强化学习 [入门]
概念
Action:动作
State:状态
Reward:奖励
π ( a ∣ s ) \pi(a|s) π(a∣s):策略函数,这是一个概率密度函数,指的是当前状态下,各个动作的概率。
S‘~P(*|a, s):状态转移函数,这也是一个概率密度函数,根据当前的状态和当前的动作,返回的是下一个状态的各个概率(因为小怪是随机的)。
观察s1--->根据策略函数获得a1--->生成下一个状态s2--->返回一个奖励r1
再将新的状态s2作为输入,根据策略函数获得a2……
轨迹:
s1,a1,r1,s2,a2,r2,…,sT,aT,rT
Return:回报。未来的累计奖励
U t = R t + R t + 1 + R t + 2 + … U_t=R_t+R_{t+1}+R_{t+2}+… Ut=Rt+Rt+1+Rt+2+…
R t R_t Rt和 R t + 1 R_{t+1} Rt+1并不同等重要,显然 R t R_t Rt更重要些。
折扣回报:
U t = R t + γ R t + 1 + γ 2 R t + 2 + γ 3 R t + 3 + ⋯ U_{t}=R_{t}+\gamma R_{t+1}+\gamma^{2} R_{t+2}+\gamma^{3} R_{t+3}+\cdots Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯
折扣率是一个超参数,需要自己调整。
动作价值函数(action-value function):
有了折扣回报,我们就可以知道这局游戏是快要赢了还是快要输了,未来的奖励越大越好。
但是折扣汇报是一个随机变量,它依赖于at,st,at+1等等,怎么评估折扣回报呢?用期望!使用积分将未来的状态和动作都消除了。还与policy函数有关,因为可以有不同的policy函数。
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] . Q_{\pi}(s_{t},a_{t})={\mathbb{E}}[U_{t}|S_{t}=s_{t},A_{t}=a_{t}]. Qπ(st,at)=E[Ut∣St=st,At=at].
最优动作价值函数:
怎么将Policy函数去掉?使用最大化!
Q ⋆ ( s t , a t ) = max π Q π ( s t , a t ) . Q^{\star}(s_{t},a_{t})=\operatorname*{max}_{\pi}Q_{\pi}(s_{t},a_{t}). Q⋆(st,at)=πmaxQπ(st,at).
该函数可以对当前动作a做评价,可以告诉我们当前动作好不好。
状态价值函数(state-value function):
离散情况:
V π ( s t ) = E A [ Q π ( s t , A ) ] = ∑ a π ( a ∣ s t ) ⋅ Q π ( s t , a ) V_{\pi}(s_{t})=\mathbb{E}_{A}\left[Q_{\pi}(s_{t},A)\right]=\sum_{a}\pi(a|s_{t})\cdot Q_{\pi}(s_{t},a) Vπ(st)=EA[Qπ(st,A)]=a∑π(a∣st)⋅Qπ(st,a)
连续情况:
V π ( s t ) = E A [ Q π ( s t , A ) ] = ∫ π ( a ∣ s t ) ⋅ Q π ( s t , a ) d a V_{\pi}(s_{t})=\mathbb{E}_{A}\left[Q_{\pi}(s_{t},A)\right]=\int\pi(a|s_{t})\cdot Q_{\pi}(s_{t},a)\:d a Vπ(st)=EA[Qπ(st,A)]=∫π(a∣st)⋅Qπ(st,a)da
将动作A作为随机变量,求期望把A消掉。
状态价值函数可以评价当前局势,判断我们快赢了还是快输了。
状态价值函数还能评价policy函数 π \pi π的好坏。
怎样控制Agent?
