Requests库的安装
Requests是python网络爬虫与信息提取常用库
Requests安装
pip install requests
安装成功测试一下
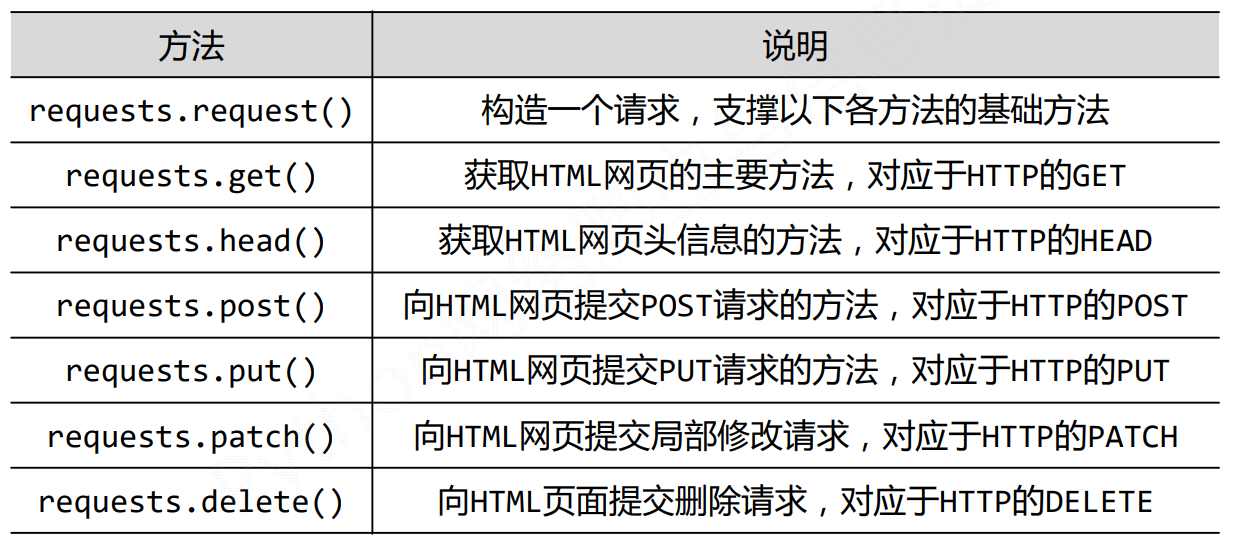
requests库常用的7个方法
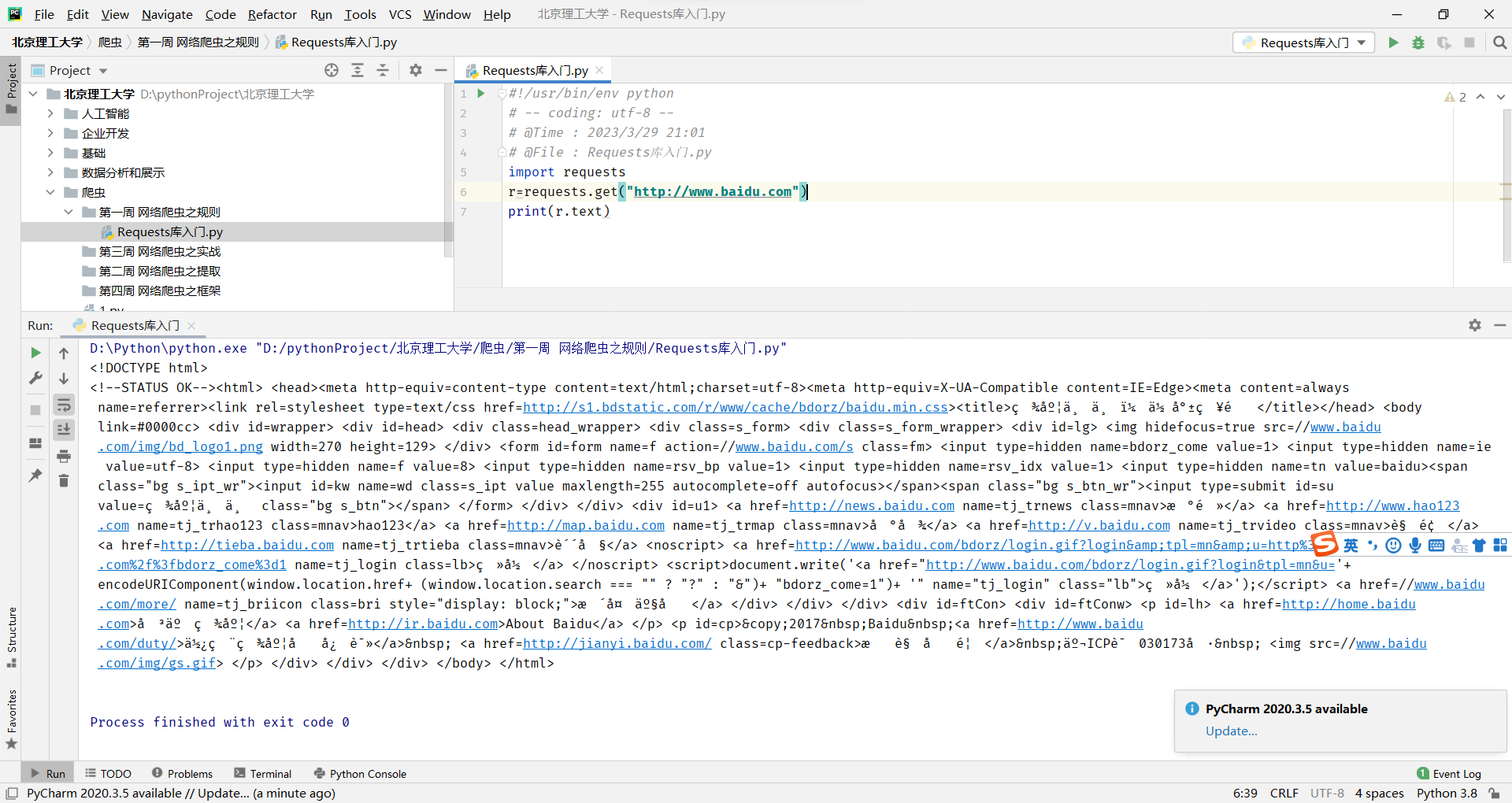
requests.get()

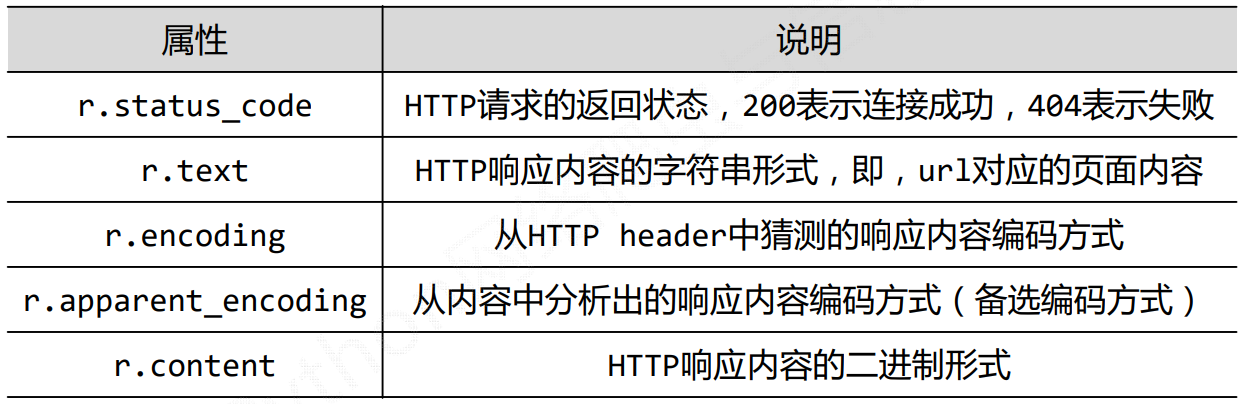
