目录
一、ELK 架构面临的问题
1.1 耦合度过高
场景说明:假设目前系统日志输出很频繁,十分钟大约 5Gb,那么一个小时就是 30Gb;而应用服务器的存储空间一般默认 40Gb,所以通常会对应用服务器日志按小时轮转。如果我们的Logstash 故障了 1 小时,那么 Filebeat 就无法向 Logstash 发送日志,但我们的应用服务器每小时会对日志进行切割,那么也就意味着我们会丢失 1 小时的日志数据。
解决方法:使用消息队列,只要你的 filebeat 能够收集日志,队列能够存储足够长时间的数据,那后面 logstash 故障了,也不用担心,等 Logstash 修复后,日志依然能正常写入,也不会造成数据丢失,这样就完成了解耦。
1.2 性能瓶颈
场景说明:使用 filebeat 或 logstash 直接写入ES,那么日志频繁的被写入 ES 的情况下,可能会造成 ES 出现超时、丢失等情况。因为 ES 需要处理数据,存储数据,所以性能会变的很缓慢。
解决办法:使用消息队列,filebeat 或 Logstash 直接写入消息队列中就可以了,因为队列可以起到一个缓冲作用,最后我们的 logstash 根据 ES 的处理能力进行数据消费,匀速写入 ES 集群,这样能有效缓解 ES 写入性能的瓶颈。
二、ELK 对接 Redis 实践
使用 Redis 充当消息队列服务:
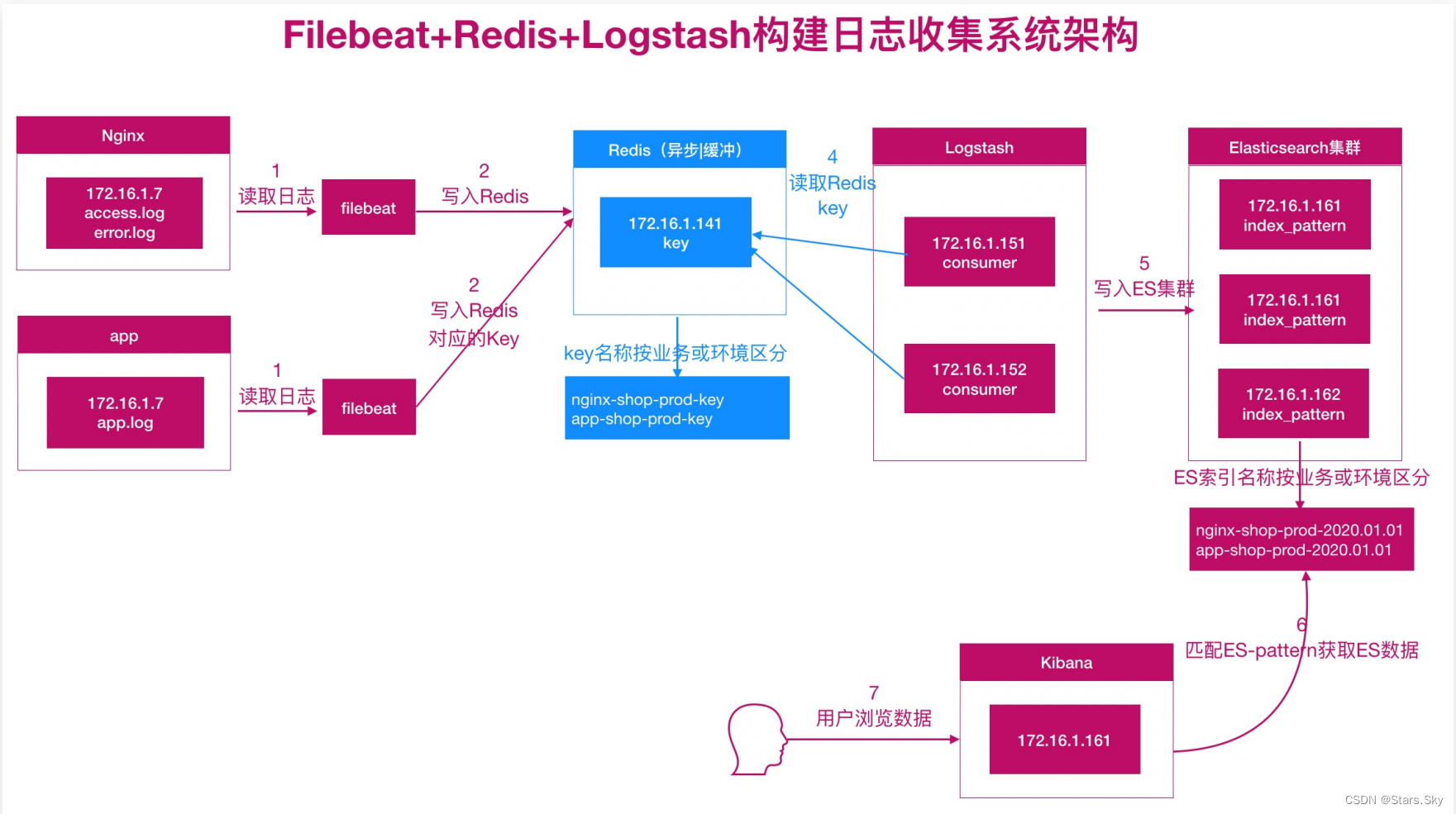
2.1 配置 Redis
2.1.1 安装 Redis
生产环境中使用二进制安装 Redis: CentOS 7 详细安装 Redis 6 图文教程_centos 7安装redis6需要哪些环境依赖_Stars.Sky的博客-CSDN博客
此次实验环境中我们使用 yum 安装更方便快捷:
[root@es-node2 ~]# yum install -y redis
2.1.2 配置 Redis
[root@es-node2 ~]# vim /etc/redis.conf
bind 0.0.0.0
requirepass Qwe123456
2.1.3 启动 Redis
[root@es-node2 ~]# systemctl enable --now redis
2.2 配置 Filebeat
[root@se-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/nginx/access.log # 日志所在路径
tags: ["access"]
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/nginx/error.log # 日志所在路径
tags: ["error"]
output.redis:
hosts: ["192.168.170.133:6379"] # redis地址
password: "Qwe123456" #redis密码
timeout: 5 #连接超时时间
db: 0 #写入db0库中
keys: #存储的key名称
- key: "nginx_access"
