Diffusion Model
今天简单了解了一下扩散模型,主要是学习了最经典的那篇2020年发表的denoising diffusion probabilistic models(DDPM)。需要掌握一些高数基础、概率论以及KL散度相关的知识,数学公式推导起来才不至于费劲,而且里面的概率公式多是基于贝叶斯公式以及马尔科夫假设,运用的比较灵活,虽然数学原理推导不是很难,但是整个模型的理解会存在一些或大或小的问题,我将在这篇文章中记录一下我的一些疑惑,并尝试着去解答,欢迎大佬指出错误。
下面列出我学习过程中参考的一些文章:
- 原论文DDPM
- What are Diffusion Models? 大佬的博客,写的非常简练,值得阅读
- 源自知乎的深入讲解,基于上篇博客的翻译与理解
- 涉及一些基于tensorflow源码的讲解
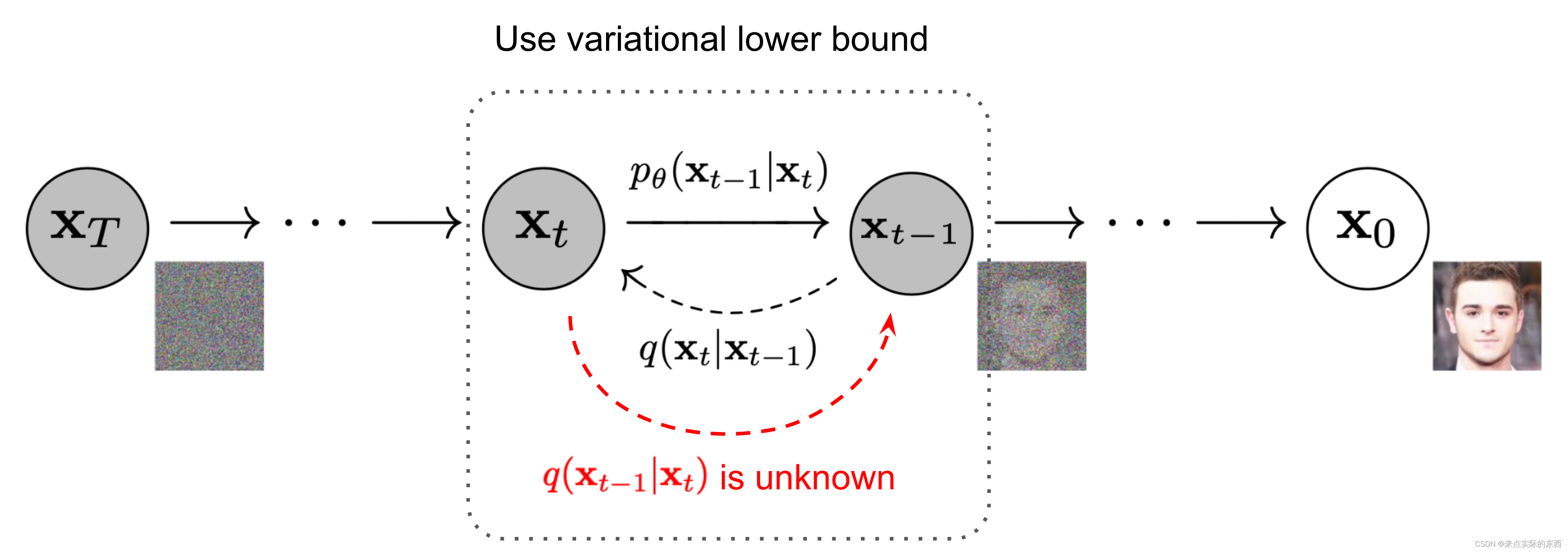
问题1 模型学习到的是什么,它需要预测什么?