 Response对象包含服务器返回的所有信息,也包含请求的Request信息
Response对象包含服务器返回的所有信息,也包含请求的Request信息
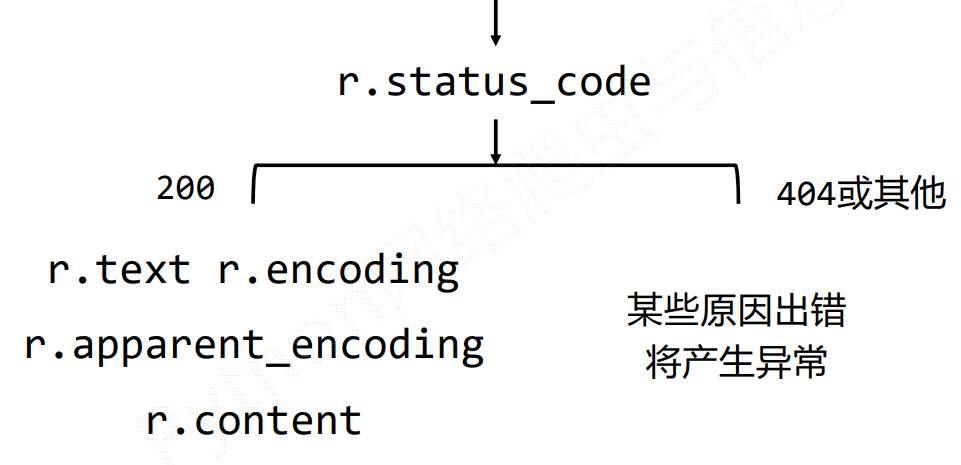 request库的执行流程,判断它的状态码,如果返回的是200那就是成功的,也就是可以从页面中拿数据,否就是失败的
request库的执行流程,判断它的状态码,如果返回的是200那就是成功的,也就是可以从页面中拿数据,否就是失败的