when.contains:
tags: "access"
- key: "nginx_error"
when.contains:
tags: "error"
[root@se-node3 ~]# systemctl restart filebeat.service
2.3 配置 Logstash
[root@es-node1 ~]# vim /etc/logstash/conf.d/test6.conf
input {
redis {
host => ["192.168.170.133"]
port => "6379"
password => "Qwe123456"
data_type => "list"
key => "nginx_access"
db => "0"
}
redis {
host => ["192.168.170.133"]
port => "6379"
password => "Qwe123456"
data_type => "list"
key => "nginx_error"
db => "0"
}
}
filter {
if "access" in [tags][0] {
grok {
match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)" }
}
useragent {
source => "useragent"
target => "useragent"
}
geoip {
source => "clientip"
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => ["bytes","integer"]
convert => ["response_time", "float"]
convert => ["upstream_response_time", "float"]
remove_field => ["message"]
add_field => { "target_index" => "redis-logstash-nginx-access-%{+YYYY.MM.dd}" }
}
# 提取 referrer 具体的域名 /^"http/
if [referrer] =~ /^"http/ {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }
}
}
# 提取用户请求资源类型以及资源 ID 编号
if "sky.com" in [referrer_host] {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:sky_type}/%{NOTSPACE:sky_res_id})?"' }
}
}
}
else if "error" in [tags][0] {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
add_field => { "target_index" => "redis-logstash-nginx-error-%{+YYYY.MM.dd}" }