- 基于Policy函数 π ( a ∣ s ) \pi(a|s) π(a∣s)
- 观察状态 s t s_{t} st
- 获取随机变量 a t a_{t} at~ π ( ∗ ∣ s t ) \pi(*|s_t) π(∗∣st)
- 基于 Q ⋆ ( s , a ) Q^{\star}(s,a) Q⋆(s,a)函数
- 基于观察到的状态s
- 将每个a都输入进去,获得使得Q最大值的a: a t = argmax a Q ⋆ ( s t , a ) a_{t}=\operatorname{argmax}_{a}Q^{\star}(s_{t},a) at=argmaxaQ⋆(st,a)
**强化学习库:**OpenAI Gym

强化学习主要是为了学习Policy函数 π ( a ∣ s ) \pi(a|s) π(a∣s)或者 Q ⋆ ( s , a ) Q^{\star}(s,a) Q⋆(s,a),有了两个函数的一个,就能够控制Agent了。
价值学习
Deep Q Network(DQN)
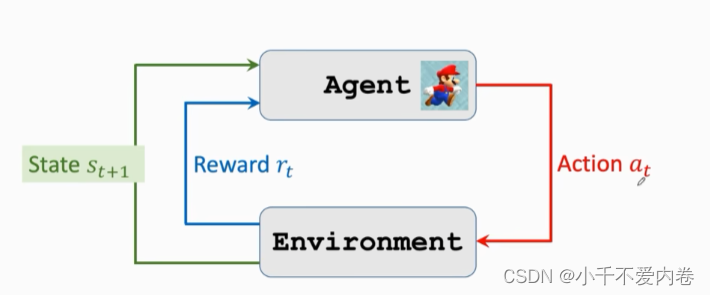
使用神经网络近似 Q ⋆ ( s , a ) Q^{\star}(s,a) Q⋆(s,a)函数
目标:游戏结束的时候获得的奖励总和越大越好。
Q ⋆ ( s , a ) Q^{\star}(s,a) Q⋆(s,a)可以评估每个动作,对于未来价值的期望,价值期望越大的动作越好。
使用神经网络 Q ( s , a ; w ) Q(s,a;w) Q(s,a;w)近似 Q ⋆ ( s , a ) Q^{\star}(s,a) Q⋆(s,a)函数,神经网络的参数是w。
怎么训练DQN?
Temporal Difference(TD) Learning
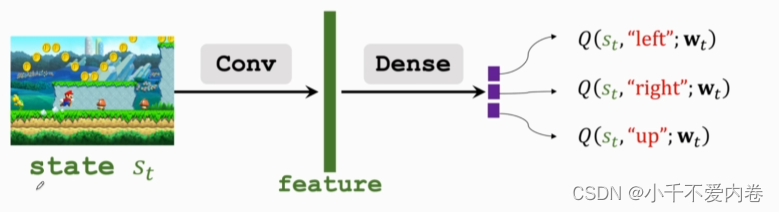
假如说我想让模型预测A点到B点所花的时间,模型会给一个预测值,假如说我的真实值只有从A到C的(C为A,B之间的某一个点),该怎么训练?TD算法!模型可以预测C到B的使用时间,再加上从A到C的真实的使用时间,用这个时间(TD target)进行梯度下降。
因此,不需要打完游戏,使用TD算法也能够更新参数。
TD算法必须要有上图中类似于上方这样的一个公式,左边是模型预测值,右边是一部分真实值和一部分预测值的加和。
在深度强化学习中,恰好也有这么一个公式:
Q ( s t , a t ; w ) ≈ r t + γ ⋅ Q ( s t + 1 , a t + 1 ; w ) Q(s_t,a_t;\mathbb{w})\approx r_t+\gamma\cdot Q(s_{t+1},a_{t+1};\mathbb{w}) Q(st,at;w)≈rt+γ⋅Q(st+1,at+1;w)
公式看 U t = R t + r ⋅ U t + 1 U_t = R_t+r\cdot U_{t+1} Ut=Rt+r⋅Ut+1
而Q是对U的估计,因此有上面的公式。
- Prediction:t时刻,模型做出了预测 Q ( s t , a t ; w t ) Q(s_{t},a_{t};\mathbf{w}_{t}) Q(st,at;wt).
- TD target:t+1时刻,观测到了真实的回报 R t R_t Rt,和t+1时刻的状态 S t + 1 S_{t+1} St+1,之后就可以通过DQN算出 a t + 1 a_{t+1} at+1,这样就可以计算出TD target。
y t = r t + γ ⋅ Q ( s t + 1 , a t + 1 ; w t ) = r t + γ ⋅ max a Q ( s t + 1 , a ; w t ) . \begin{array}{c}{y_{t}=r_{t}+\gamma\cdot Q(s_{t+1},a_{t+1};\mathbf{w}_{t})}\\ {=r_{t}+\gamma\cdot\max_{a}Q(s_{t+1},a;\mathbf{w}_{t}).}\\ \end{array} yt=rt+γ⋅Q(st+1,at+1;wt)=rt+γ⋅maxaQ(st+1,a;wt).