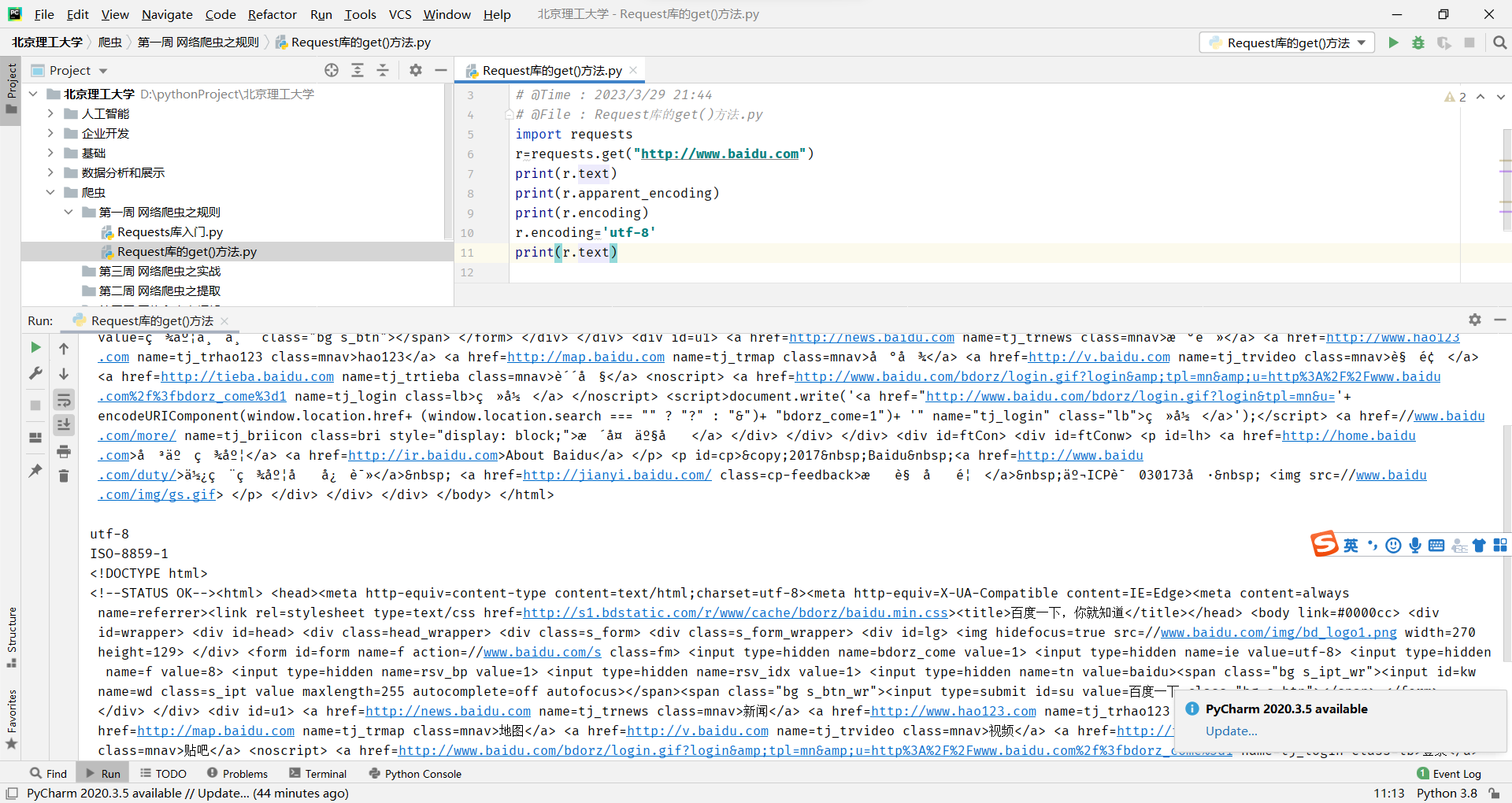
原先是乱码的,通过r.encoding='utf-8',把它变成正确的编码方式
因此我们要理解Request的编码方式

爬取网页的常用框架
首先要理解request库的的异常:网络连接有风险,异常处理很重要
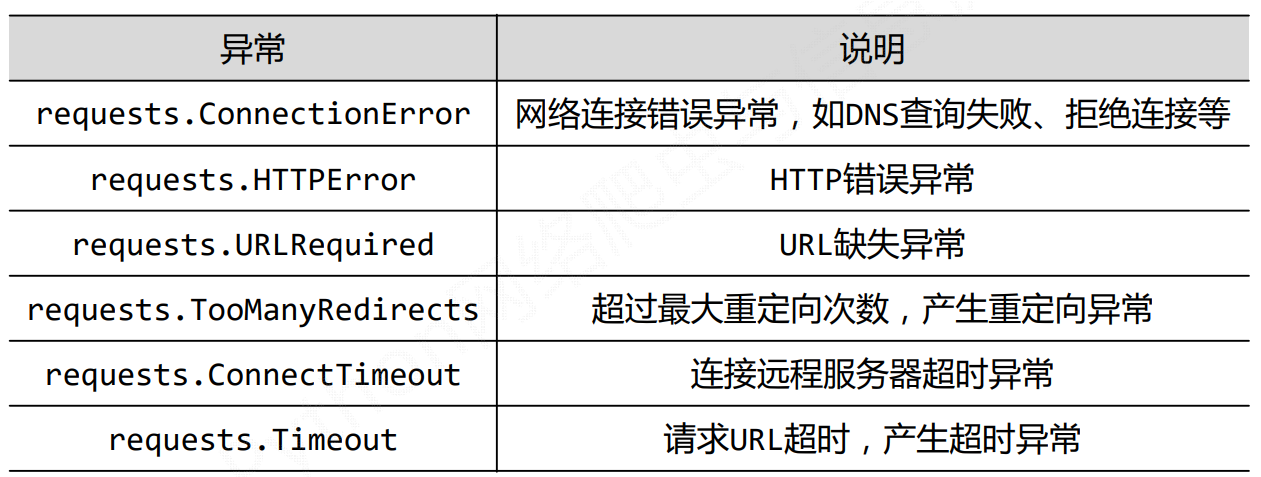
request库提供的7中异常


就是通过raise_for_status()如果状态不是200,引发HTMLERROR异常,否则继续执行