①在扩散过程中,输入的原始图片x0,在一步步加入高斯噪声后,会得到一个标准的高斯分布噪声。而且基于重参数(reparameterization trick)以及相关数学公式的推导,能够得到结论:任意时刻的x_t可以由x0和β表示。
因此在实际训练的过程中,在从数据集中采样的得到原始图片x0后,并不需要一步一步地添加高斯噪声,利用重参数的技巧,获取对应时间步的x_t (在原始图片的基础上添加了一系列的高斯噪声)。而是利用已经推导出的结论,快速利用公式从x0,α和β参数中得到任意时刻的x_t。
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t\mathbf{I}) \quad q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)x t = α t x t − 1 + 1 − α t ϵ t − 1 ;where ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ t − 2 ;where ϵ ˉ t − 2 merges two Gaussians (*). = … = α ˉ t x 0 + 1 − α ˉ t ϵ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{aligned} \mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} & \text{ ;where } \boldsymbol{\epsilon}_{t-1}, \boldsymbol{\epsilon}_{t-2}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\boldsymbol{\epsilon}}_{t-2} & \text{ ;where } \bar{\boldsymbol{\epsilon}}_{t-2} \text{ merges two Gaussians (*).} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon} \\ q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) \end{aligned} xtq(xt∣x0)=αtxt−1+1−αtϵt−1=αtαt−1xt−2+1−αtαt−1ϵˉt−2=…=αˉtx0+1−αˉtϵ=N(xt;αˉtx0,(1−αˉt)I) ;where ϵt−1,ϵt−2,⋯∼N(0,I) ;where ϵˉt−2 merges two Gaussians (*).
②在Diffusion的逆扩散,逆向过程中,实际上就是一个逐渐去噪的过程。如果我们能够逐步得到逆转后的分布,即给定x_t推出x_t-1。(并且在论文中给出相关文献证明这样一个逆向分布其实也是高斯分布,只需要满足β参数足够小即可)
q ( x t − 1 ∣ x t ) ( 逆 向 分 布 , 公 式 ① ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t) (逆向分布,公式①) q(xt−1∣xt)(逆向分布,公式①)
,就可以从完全的标准高斯分布
x T ∼ N ( 0 , I ) \mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xT∼N(0,I)
还原出原图分布 x0 。但是这个逆向的概率分布求解起来比较麻烦,每步都需要遍历整个数据集,因此作者使用深度学习模型去预测这样一个逆向的分布p_θ。
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) ( 模 型 求 解 的 逆 向 分 布 , 公 式 ② ) p_\theta(\mathbf{x}_{0:T}) = p(\mathbf{x}_T) \prod^T_{t=1} p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) \quad p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) (模型求解的逆向分布,公式②) pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))(模型求解的逆向分布,公式②)
作者发现,虽然我们不能直接求逆向分布,但是引入x_0之后,我们可以直接求出一个给定x_0的逆向分布的解析式,也即后验条件概率。并且直接求出了对应高斯分布的均值与方差,相关的推导过程可以参考贴出的博客。
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t I ) ( 给 定 x 0 的 逆 向 分 布 , 公 式 ③ ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I}) \color{black}(给定x_0的逆向分布,公式③) q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)(给定x0的逆向分布,公式③)
β ~ t = 1 / ( α t β t + 1 1 − α ˉ t − 1 ) = 1 / ( α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t ( 方 差 , 公 式 ④ ) μ ~ t ( x t , x 0 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \begin{aligned} \tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = 1/(\frac{\alpha_t - \bar{\alpha}_t + \beta_t}{\beta_t(1 - \bar{\alpha}_{t-1})}) = \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \color{black}(方差,公式④) \\ \tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t, \mathbf{x}_0) &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) \\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0) \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \mathbf{x}_0\\ \end{aligned} β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt(方差,公式④)=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
结合前面扩散过程中,由x_0快速求出x_t的公式,我们可以将上面的均值μ改写化简成下列公式。
x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) \mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) x0=αˉt1(xt−1−αˉtϵt)