}
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["192.168.170.132:9200","192.168.170.133:9200","192.168.170.134:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
}
[root@es-node1 ~]# logstash -f /etc/logstash/conf.d/test6.conf -r 2.4 数据消费
在上面描述的场景中,Filebeat 收集的日志文件数据会被存储到 Redis。接着,Logstash 从 Redis 中获取数据并将其传输到 Elasticsearch。这是一个流水线式的处理过程,数据在流动过程中被消费。
Redis 作为一个中间存储,当 Logstash 成功地从 Redis 中读取数据并将其传输到 Elasticsearch 时,Logstash 会将这些数据从 Redis 中删除。这是因为你的配置文件中使用了 data_type => "list",这意味着当 Logstash 从 Redis 中获取数据时,它会使用类似于 LPOP 或 RPOP 的命令将数据从列表中弹出。这样一来,Redis 中的数据会被不断地消费,因此当你使用 keys * 命令查询时可能看不到数据。
如果你希望检查 Redis 中是否有数据流入,你可以在 Filebeat 向 Redis 发送数据的同时进行查询。但是,请注意,当 Logstash 正在消费数据时,这些数据很可能会迅速从 Redis 中删除。所以,你可能需要在 Filebeat 和 Logstash 之间调整数据发送速率,以便在 Redis 中查看数据。不过,这种做法并不是长期监控 Redis 数据的推荐方法,因为它可能会影响到整个流水线的性能。
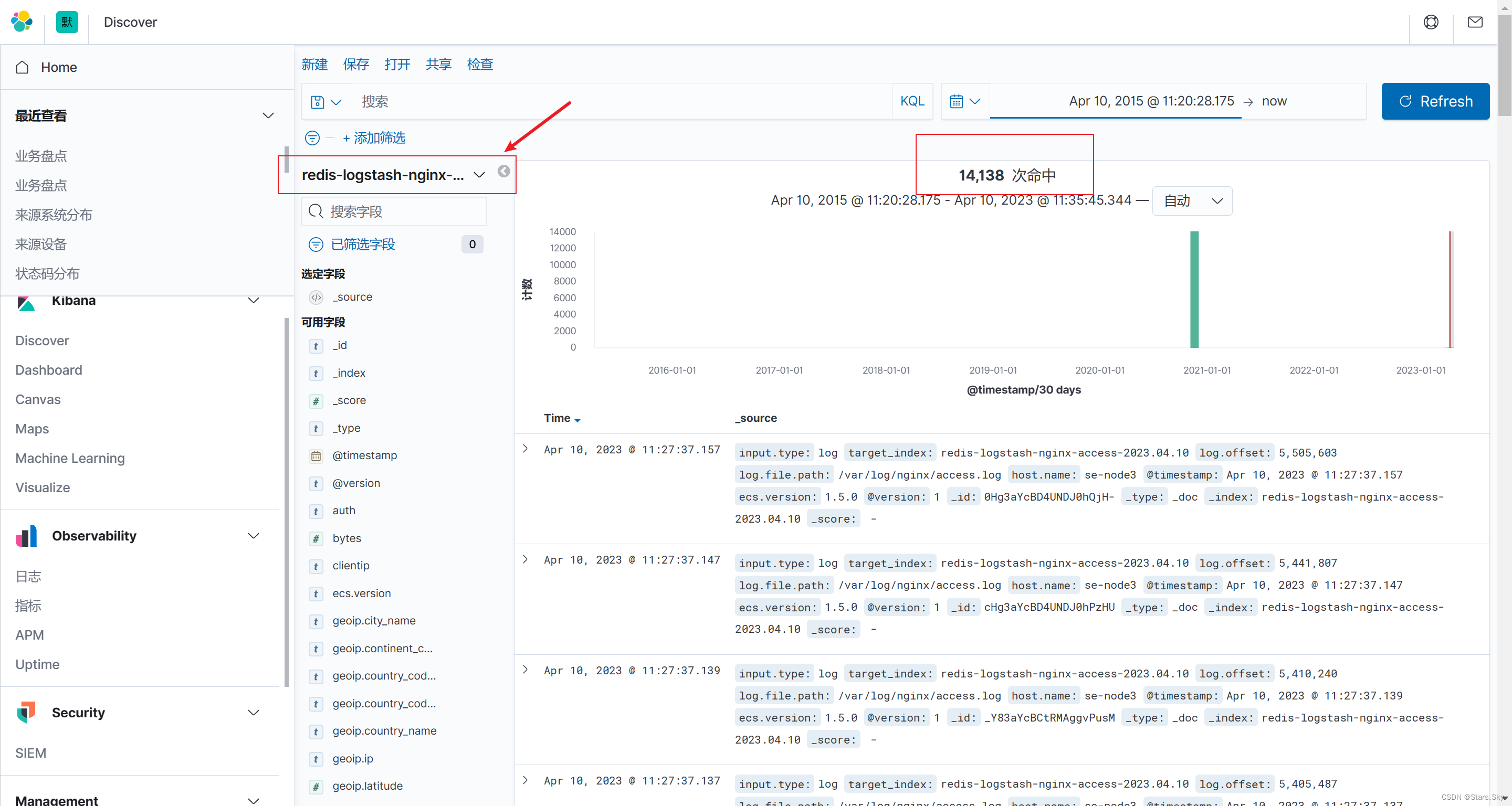
2.5 配置 kibana
创建 kibana 索引:
三、消息队列基本概述
3.1 什么是消息队列
-
消息 Message:比如两个设备进行数据的传输,所传输的任何数据,都可以称为消息。
-
队列 Queue: 是一种先进先出的数据结构,类似排队买票机制。
而消息队列 MQ:是用来保存消息的一个容器;消息队列需要提供两个功能接口供外部调用。
-
生产者 Producer:把数据放到消息队列叫生产者。
-
消费者 Consumer:从消息队列里取数据叫做消费者。
3.2 消息队列的分类
MQ 主要分为两类:点对点、发布/订阅。
-
点对点:消息队列 Queue、发送者 sender、接收者 Receiver。
一个生产者生产的消息只能有一个消费者,消息一旦被消费,消息就不在消息队列中了。比如打电话,当消息发送到消息队列后只能被一个接收者接收,当接收完毕消息则销毁。
-
发布/订阅:消息队列 Queue、发布者 PubTisher、订阅者 subscriber、主题 Topic。
每个消息可以有多个消费者,彼此互不影响。比如我使用公众号发布一篇文章,关注我的人都能看到,即发布到消息队列的消息能被多个接收者(订阅者)接收。
