下载全球疫情数据,按照日期下载,数据开始时间为2020年1月20日,结束于当前日前两天。
第一步:解析目标网站
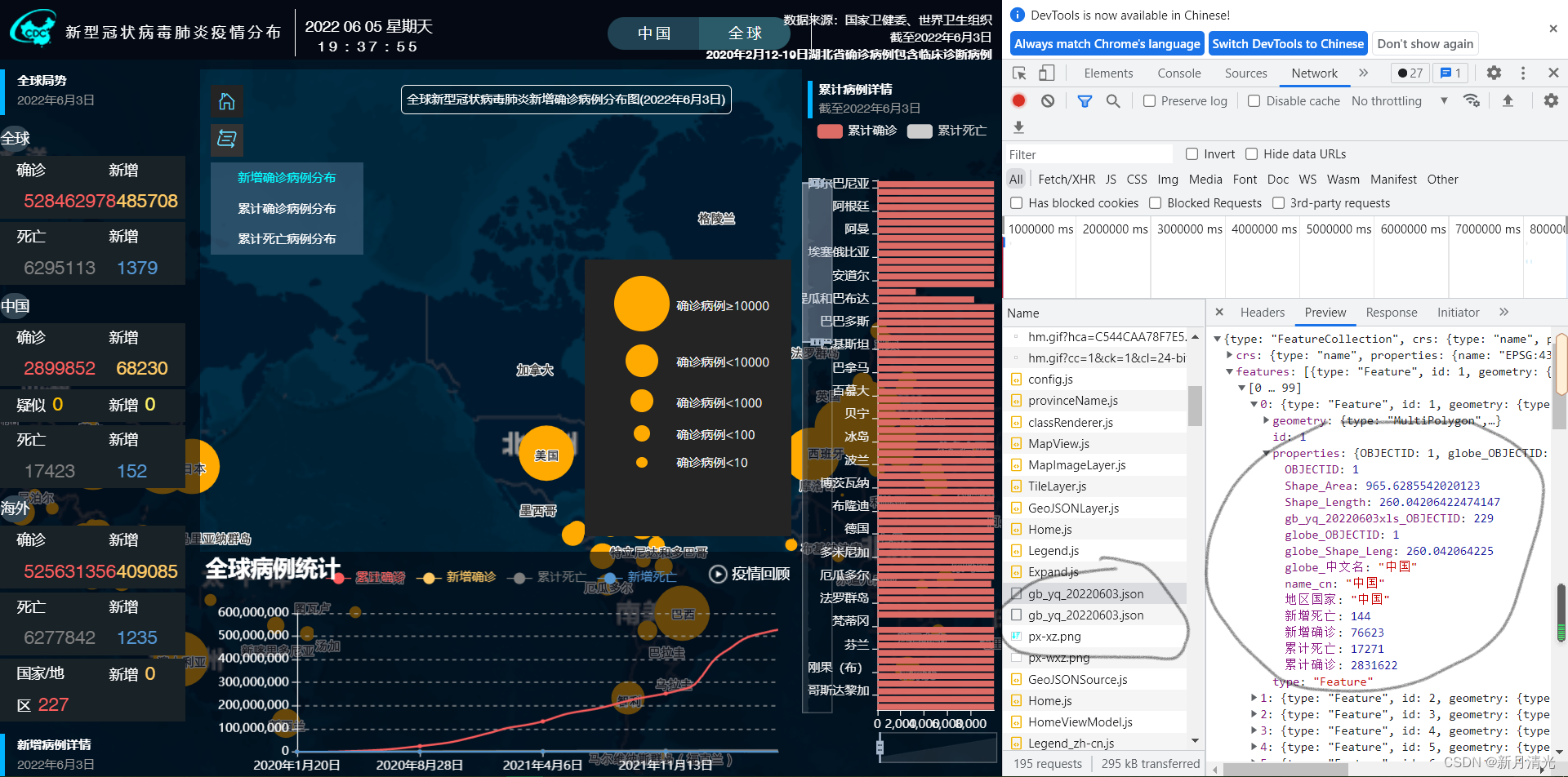
第二步:获取数据接口

第三步:编写代码,基于数据接口,循环转换数据格式
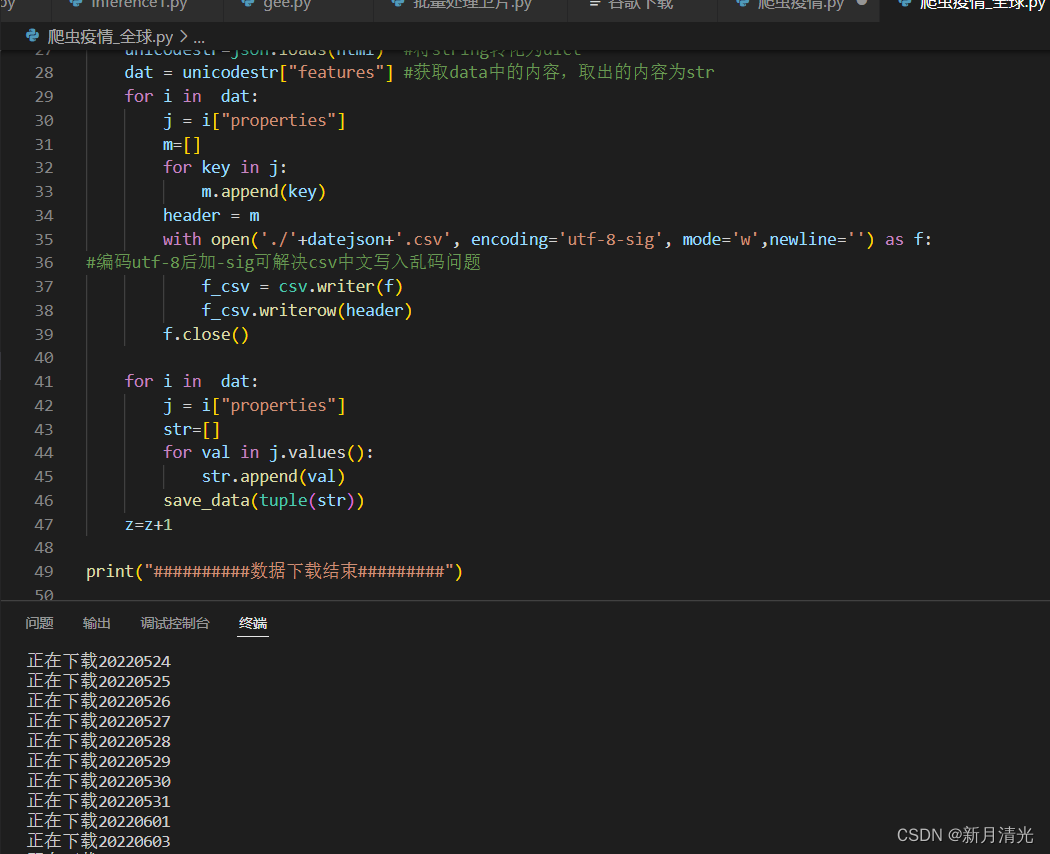
代码如下:
import requests
import json
import time
import csv
from urllib.request import urlopen, quote
def save_data(data):
with open('./'+datejson+'.csv', encoding='UTF-8', mode='a+',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
print("#########"
" 版权所有:殷宗敏 & 数据接口来源-https://2019ncov.chinacdc.cn/2019-nCoV/ & 在此表示感谢!"