μ ~ t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) ( 均 值 , 公 式 ⑤ ) \begin{aligned} \tilde{\boldsymbol{\mu}}_t &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) \\ &= \color{red}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)} \end{aligned} \color{black}(均值,公式⑤) μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtϵt)=αt1(xt−1−αˉt1−αtϵt)(均值,公式⑤)
重点来了:

经过上面的分析,我们的扩散模型主要的工作就是需要近似模拟一个真实的逆向分布(公式①),模型的预测得出的分布(公式②),给定x_0的逆向分布(公式③),这三个分布都是高斯分布,含有均值和方差。原论文中作者真正做的是,想办法让模型预测的分布来逼近 给定x_0的逆向分布(公式③),主要是通过MSE来拉近两个分布的均值,而方差并没有选择通过模型来预测,而是直接选择了 给定x_0的逆向分布的方差,即公式④,并且作者也给出了解释,方差通过网络预测,可能导致训练不稳定。
想要尽可能的近似真实分布,可以通过对真实数据分布下,最大化模型预测分布的对数似然。类似VAE的思想,使用变分下限(VLB)来优化负对数似然(涉及到KL散度的知识),经过一系列的公式推导,发现得到了一系列组合的KL散度,而最小化负对数似然就是在最小化这些组合的KL散度,拉近两个高斯分布,即模型预测的分布和给定 x_0的逆向分布。
进一步对多元高斯分布的KL散度求解,可以得到训练过程中损失函数的真实面貌,就是在让模型学习到指定分布的均值(给定x_0的逆向分布,可以通过公式推导求出解析式),更进一步,因为均值表达式中x_t和α这些参数在逆扩散过程中都是已知的、作为输入,因此唯一不同的就是高斯噪声ε。
L t simple = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{aligned} L_t^\text{simple} &= \mathbb{E}_{t \sim [1, T], \mathbf{x}_0, \boldsymbol{\epsilon}_t} \Big[\|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\|^2 \Big] \\ &= \mathbb{E}_{t \sim [1, T], \mathbf{x}_0, \boldsymbol{\epsilon}_t} \Big[\|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t, t)\|^2 \Big] \end{aligned} Ltsimple=Et∼[1,T],x0,ϵt[∥ϵt−ϵθ(xt,t)∥2]=Et∼[1,T],x0,ϵt[∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2]
L t = E x 0 , ϵ [ 1 2 ∥ Σ θ ( x t , t ) ∥ 2 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 1 2 ∥ Σ θ ∥ 2 2 ∥ 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) − 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{aligned} L_t &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{1}{2 \| \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) \|^2_2} \| \color{blue}{\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t, \mathbf{x}_0)} - \color{green}{\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{1}{2 \|\boldsymbol{\Sigma}_\theta \|^2_2} \| \color{blue}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)} - \color{green}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\boldsymbol{\epsilon}}_\theta(\mathbf{x}_t, t) \Big)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t, t)\|^2 \Big] \end{aligned} Lt=Ex0,ϵ[2∥Σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=Ex0,ϵ[2∥Σθ∥221∥αt1(xt−1−αˉt1−αtϵt)−αt1(xt−1−αˉt1−αtϵθ(xt,t))∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥ϵt−ϵθ(xt,t)∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2]
重点!!!
因此高斯噪声ε_θ就是最终模型需要学习预测的,并且训练的核心就是取高斯噪声ε和ε_θ之间的MSE。逆扩散过程中,模型预测出高斯噪声ε_θ后,带入公式⑥中得到均值,然后利用指定的方差(公式④),使用重参数的技巧,从x_t中推出x_t-1,一步步的迭代至求出原始图片x_0
μ θ ( x t , t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) ( 模 型 预 测 分 布 的 均 值 , 公 式 ⑥ ) Thus x t − 1 = N ( x t − 1 ; 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) , Σ θ ( x t , t ) ) \begin{aligned} \boldsymbol{\mu}_\theta(\mathbf{x}_t, t) &= \color{red}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \Big)} (模型预测分布的均值,公式⑥) \\ \text{Thus }\mathbf{x}_{t-1} &= \mathcal{N}(\mathbf{x}_{t-1}; \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \Big), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) \end{aligned} μθ(xt,t)Thus xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))(模型预测分布的均值,公式⑥)=N(xt−1;αt1(xt−1−αˉt1−αtϵθ(xt,t)),Σθ(xt,t))

总结:模型预测输出的就是一个高斯噪声ε_θ,输入是x_t(通过x_0和α相关参数带入公式快速求出的,可以理解为原始图片经过t步加噪后得到的一个含有高斯噪声的图片) 和t(一般都是通过embedding层后输入模型)。从直觉上来讲,模型对于一个带噪的图片(可能是一个标准的高斯分布,即X_T),预测出添加的噪声是什么,然后通过带入公式、重参数采样,逆向扩散过程一步步反向求出x_0。
问题2 为什么训练的过程中,对于从训练集中采样得到的一个输入x_0,只是随机产生一个t ,扩散添加噪声得到x_t,而不是从1到T?