3.3 消息队列使用场景
消息队列最主要有三个场景,总结为 6 个字:解耦、异步、削峰。
3.3.1 解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。
传统模式的缺点:
-
假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
-
订单系统与库存系统耦合。
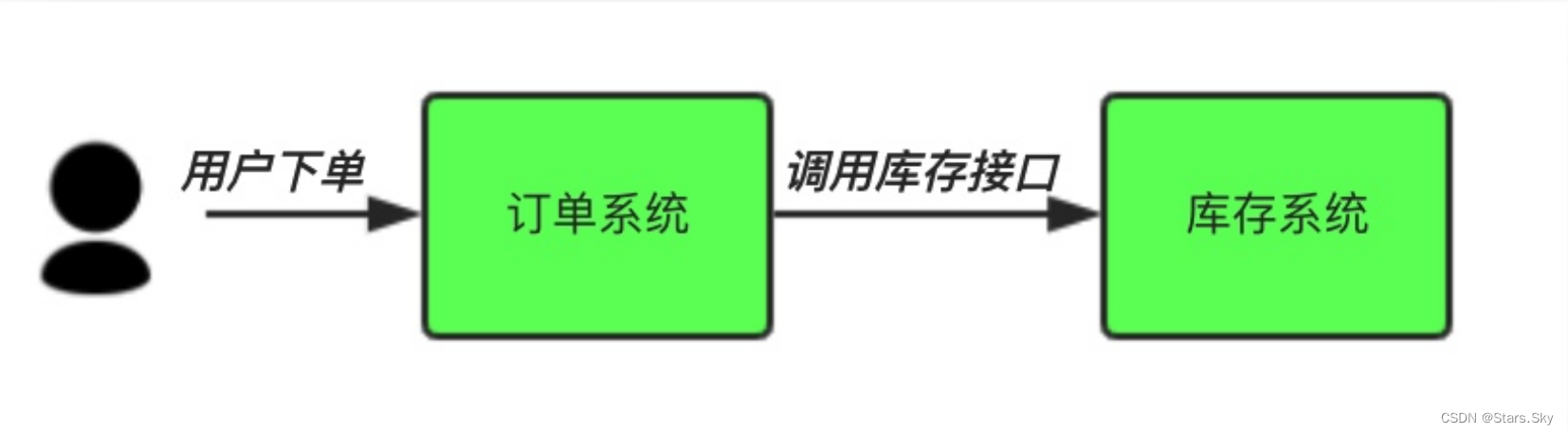
中间件模式:
-
订单系统:用户下单后,订单系统完将消息写入消息队列,返回用户订单下单成功。
-
库存系统:订阅下单的消息,获取下单信息,库存系统根据下单信息,进行库存操作。
-
假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。程序解耦 。
3.3.2 异步
场景说明:用户注册后,需要发注册邮件和注册短信。将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。
传统模式的缺点:系统的性能(并发量,吞吐量,响应时间)会有瓶颈。
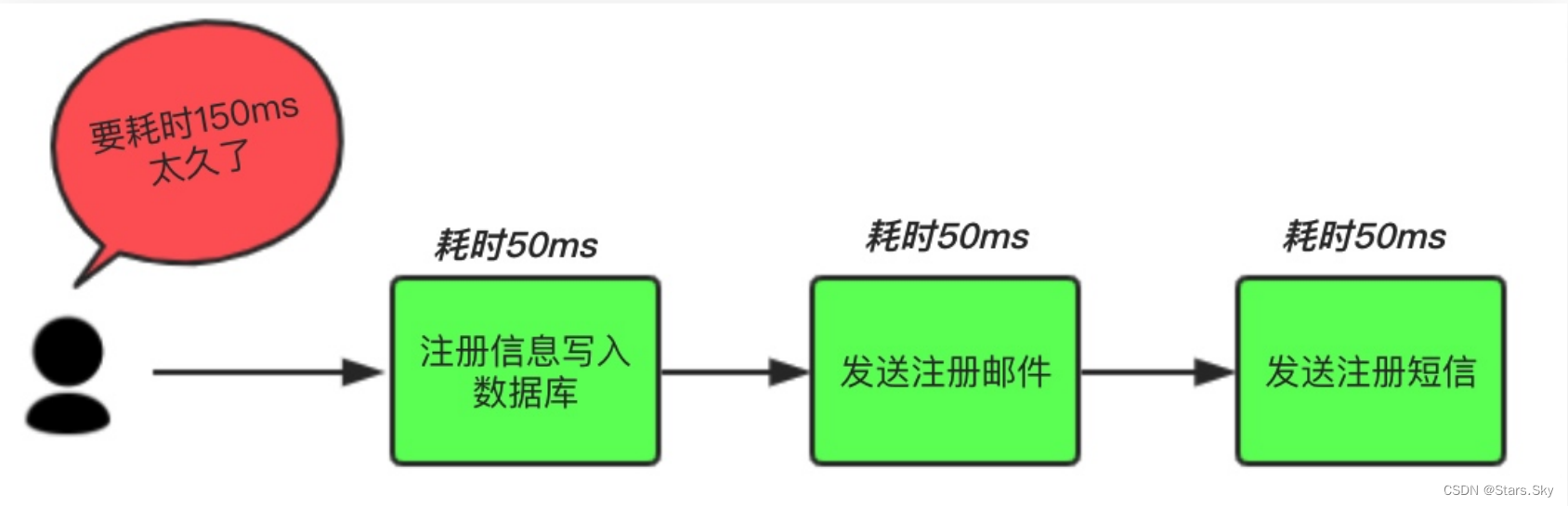
中间件模式:将不是必须的业务逻辑,异步处理。改造后的架构如下:
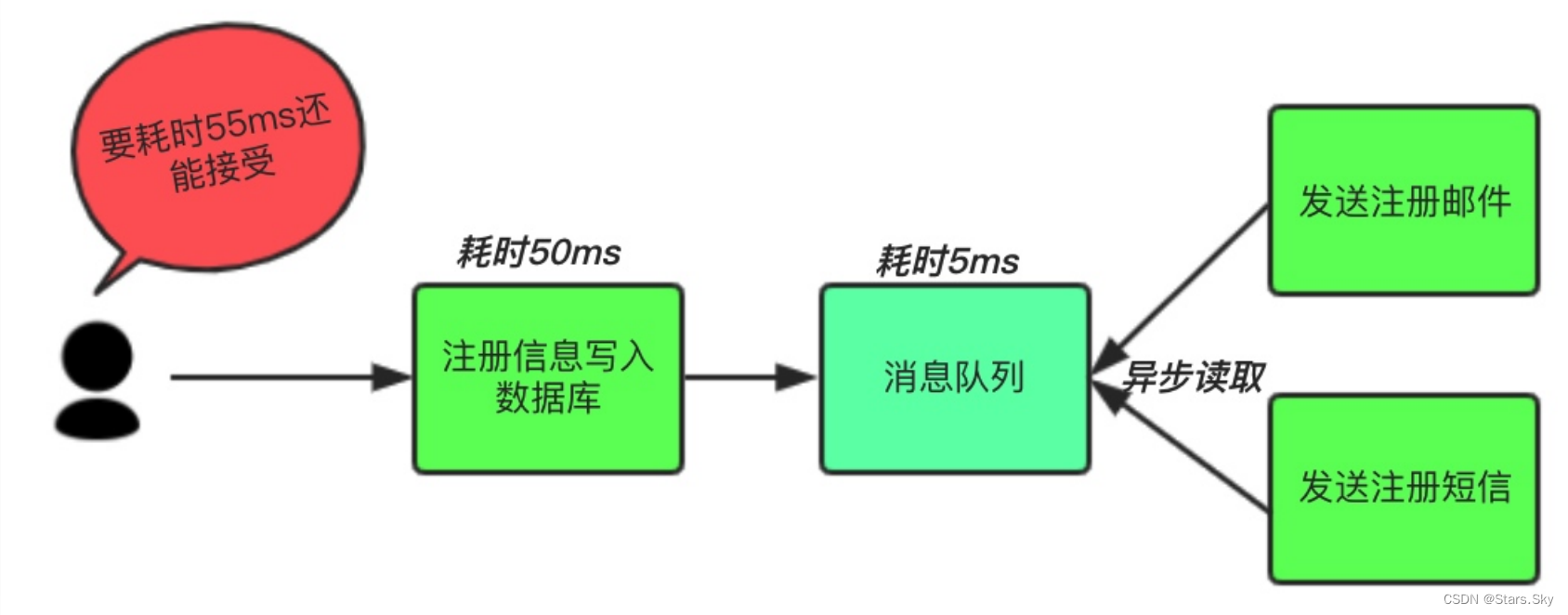
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是 50 毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是 50ms 或 55ms。
3.3.3 削峰
场景说明:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。
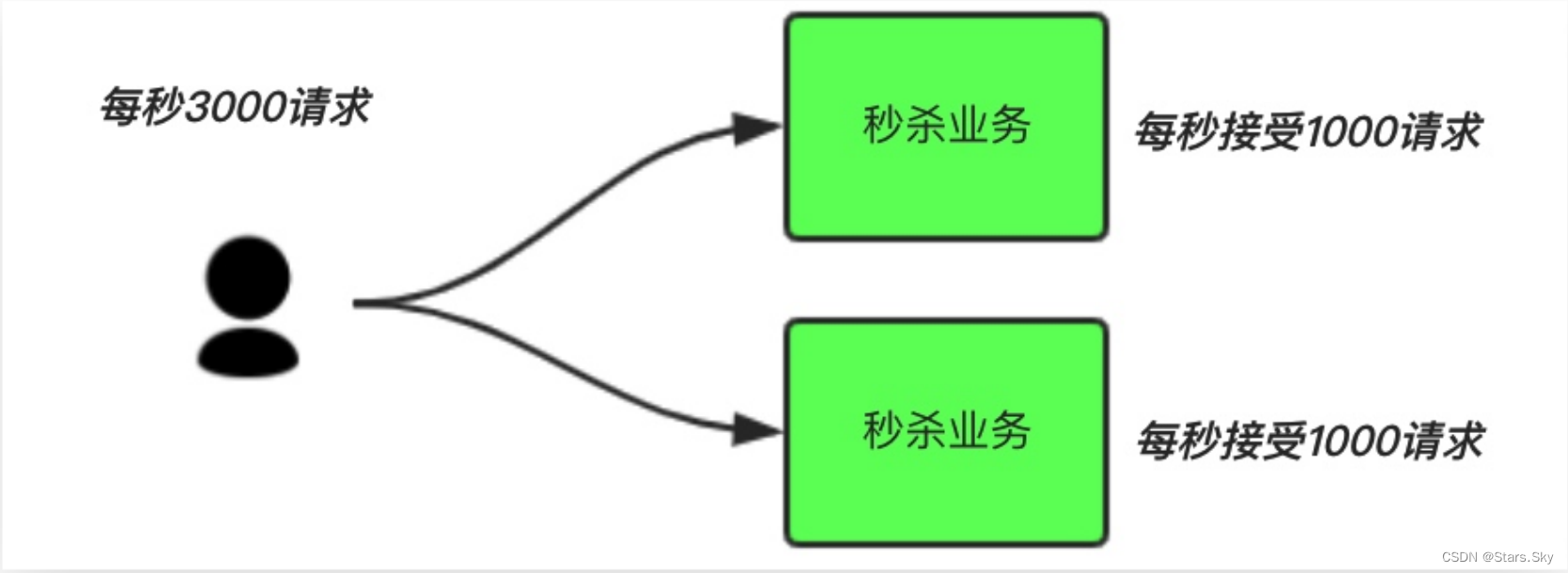
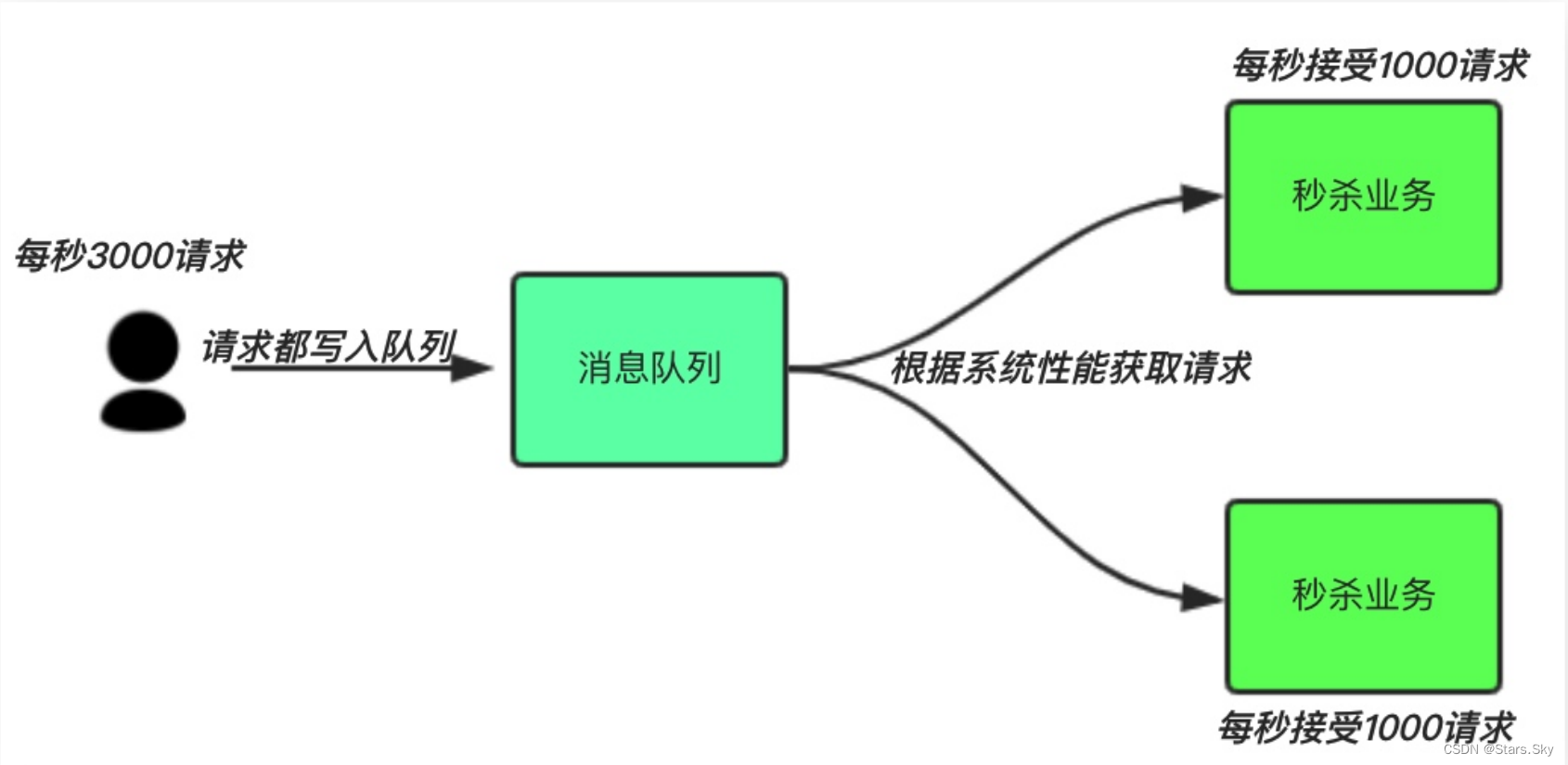
中间件模式:
-
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量限制,则直接抛弃用户请求或跳转到错误页面。
-
秒杀业务可以根据自身能处理的能力获取消息队列数据,然后做后续处理。这样即使有 8000 个请求也不会造成秒杀业务奔溃。
四、Kafka 概述及集群部署
PS:我是在原来的 es-node1 和 es-node3 这两天机器上安装了 kafka、Zookeeper。
4.1 Kafka 集群安装
可以查看我的这篇文章了解 kafka 及 kafka 集群的安装与使用:【Kafka 3.x 初级】01、Kafka 概述及入门_Stars.Sky的博客-CSDN博客
4.2 Zookeeper 集群安装
可以查看我的这篇文章了解 Zookeeper 及 zookeeper 集群的安装与使用:
【Zookeeper 初级】02、Zookeeper 集群部署_Stars.Sky的博客-CSDN博客