"##########")
firstDate = 1579190400
intervalDate = 86400
z=3
now = time.time()
while firstDate+intervalDate*z<now-intervalDate:
now_time = time.strftime("%Y%m%d %H:%M:%S", time.localtime(firstDate+intervalDate*z))
datejson=now_time.split( )[0]
print("正在下载"+datejson)
url = 'https://2019ncov.chinacdc.cn/JKZX/gb_yq_'+datejson+'.json'
html = requests.get(url).text
unicodestr=json.loads(html) #将string转化为dict
dat = unicodestr["features"] #获取data中的内容,取出的内容为str
for i in dat:
j = i["properties"]
m=[]
for key in j:
m.append(key)
header = m
with open('./'+datejson+'.csv', encoding='utf-8-sig', mode='w',newline='') as f:
#编码utf-8后加-sig可解决csv中文写入乱码问题
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
for i in dat:
j = i["properties"]
str=[]
for val in j.values():
str.append(val)
save_data(tuple(str))
z=z+1
print("##########数据下载结束#########")
结果文件为每日的csv格式文件,内部结构如下:
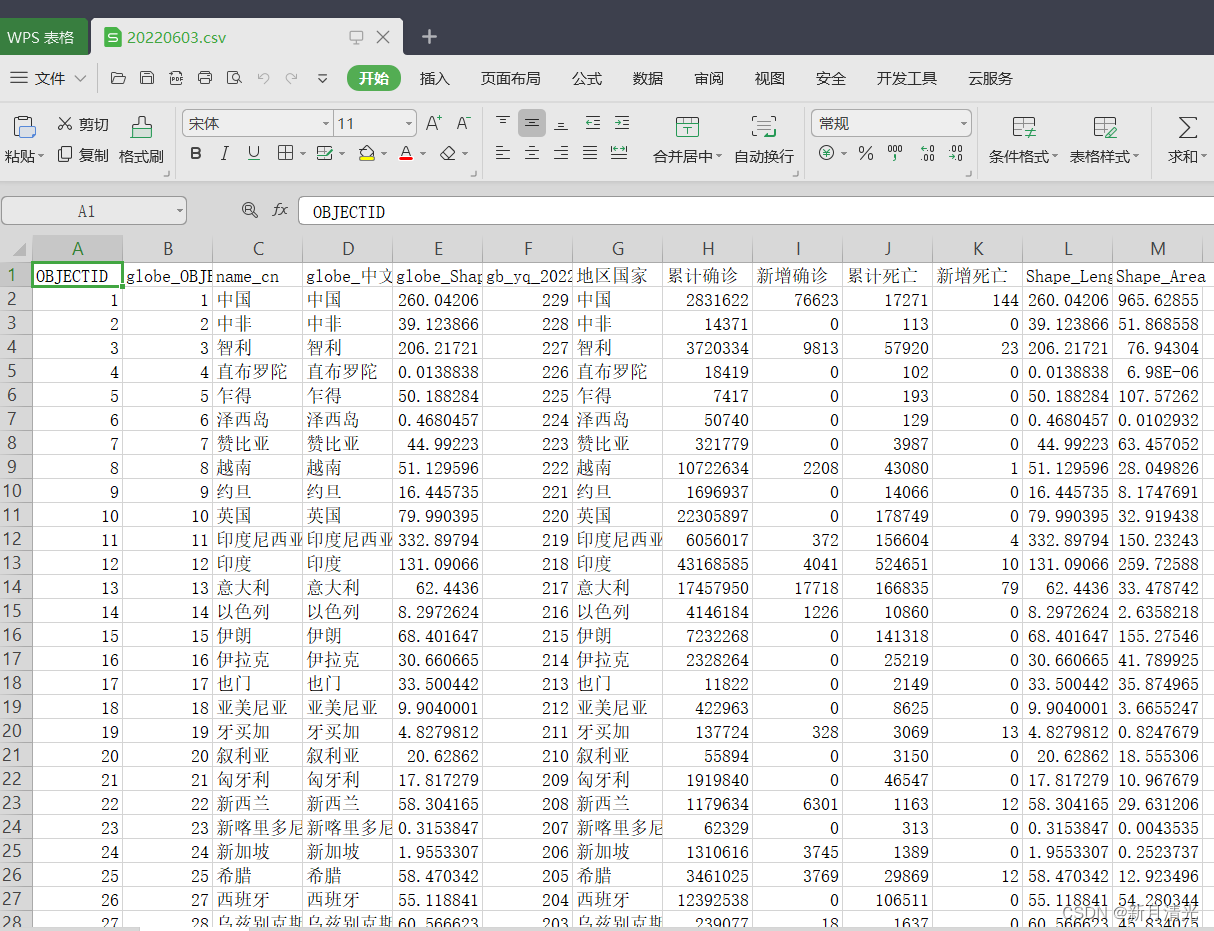
下载好的数据:
链接:https://pan.baidu.com/s/1c2ohd-7V8zHTYVHuYcT54A
提取码:13ai