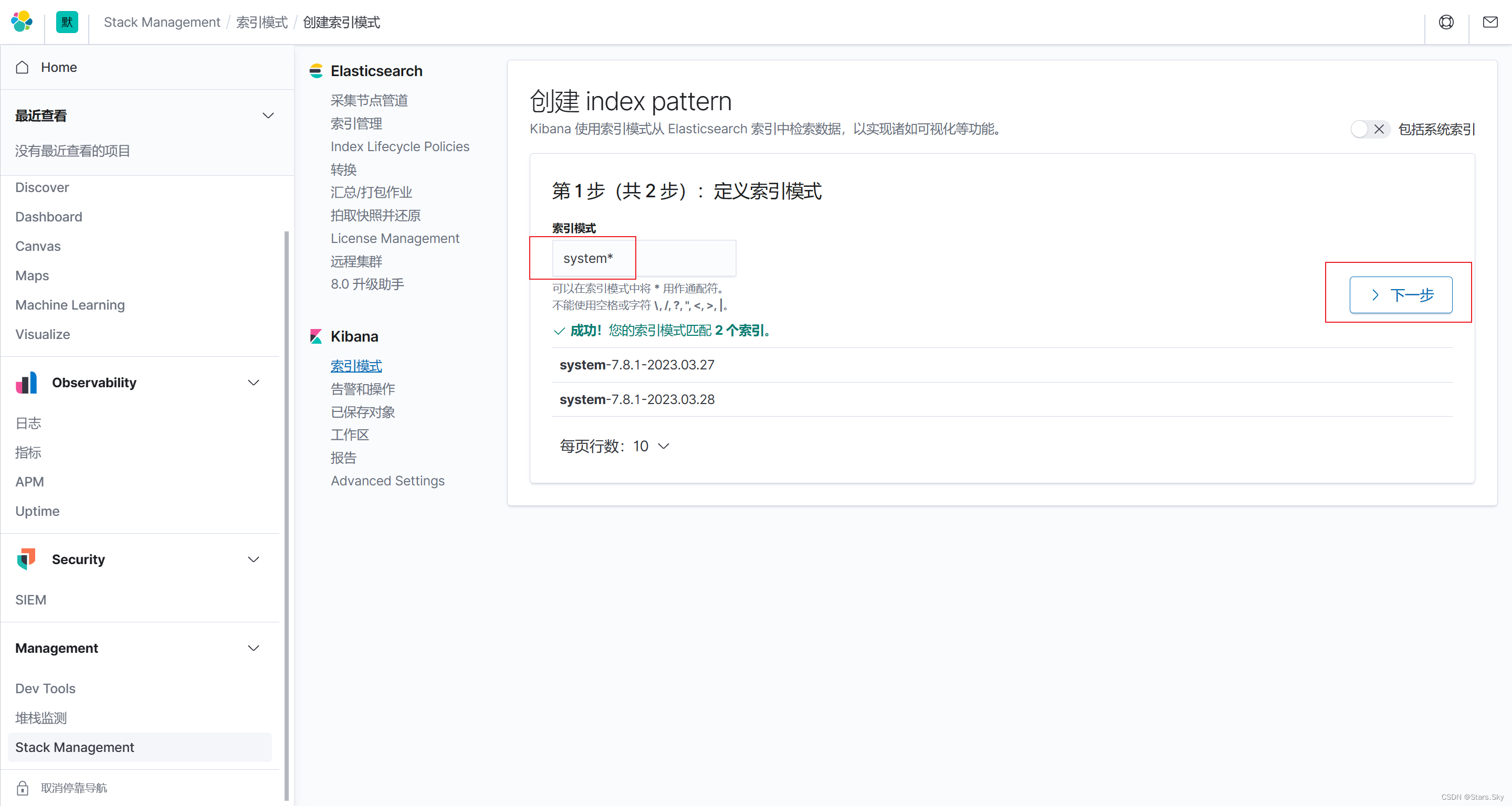 配置索引筛选名称:
配置索引筛选名称:
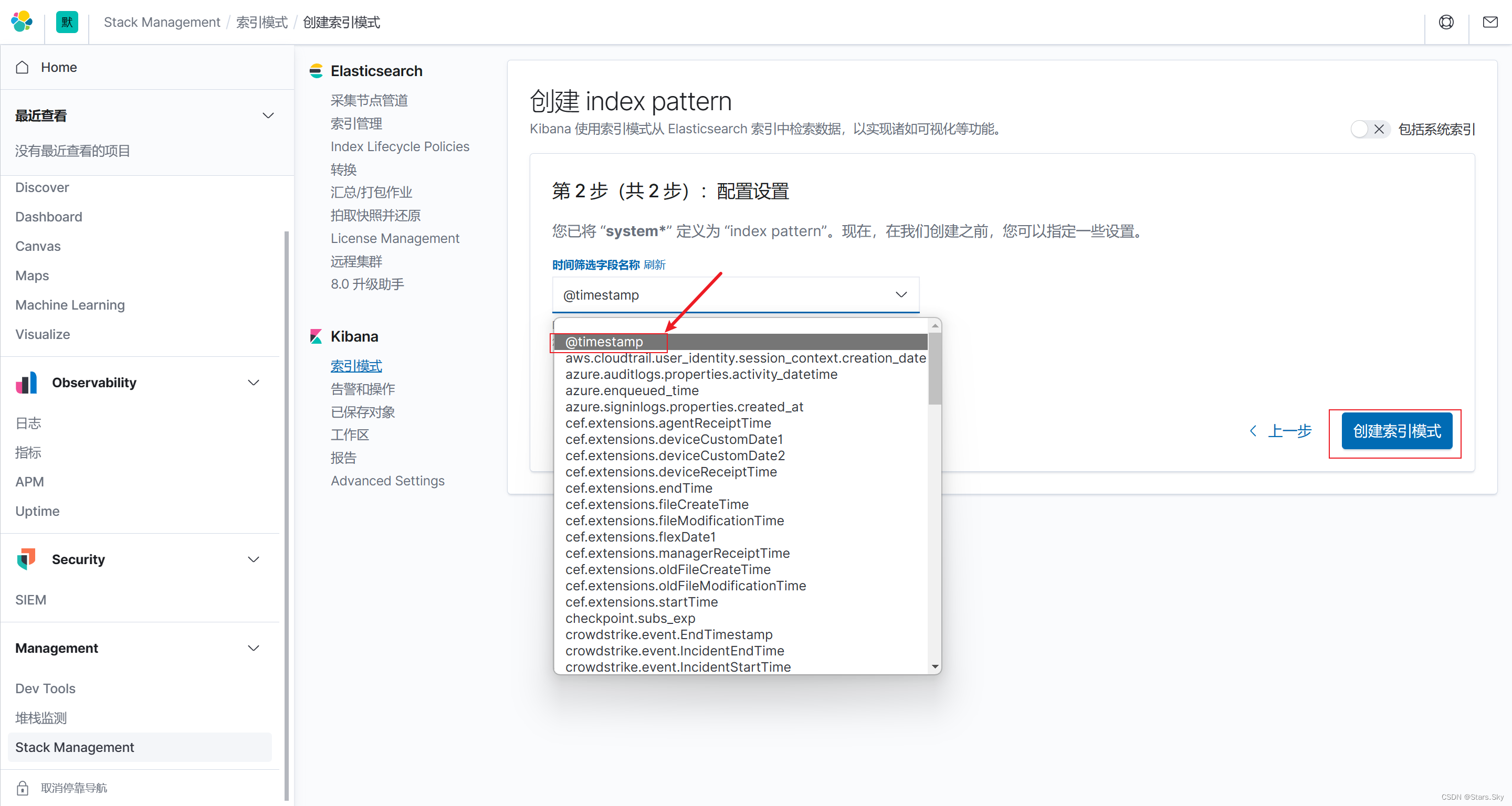 点击 discover 查看索引的日志数据:
点击 discover 查看索引的日志数据:

3.4.5 优化 filebeat
kibana 展示的结果上有很多 Debug 消息,其实该类消息无需收集,所以我们可以对收集的日志内容进行优化,只收集警告 WARN、ERR、sshd 相关的日志。
1. 修改 filebeat 配置文件如下:
[root@se-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/allapp.log # 日志所在路径
include_lines: ['^WARN', '^ERR', 'sshd', '^CROND', '^systemd'] # 只收集 warn、err、sshd 类型的日志格式
output.elasticsearch: # 输出日志至 es
hosts: ["192.168.170.132:9200", "192.168.170.133:9200", "192.168.170.134:9200"] # es 集群 ip 和端口
enabled: true
index: "system-%{[agent.version]}-%{+yyyy.MM.dd}" # 自定义索引名称
setup.ilm.enabled: false # 索引生命周期 ilm 功能默认开启,开启情况下索引名称只能为 filebeat-*
setup.template.name: "system" # 定义模板名称
setup.template.pattern: "system-*" # 定义模板的匹配索引名称
[root@se-node3 ~]# systemctl restart filebeat.service
2. 删除 ES 以及 kibana 的索引,然后重新生成 ES、Kibana 的索引:

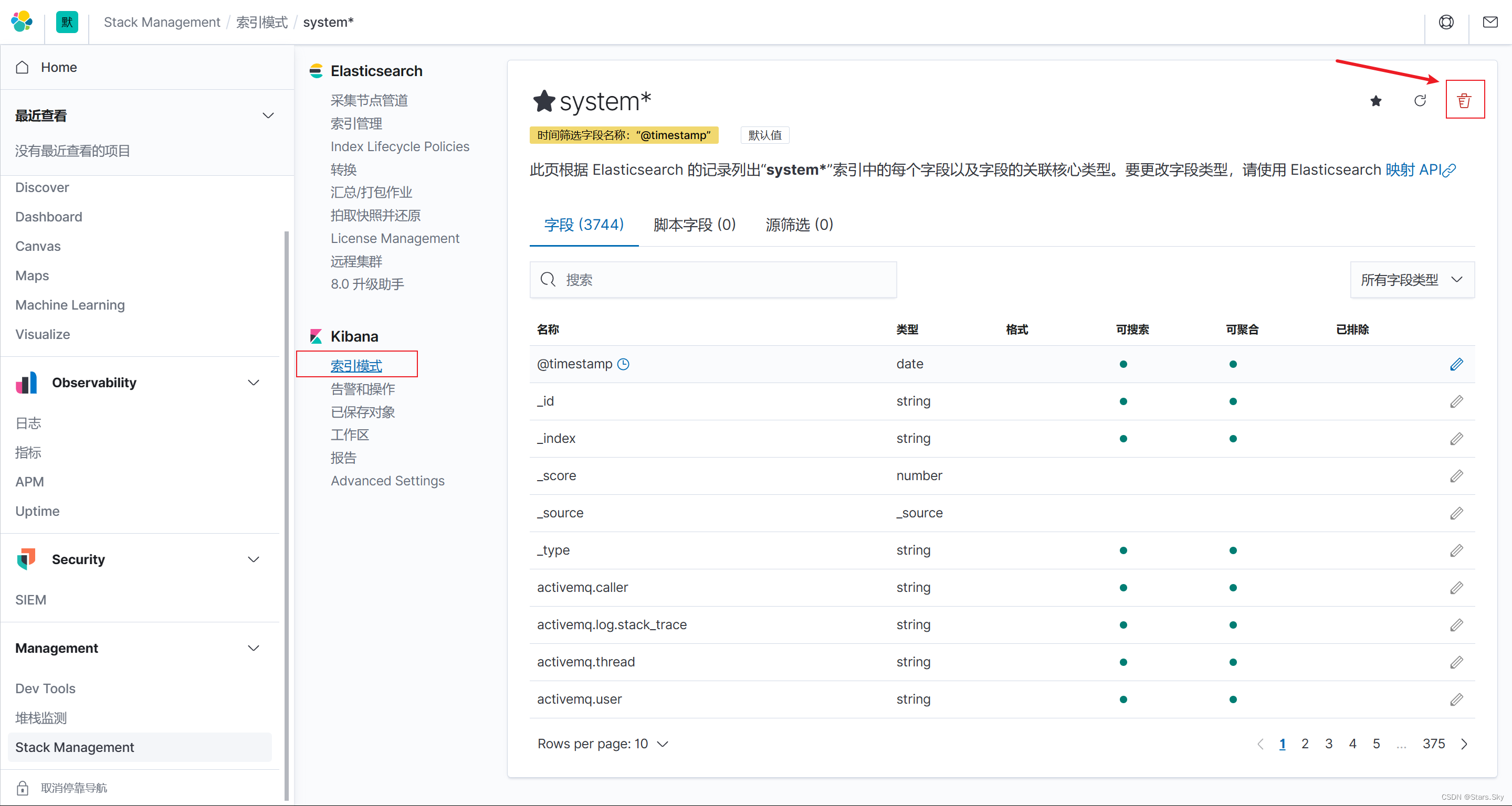 重新创建 kibana 索引:
重新创建 kibana 索引:
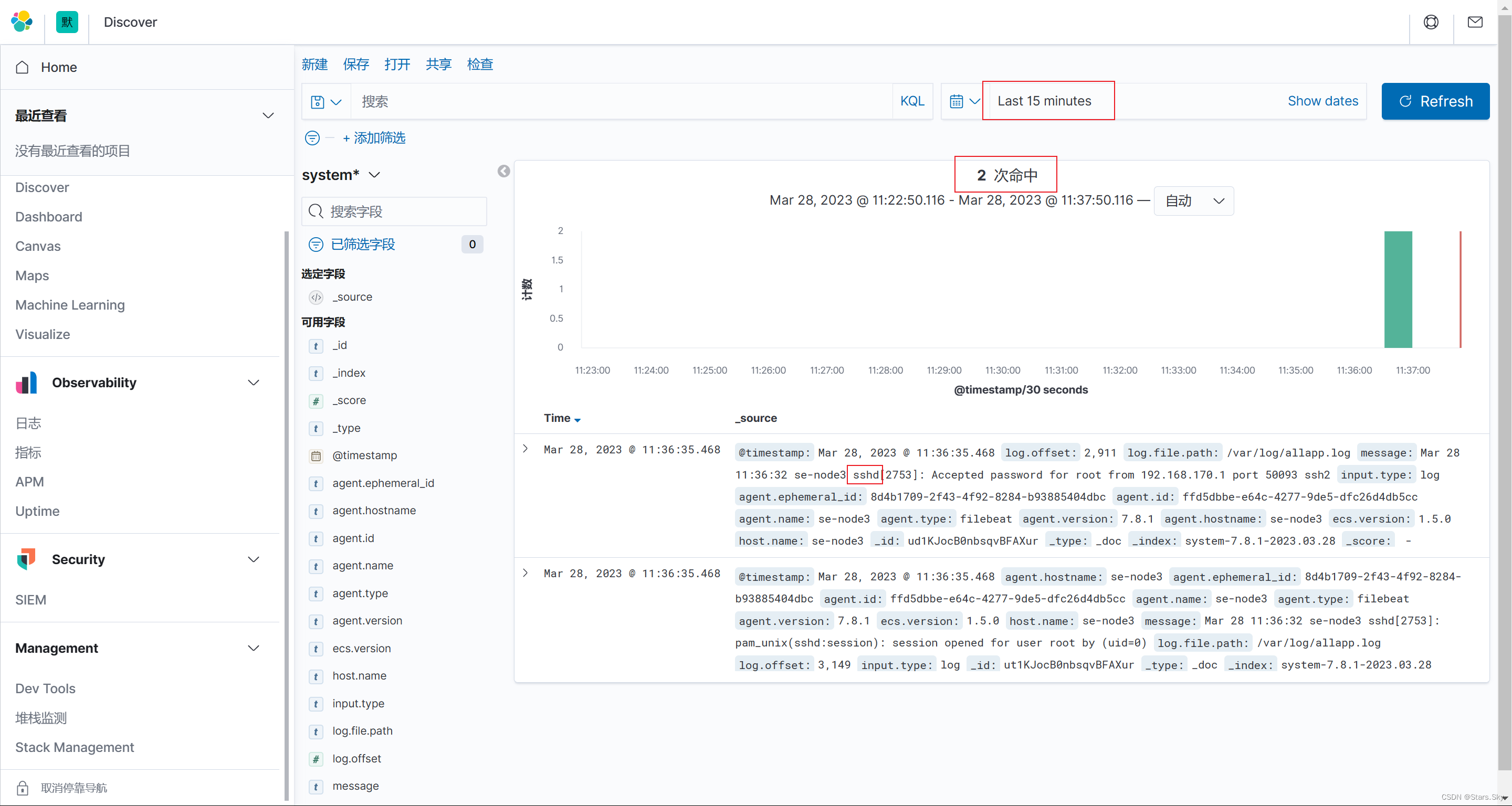
 再次查看,数据只有 sshd 的了:
再次查看,数据只有 sshd 的了:
上一篇文章:【Elastic (ELK) Stack 实战教程】04、ElasticSearch 集群进阶及优化_Stars.Sky的博客-CSDN博客
下一篇文章:【Elastic (ELK) Stack 实战教程】06、Filebeat 日志收集实践(下)_Stars.Sky的博客-CSDN博客