通用代码框架实际上最大的作用就是使得用户访问或爬取网页变得更有效,稳定
HTTP协议及Request库方法
Request库常用7中方法


HTTP协议对资源的操作
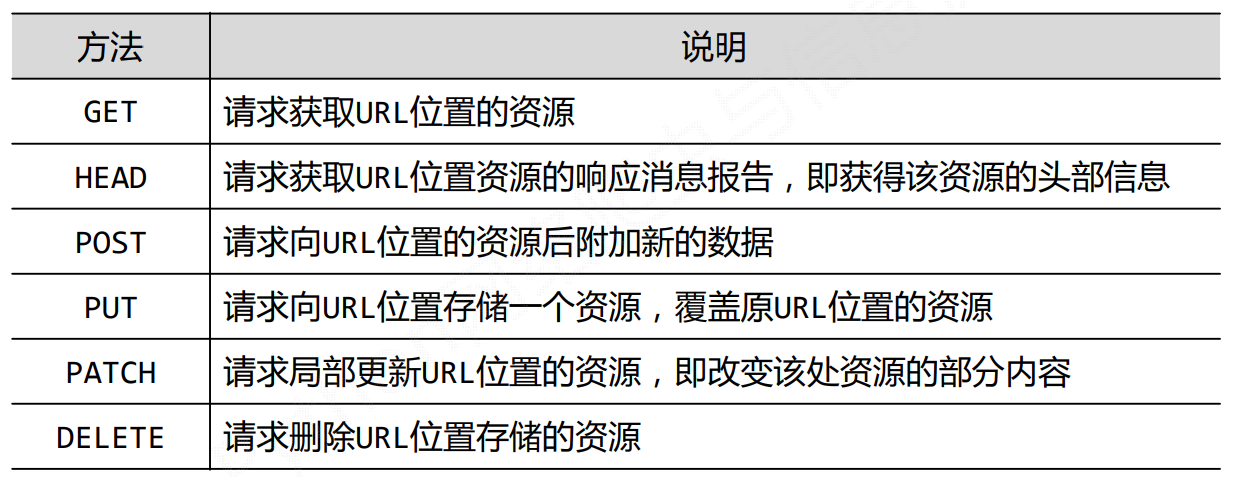
发现request库对应的7种方法对应的整数HTTP协议对资源的操作
 就是patch是局部修改不同的字段,而put是全部修改
就是patch是局部修改不同的字段,而put是全部修改