一开始看论文以及一些博客的时候这个问题就让我有些迷惑,因为按作者的说法是可以添加噪声得到的x_1,x_2…x_T的啊,为什么不这样做,产生这些,而不只是x_t?仔细思考,其实可以简单理解为**一个输入多样性的问题?**但是在足够数量的epoch的训练迭代下这个问题似乎就可以理解了,在一轮epoch中,对于固定输入图片1,在改轮中随机产生t1,那么在下一轮中随机产生t2,只要足够epoch,产生1…T不是问题。在另一个方面,似乎也可以从计算效率上考虑,训练集中的所有样本,都生成1…T的带噪x_t,T也是一个比较大的数,那么计算量过大,而且这样训练也让模型被迫更加聪明一些。
问题3 在推理,逆扩散的过程中,为什么不根据扩散过程中得到的x_0推x_t的公式,直接模型预测输出高斯噪声后,直接从x_t推出x_0,而是一步步地来?
这个问题也困扰了我,相信有一部分人也存在类似的疑惑。下面给出相关公式,其实上文已经列出,这里重新给出。
x t = α t x t − 1 + 1 − α t ϵ t − 1 ;where ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ t − 2 ;where ϵ ˉ t − 2 merges two Gaussians (*). = … = α ˉ t x 0 + 1 − α ˉ t ϵ ( 公 式 ⑦ ) q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{aligned} \mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} & \text{ ;where } \boldsymbol{\epsilon}_{t-1}, \boldsymbol{\epsilon}_{t-2}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\boldsymbol{\epsilon}}_{t-2} & \text{ ;where } \bar{\boldsymbol{\epsilon}}_{t-2} \text{ merges two Gaussians (*).} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon} (公式⑦) \\ q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) \end{aligned} xtq(xt∣x0)=αtxt−1+1−αtϵt−1=αtαt−1xt−2+1−αtαt−1ϵˉt−2=…=αˉtx0+1−αˉtϵ(公式⑦)=N(xt;αˉtx0,(1−αˉt)I) ;where ϵt−1,ϵt−2,⋯∼N(0,I) ;where ϵˉt−2 merges two Gaussians (*).
x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) ( 公 式 ⑧ ) \mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) (公式⑧) x0=αˉt1(xt−1−αˉtϵt)(公式⑧)
个人觉得主要的原因在于生成的效果。这种直接预测x_0的做法,直观上理解,就是原始图片添加噪声后的x_t作为输入,模型直接预测添加的随机噪声,然后直接带入公式(公式⑧)求得x_0,不经过逆扩散一步步采样、重参数的过程。那么对于训练集中的固定的采样的样本x_0,相当于模型尝试去记住了训练过程中添加的噪声,这样一步到位效果不是很好,尤其对于大数据集而言,模型需要足够的复杂度来记忆大量随机噪声,最终训练的效果可能不够好?而让模型预测均值,方差这些参数,从直觉上来讲是记住了逆扩散过程中的高斯分布,然后一步步迭代,从x_T…x_t…x_0,更加平滑一些,能够得到高质量的样本。
总结:
算是扩散模型的入门,很多东西喜欢钻牛角尖,想办法弄清楚细枝末节,导致理解起来磕磕绊绊,但总归结果是好的,对Diffusion Model的原理有了一个大致的掌握。
注: 本文中的一系列公式以及插图主要参考 大佬的博客,其实上面已经贴出来了,还是强烈建议自习阅读一番。