五、Kafka-eagle 图形界面安装
官方安装文档:2.Install on Linux/macOS - Kafka Eagle (kafka-eagle.org)
Kafka-eagle 下载地址:Tags · smartloli/kafka-eagle-bin · GitHub
5.1 安装 JDK
可以查看我的这篇文章:Linux 部署 JDK+MySQL+Tomcat 详细过程_移植mysql+tomcat_Stars.Sky的博客-CSDN博客
5.2 安装 Kafka-eagle
[root@es-node2 ~]# tar -zxvf kafka-eagle-bin-3.0.2.tar.gz -C /usr/local/
[root@es-node2 ~]# cd /usr/local/kafka-eagle-bin-3.0.2/
[root@es-node2 /usr/local/kafka-eagle-bin-3.0.2]# tar -zxvf efak-web-3.0.2-bin.tar.gz
[root@es-node2 ~]# vim /etc/profile
export KE_HOME=/usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2
export PATH=$KE_HOME/bin:$PATH
[root@es-node2 ~]# source /etc/profile
5.3 配置 Kafka-eagle
[root@es-node2 ~]# vim /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/conf/system-config.properties
######################################
# 填写 zookeeper 集群环境信息,我们只有一套 zookeeper 集群,所以把 cluster2 注释掉
efak.zk.cluster.alias=cluster1
cluster1.zk.list=es-node1:2181,es-node3:2181/kafka
#cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181
######################################
# kafka sqlite jdbc driver address
######################################
# kafka sqlite 数据库地址(需要修改存储路径)
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org
######################################
# kafka mysql jdbc driver address
######################################