request库主要方法解析
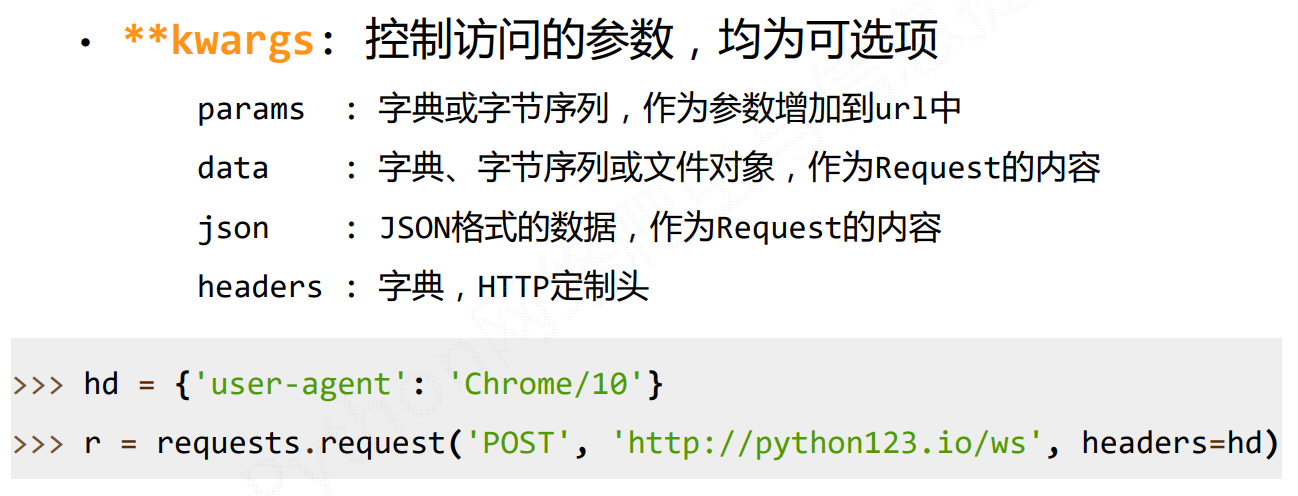
requests.request()方法是基方法,其他都是基于这个分类出去的









网络爬虫的盗亦有道
就是在使用网络爬虫的时候,如果爬取有robots协议的网站,请遵守它

 robots协议在/目录下的robots.txt
robots协议在/目录下的robots.txt
其中Disallow代表不允许爬取 其中*代表所有 /代表跟目录