1.强化学习基本概念
行为主义是人工智能三大流派之一,而强化学习就是行为主义最突出的方法。行为主义把“刺激-反应”作为基本公式,如人或者动物受了某种刺激,就会有某种反应;反过来,人或动物有某种反应就可能是受到了某种刺激。行为主义心理学有个著名的实验“桑代克的猫”,讲的是一只饿猫被关在桑代克专门设计的实验箱子里面,饿猫同时能看见箱子外放着的一条鱼。箱子里面有一个开箱门的旋钮,碰到这个旋钮,箱门便会打开,饿猫就可以走出箱子吃到鱼。开始饿猫无法走出箱子,只是在里面乱碰乱撞,偶然一次碰到旋钮打开了箱子,便逃出吃到了鱼。经多次这个实验,猫就学会了碰到旋钮去开箱门的行为。
强化学习就是沿着这中思想发展起来的,机器人(智能体)做了某个动作,就会得到奖励;而做了另外某个动作,就会得到惩罚。机器人(智能体)就这样不断的进行尝试学会了知识。所谓强化就是通过强化物(奖励或惩罚)增强某种行为的过程。
下面就是强化学习的正式描述,如下图,强化学习把学习看作试探过程,智能体(Agent)选择一个动作a,环境接受该动作后状态发生变化,同时产生一个强化信号(奖励或惩罚)反馈给智能体,智能体再根据环境新的当前状态s选择下一个动作,选择的原则是使受到奖励的概率增大。
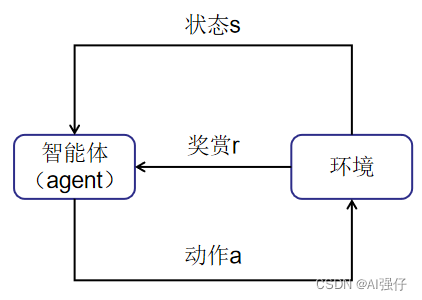
比如我们让智能体玩贪吃蛇这个游戏,环境就是指游戏内蛇所处在的环境,当蛇吞下豆子身体长大(得到了奖励),此时环境(游戏界面)也会继续跟着变化;当蛇碰到障碍物就会收到惩罚。
强化学习一个非常著名的例子是谷歌旗下DeepMind公司的AlphaGo,它是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能机器人。本书主要的主题ChatGPT也是采用了强化学习的方法,会在下面几节进行更为详细的描述,说明强化学习的思想如何转换为可以运行的程序,让机器人可以学习。
2.强化学习都有哪些
在20世纪50-60年代,科学家就开始研究强化学习了,到今天已经发展出来许许多多的强化学习方法,它们的种类也是多种多样。本书主要描述这种分类方法,其将强化学习分为三类,分别为基于价值(Value-Based )的强化学习、基于策略(Policy-Based)的强化学习、演员-评论家(Actor-Critic)强化学习。
基于策略的方法直接学习环境(state)与动作(action)之间的关系,而基于价值的方法通过价值函数间接学习环境(state)与动作(action)的关系,所谓价值函数是衡量智能体在某个环境(state)、某个动作(action)情况下会得到多少奖励。ChatGPT的强化学习方法是从基于策略的强化学习发展而来的。下面将对这三种方法分别进行介绍。
3.基于策略的强化学习
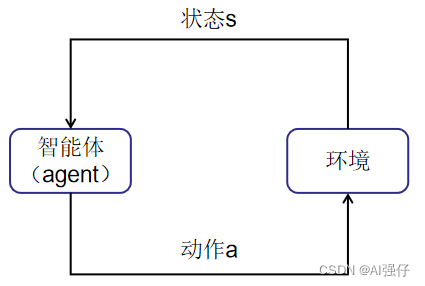
基于策略(Policy-Based )强化学习方法,其中策略是指智能体在什么环境(state)下采取什么动作(action),其实就是下图,只是将奖励隐藏其后作为智能体训练的目标。
所以基于策略的方法有如下一个简单公式,用表示策略,策略等于智能体根据学习到的知识信息以及当前环境(state,简写s)做出动作a的概率。学习策略主要就是学习参数中保存着智能体学习到的知识信息。