# mysql 数据库地址(需要提前创建好 ke 库,咱不是有 mysql 的存储方式,所以这段内容注释掉)
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
#efak.username=root
#efak.password=1234565.4 启动 Kafka-eagle
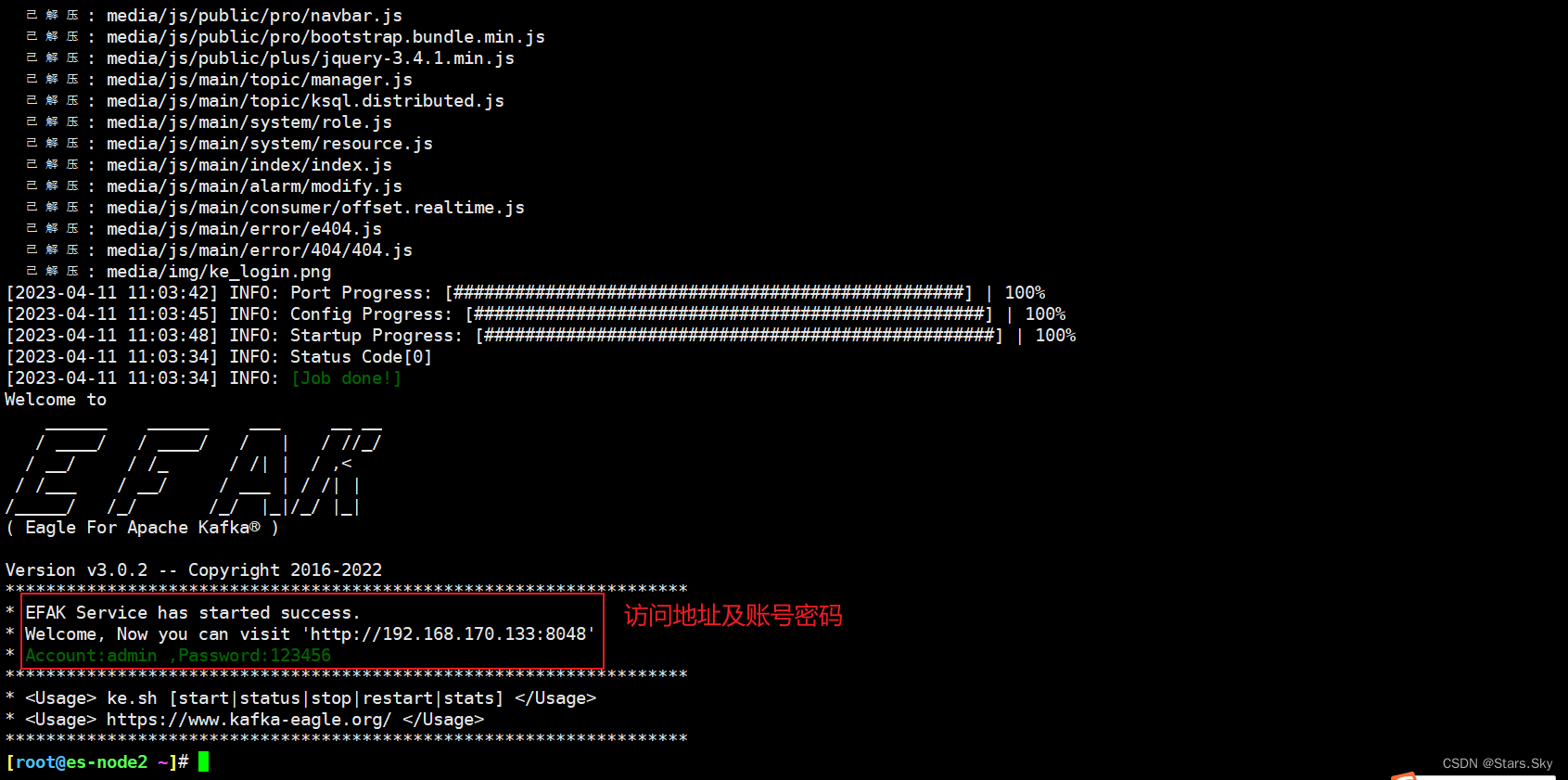
[root@es-node2 ~]# /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/bin/ke.sh start
5.5 开启 eagle 监控
通过 JMX 获取数据,监控 Kafka 客户端、生产端、消息数、请求数、处理时间等数据可视化的性能。
# 开启 Kafka 的 JMX(所有 Kafka 集群节点都需要)
[root@es-node1 /opt/kafka]# vim /opt/kafka/bin/kafka-server-start.sh
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999"
fi
# 重启 Kafka
[root@es-node1 /opt/kafka]# kf.sh stop
[root@es-node1 /opt/kafka]# kf.sh start
5.6 访问 Kafka-eagle
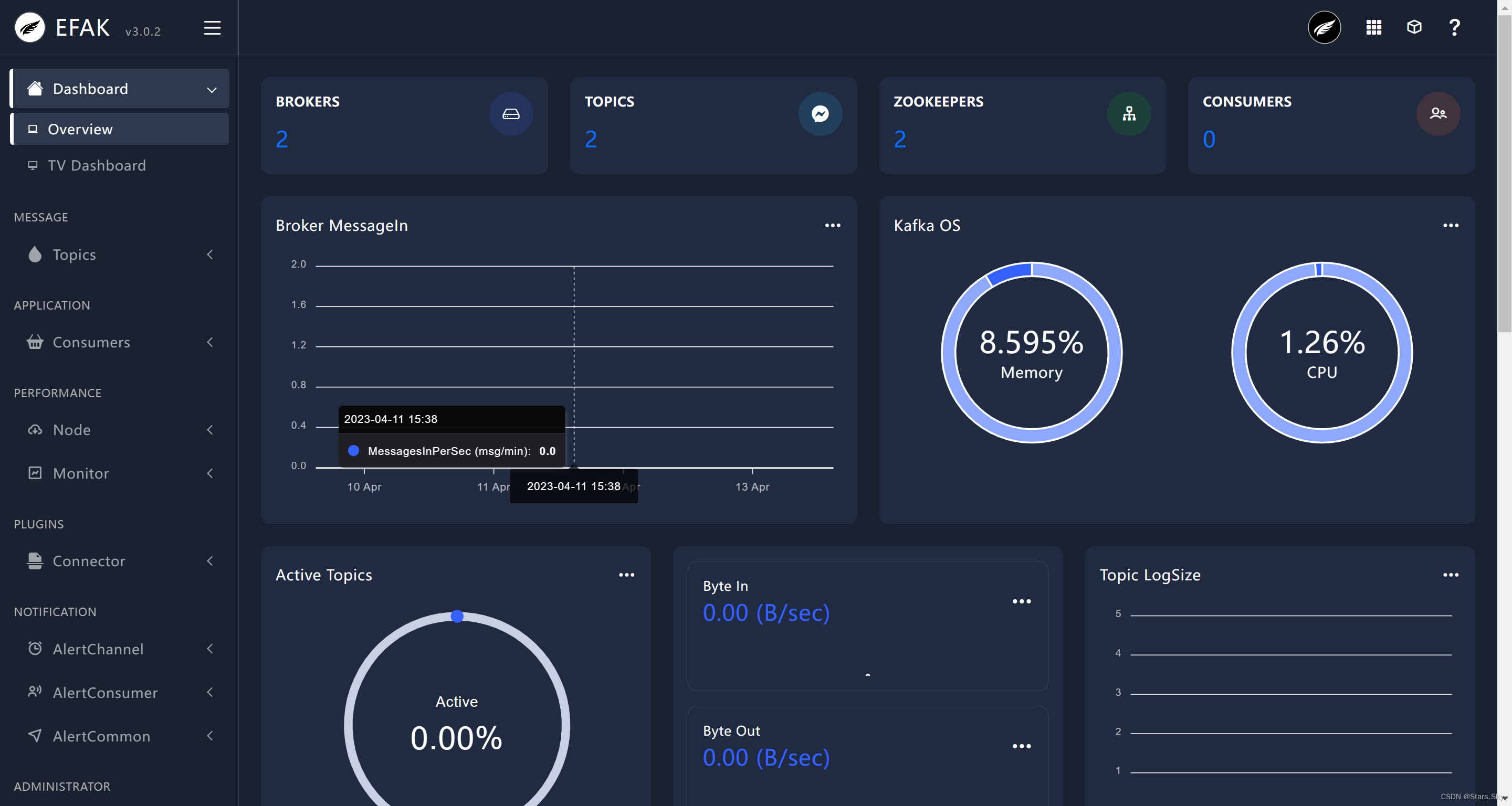
点击 右边列表的 TV Dashboard:
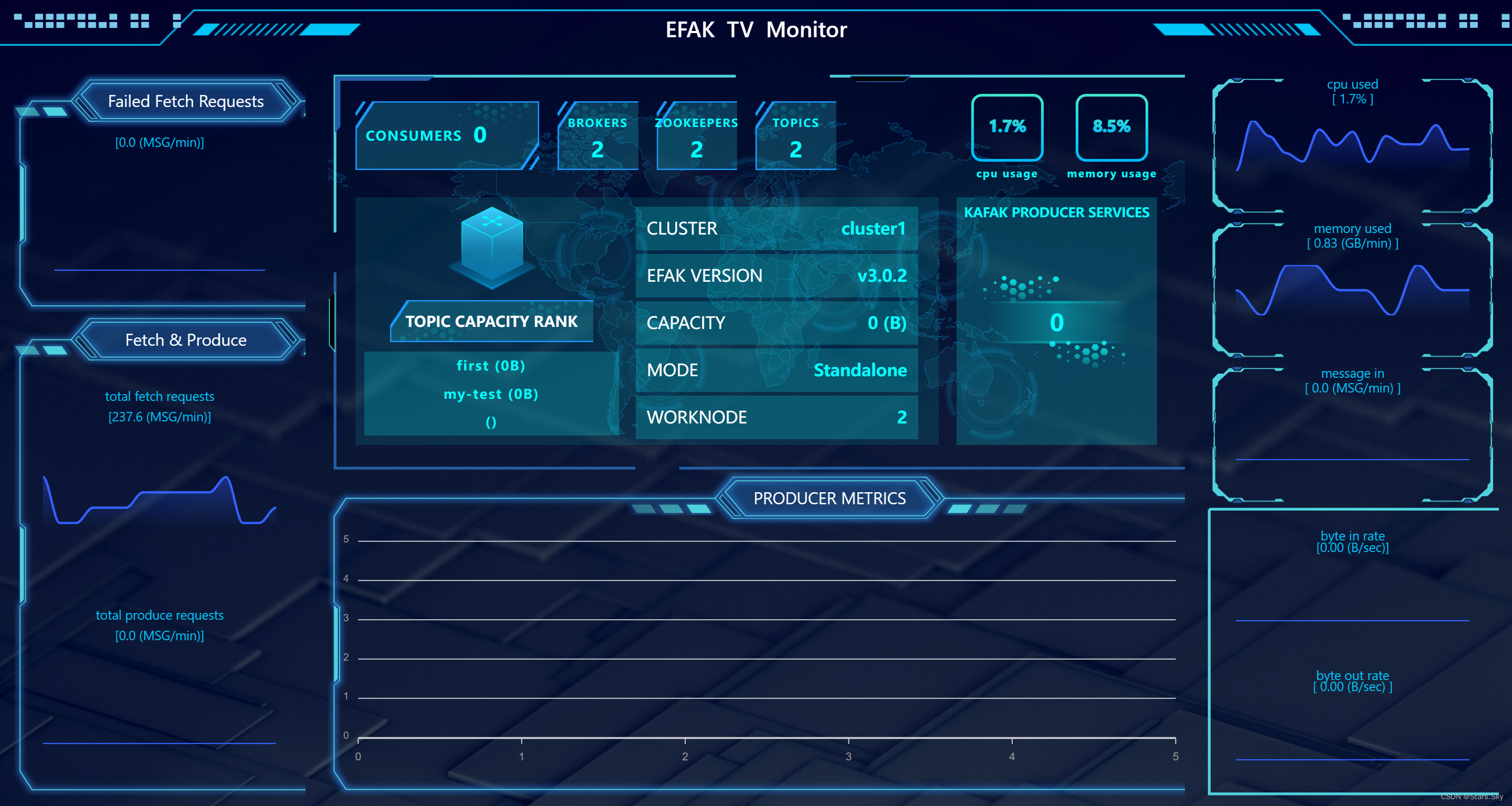
5.7 遇到的小坑
如果 eagle 仪表盘上监控不到任何信息,则查看 eagle 错误日志:
[root@es-node2 ~]# cd /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/logs/
[root@es-node2 /usr/local/kafka-eagle-bin-3.0.2/efak-web-3.0.2/logs]# tail -f error.log
[2023-04-11 15:17:00] KafkaServiceImpl.Thread-351 - ERROR - Get kafka consumer has error,msg is Failed create new KafkaAdminClient
[2023-04-11 15:17:00] MetricsSubTask.Thread-351 - ERROR - Collector consumer topic data has error, msg is
java.lang.NullPointerException
at org.smartloli.kafka.eagle.core.factory.KafkaServiceImpl.getKafkaConsumer(KafkaServiceImpl.java:749)
at org.smartloli.kafka.eagle.web.quartz.MetricsSubTask.bscreenConsumerTopicStats(MetricsSubTask.java:113)