- Loss:
L t = 1 2 [ Q ( s t , a t ; w ) − y t ] 2 L_t=\frac{1}{2}[Q(s_t,a_t;\mathbf{w})-y_t]^2 Lt=21[Q(st,at;w)−yt]2
策略学习
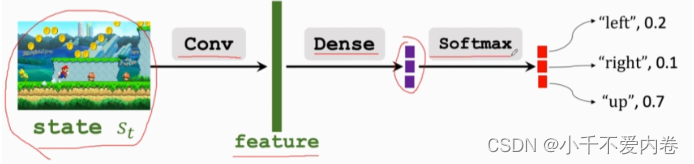
使用一个神经网络近似策略函数。
- ∑ a ∈ A π ( a ∣ s ; θ ) = 1 \sum_{a\in\mathcal{A}}\pi(a|s;\mathbf{\theta})=1 ∑a∈Aπ(a∣s;θ)=1
刚刚把策略函数替换成了神经网络,那么状态价值函数
V π ( s t ) = E A [ Q π ( s t , A ) ] = ∑ a π ( a ∣ s t ) ⋅ Q π ( s t , a ) V_{\pi}(s_{t})=\mathbb{E}_{A}\left[Q_{\pi}(s_{t},A)\right]=\sum_{a}\pi(a|s_{t})\cdot Q_{\pi}(s_{t},a) Vπ(st)=EA[Qπ(st,A)]=a∑π(a∣st)⋅Qπ(st,a)
就变成了
V ( s t ; θ ) = ∑ π ( a ∣ s t ; θ ) ⋅ Q π ( s t , a ) . V(s_t;\theta)=\sum{\pi(a|s_t;\theta)}\cdot Q_\pi(s_t,a). V(st;θ)=∑π(a∣st;θ)⋅Qπ(st,a).
V可以评价当前状态和策略函数的好坏,怎么让策略函数越来越好?
改变神经网络参数 θ \theta θ来使得这个值越来越大。
将目标函数定义为 J ( θ ) = E S [ V ( S ; θ ) ] J({\theta})=\mathbb{E}_{S}[V(S;{\theta})] J(θ)=ES[V(S;θ)],将状态S作为一个随机变量去掉,这样就变成了只剩下对策略网络的评价。
- 观测状态s
- 求导,使得上面目标函数的梯度上升。
这是一个随机梯度,随机性来源于s,s是用随机抽样获得的。
得到两个策略梯度的公式:
∂ V ( s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) . {\frac{\partial V(s;\theta)}{\partial\theta}}=\sum_{a}{\frac{\partial\pi(a|s;\theta)}{\partial\theta}}\cdot Q_{\pi}(s,a). ∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a).
∂ V ( s ; θ ) ∂ θ = E A ∼ π ( ⋅ ∣ s ; θ ) c [ ∂ log π ( A ∣ s , θ ) ∂ θ ⋅ Q π ( s , A ) ] {\frac{\partial V(s;\theta)}{\partial\mathbf{\theta}}}=\mathbb{E}_{A\sim\pi(\cdot|s;\mathbf{\theta})_{c}}\big[{\frac{\partial\log\pi(A|s,\mathbf{\theta})}{\partial\mathbf{\theta}}}\cdot Q_{\pi}(s,A)\big] ∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)c[∂θ∂logπ(A∣s,θ)⋅Qπ(s,A)]
如果动作是离散的,那么就用上面的公式,分别计算各个动作,然后相加。
如果动作是连续的,就用下面的公式,神经网络积分不容易计算。蒙特卡洛近似!抽样一个或者多个样本来近似。
怎么计算Q?两种方法。
- 可以先使用策略函数从头到尾玩一遍游戏,记录下来各个状态、动作、回报。然后使用这些记录的数据来近似。
- 使用神经网络近似。
Actor-Critic方法
Actor:策略网络,用来控制agent运动(Policy Network)
Critic:价值网络,用来给动作打分(Value Network)
V π ( s ) = ∑ a π ( a ∣ s ) ⋅ Q π ( s , a ) V_{\pi}(s)=\sum_{a}\pi(a|s)\cdot Q_{\pi}(s,a) Vπ(s)=a∑π(a∣s)⋅Qπ(s,a)
分别用两个神经网络,一个近似 π \pi π(被称为策略网络,也叫做Actor),一个近似 Q π Q_{\pi} Qπ(Value Network,价值网络),价值网络是给动作打分的。
这样, V π V_\pi Vπ则可以写成:
V π ( s ) = ∑ a π ( a ∣ s ) ⋅ Q π ( s , a ) ≈ ∑ a π ( a ∣ s ; Θ ) ⋅ q ( s , a ; w ) V_{\pi}(s)=\sum_{a}\pi(a|s)\cdot Q_{\pi}(s,a)~~\approx\sum_{a}\pi(a|s;\Theta)\cdot q(s,a;\mathbf{w}) Vπ(s)=a∑π(a∣s)⋅Qπ(s,a) ≈a∑π(a∣s;Θ)⋅q(s,a;w)
策略网络和价值网络的乘积。
策略网络:

价值网络:
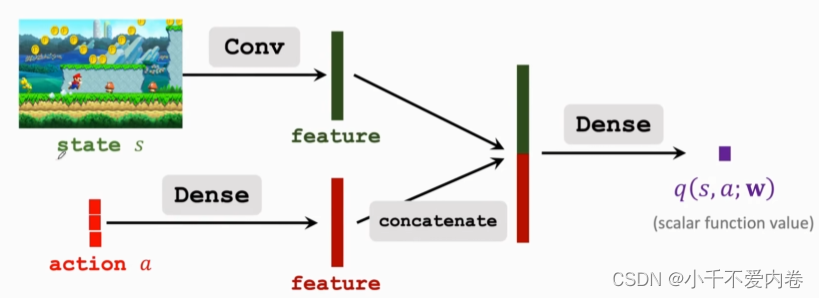
网络训练
V ( s ; θ , w ) = ∑ a π ( a ∣ s ; θ ) ⋅ q ( s , a ; w ) V(s;\mathbf{\theta},\mathbf{w})=\sum_{a}\pi(a|s;\mathbf{\theta})\cdot q(s,a;\mathbf{w}) V(s;θ,w)=a∑π(a∣s;θ)⋅q(s,a;w)
训练:更新参数 θ 和 w \theta 和 w θ和w。
- 更新策略网络是为了让V的值增加,让策略越来越好,让q的得分值越来越高。
- 更新价值网络q是为了让打分值更精准,从而更好的估计未来价值的总和。
五个步骤更新:
- 观测状态 S t S_t St。
- 根据策略网络,随机抽样动作 a t a_t at。
- 执行动作 a t a_t at,更新状态 S t + 1 S_{t+1} St+1,获得奖励 r t r_t rt
- 使用TD算法更新价值网络的参数w。
- 使用策略梯度算法更新策略网络的参数$\theta $,用到了价值网络的参数。

算法步骤:
- 观测状态 S t S_t St并且给根据状态和策略网络随机抽样获得 a t a_t at。
- 执行动作 a t a_t at,环境给出新的状态 S t + 1 S_{t+1} St+1和奖励 r t r_t rt。
- 根据 S t + 1 S_{t+1} St+1和策略网络,随机抽样获得新的动作 a ~ t + 1 \tilde{a}_{t+1} a~t+1。
- 根据价值网络评估 q t = q ( s t , a t ; w t ) q_{t}=q(s_{t},a_{t};\mathbf{w}_{t}) qt=q(st,at;wt)和 q t + 1 = q ( s t + 1 , a ~ t + 1 ; w t ) q_{t+1}=q(s_{t+1},\tilde{a}_{t+1};\mathbf{w}_{t}) qt+1=q(st+1,a~t+1;wt)
- 使用TD算法计算损失 δ t = q t − ( r t + γ ⋅ q t + 1 ) \delta_{t}=q_{t}-(r_{t}+\gamma\cdot q_{t+1}) δt=qt−(rt+γ⋅qt+1)
- 对价值网络进行求导计算梯度 d w , t = ∂ q ( s t , a t ; w ) ∂ w ∣ w = w t \mathbf{d}_{\mathbf{w},t}={\frac{\partial q(s_{t},a_{t};\mathbf{w})}{\partial\mathbf{w}}}\mid_{\mathbf{w}=\mathbf{w}_{t}} dw,t=∂w∂q(st,at;w)∣w=wt。
- 更新网络 w t + 1 = w t − α ⋅ δ t ⋅ d w , t \mathbf{w}_{t+1}=\mathbf{w}_{t}-\alpha\cdot\delta_{t}\cdot\mathbf{d}_{w,t} wt+1=wt−α⋅δt⋅dw,t。
- 对策略网络进行求导 d θ , t = ∂ log π ( a t ∣ s t , θ ) ∂ θ ∣ θ = θ t \mathbf{d}_{\theta,t}={\frac{\partial\log\pi(a_{t}|s_{t},\mathbf{\theta})}{\partial\mathbf{\theta}}}\mid_{\mathbf{\theta}=\mathbf{\theta}_{t}} dθ,t=∂θ∂logπ(at∣st,θ)∣θ=θt。
- 用梯度上升更新网络 θ t + 1 = θ t + β ⋅ δ t ⋅ d θ , t \mathbf{\theta}_{t+1}=\mathbf{\theta}_{t}+\beta\cdot \delta_{t}\cdot\mathbf{\mathbf{d}}_{\theta,t} θt+1=θt+β⋅δt⋅dθ,t。
参考:
https://www.bilibili.com/video/BV1We4y1w7Us?p=6&spm_id_from=pageDriver&vd_source=77cb10b9cc158f4815e8d992103d448b