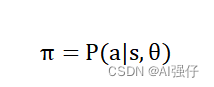
就像桑代克的猫,在箱子那个环境s下学会了触碰旋钮的动作a,隐藏背后的奖励就是可以吃到鱼。猫具体学到的知识保存其大脑中。
而实际中我们往往用一个神经网络替代,保存学到的知识信息,就像桑代克的猫的脑中的神经元。关于神经网络的学习,通过前面几章的了解,相信大家已不陌生。只要我们知道了目标函数(用奖励表示),就很容易用梯度的方法进行求解。最终的形式就如下图,通过神经网络学习环境(state)与动作(action)的关系,学习之后就可以知道在什么环境(state)下采取什么动作(action)。
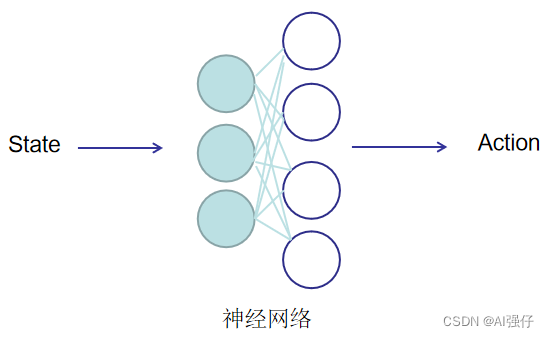
4.基于价值的强化学习
基于价值(Value-Based )的强化学习方法,提出的时间比基于策略的方法要早,1992年watkins就提出了Q-learning方法,它是最经典的一个基于价值的强化学习算法。基于价值的方法比基于策略的方法多了一个价值函数Q,该函数表示智能体在状态s和动作a下会得到什么奖励。
Q(s,a)=E[奖励|s,a]
以Q-learning为例,其价值函数Q可以用一个表格表示,行表示动作,列表示状态,每个格子中的值就表示智能体在状态s和动作a下会得到什么奖励。我们增加下“桑代克的猫”的实验难度,猫除了乱碰、触碰旋钮这两个动作外,增加一个按红色按钮的动作。同时增加环境状态为两个,即白天和晚上。如下表所示:
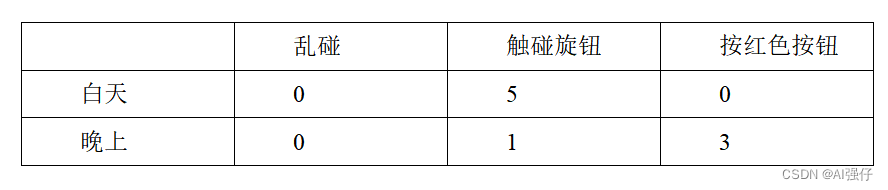
猫在白天只要触碰旋钮就能吃到鱼,奖励得分为5;猫在晚上触碰旋钮吃不到鱼,但逃出去了,奖励得分为1。猫晚上按红色按钮可以吃到猫粮,奖励得分为3;猫白天按红色按钮却吃不到猫粮,没有奖励,得分为0。猫乱碰,无论白天和晚上都是没有奖励,得分为0。
我们经过多次的实验,猫就学会了这个表格,即学习了这个价值函数。猫就可以根据这个表格(价值函数)在不同环境状态下选择不同的动作,以期最大化自己的收益。比如白天,猫就会倾向于触碰旋钮;在晚上,猫就会倾向于按红色按钮。
在实际的强化学习中,价值函数的表格往往会在智能体采取某种动作后有所变化,所以智能体不是学习一个静态的表格,而是学习一个复杂的动态变化的表格。
5.演员-评论家的强化学习
演员-评论家的强化学习是结合了基于价值的方法和基于策略的方法。要求智能体不仅要学习策略(演员),同时也要学习价值函数(评论家)。复杂的演员-评论家强化学习方法会采用两个神经网络,其中一个学习策略,负责生成动作(Action)并和环境交互,另一个学习价值函数,负责评估演员的表现,并指导演员下一阶段的动作,两个神经网络之间不断互动,最终提高智能体的水平。
比如演员(Actor)是舞台上的舞者,评论家(Critic)是台下的评委。舞者在台上跳舞,舞姿不好看时,评委会给出低分,舞姿好看时,评委会给出高分。演员通过评委给出的分数,不断的去学习,最终就会学会多表演得高分的动作,而少表演得低分的动作。而评委在期间也在不断的学习,学会更准确的评分。