at org.smartloli.kafka.eagle.web.quartz.MetricsSubTask.metricsConsumerTopicQuartz(MetricsSubTask.java:73)
at org.smartloli.kafka.eagle.web.quartz.MetricsSubTask.run(MetricsSubTask.java:68)

解决办法: 确保你自己 kafka 配置文件的 zookeeper.connect=192.168.170.132:2181,192.168.170.134:2181/kafka 与 eagle 配置文件中的 cluster1.zk.list=192.168.170.132:2181,192.168.170.134:2181/kafka 保持一致,再重新启动 eagle 即可。
六、ELK 对接 Kafka
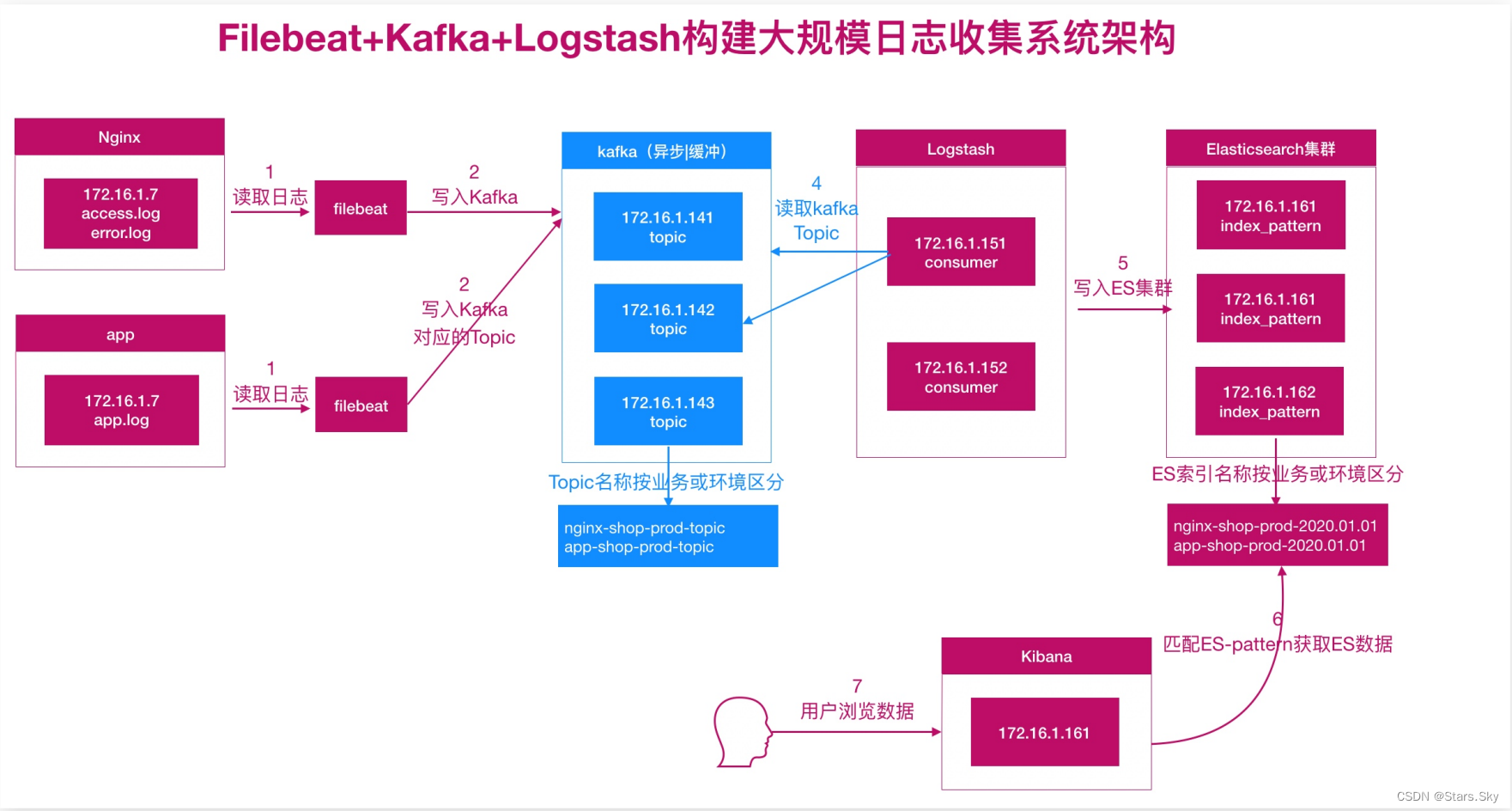
6.1 配置 Filebeat
[root@es-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/nginx/access.log # 日志所在路径
tags: ["access"]
- type: log # 收集日志的类型
enabled: true # 启用日志收集
paths:
- /var/log/nginx/error.log # 日志所在路径
tags: ["error"]
output.kafka:
hosts: ["192.168.170.132:9092", "192.168.170.134:9092"]
topic: nginx_kafka_prod
required_acks: 1 # 保证消息可靠,0不保证,1等待写入主分区(默认),-1等待写入副本分区
compression: gzip # 压缩
max_message_bytes: 10000 # 每条消息最大的长度,多余的被删除
[root@es-node3 ~]# systemctl restart filebeat.service
6.2 配置 Logstash
[root@es-node1 ~]# vim /etc/logstash/conf.d/test6.conf
input {
kafka {
bootstrap_servers => "192.168.170.132:9092,192.168.170.134:9092"
topics => ["nginx_kafka_prod"] # topic 名称
group_id => "logstash" # 消费者组名称
client_id => "node1" # 消费者组实例名称
consumer_threads => "2" # 理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡,线程多于分区意味着某些线程将处于空闲状态
#topics_pattern => "app_prod*" # 通过正则表达式匹配要订阅的主题
codec => "json"
}
}
filter {
if "access" in [tags][0] {
grok {
match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)" }
}
useragent {
source => "useragent"
target => "useragent"
}
geoip {
source => "clientip"
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => ["bytes","integer"]
convert => ["response_time", "float"]
convert => ["upstream_response_time", "float"]
remove_field => ["message", "agent", "tags"]
add_field => { "target_index" => "kafka-logstash-nginx-access-%{+YYYY.MM.dd}" }
}
# 提取 referrer 具体的域名 /^"http/
if [referrer] =~ /^"http/ {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }
}
}
# 提取用户请求资源类型以及资源 ID 编号
if "sky.com" in [referrer_host] {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:sky_type}/%{NOTSPACE:sky_res_id})?"' }
}
}
}
else if "error" in [tags][0] {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
add_field => { "target_index" => "kafka-logstash-nginx-error-%{+YYYY.MM.dd}" }
}
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["192.168.170.132:9200","192.168.170.133:9200","192.168.170.134:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
}
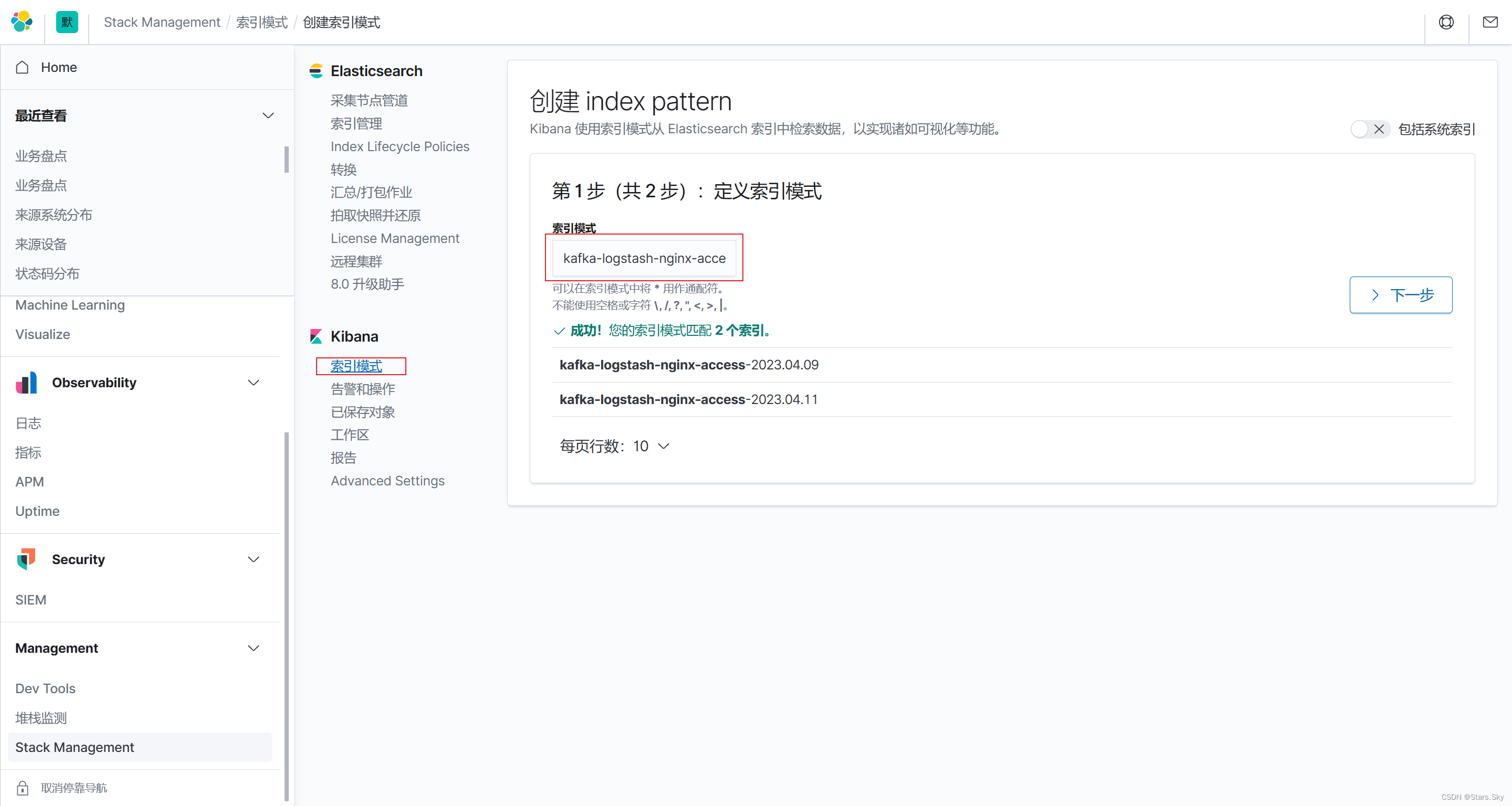
6.3 配置 kibana
创建 Kibana 索引:
上一篇文章:【Elastic (ELK) Stack 实战教程】09、Kibana 分析站点业务日志_Stars.Sky的博客-CSDN博客
下一篇文章:【Elastic (ELK) Stack 实战教程】11、使用 ElastAlert 实现 ES 钉钉群日志告警_Stars.Sky的博客-CSDN博客