苦尽甘来

一、仿函数(仿函数就是一个封装()运算符重载的类)
1.C语言的函数指针
1.
仿函数实际就是一个类,这里类实例化出来的对象叫做函数对象,下面命名空间wyn中的两个仿函数就分别是两个类,在使用时直接用类进行实例化对象,然后让对象调用()的运算符重载,这样我们看到的调用形式就非常像普通的函数调用,但实际上这里并不是函数调用,而是仿函数实例化出来的对象调用了自己的operator()重载成员函数。
namespace wyn
{
template <class T>
class less
{
public:
bool operator()(const T& x, const T& y)const
{
return x < y;
}
};
template <class T>
class greater
{
public://将仿函数放成public,要不然class默认是私有的
bool operator()(const T& x, const T& y)const
{
return x > y;
}
};
}
int main()
{
wyn::less<int> lessFunc;
wyn::greater<int> greaterFunc;
lessFunc(1, 2);
//你以为这里是函数调用,但他其实是仿函数对象lessFunc调用了他的成员运算符重载()函数。
}
2.
C++搞出来仿函数的原因是什么呢?他在作用上可以替代C语言里面的函数指针。
在C语言阶段,如果我们想让冒泡排序一会儿排成升序,一会儿排成降序,我们该怎么做呢?我们肯定是通过函数指针的方式来完成,通过所传函数的比较方式来让冒泡排序中比较前后元素大小的逻辑发生改变,如果排升序,就后面元素小于前面元素发生交换,如果排降序,就后面元素大于前面元素发生交换。这样的工作就是由函数指针来完成的,这样的调用方式我们称之为回调函数。
3.
下面这段代码便展示了C语言回调函数的使用形式,可以看到test函数参数为一个函数指针,p指向返回值为void参数为const char *的函数,通过不同的函数名,我们就可以通过函数指针回调不同的函数。
void print( const char* str)
{
printf("%s\n", str);
}
void print1( const char* str)
{
printf("%s\n", str);
}
void test(void(*p)( const char*))
{
p("I LOVE YOU");//调用print函数
p("You are lying");//调用print1函数
}
int main()
{
//函数名代表函数地址
test(print);//传print函数地址
test(print1);//传print1函数地址
return 0;
}
2.C++的仿函数对象
1.
C++觉得函数指针使用起来太挫了,一个指针写那么长,代码可读性太差了,所以C++用仿函数就可以完全取代C语言的函数指针。例如下面的冒泡排序,我们想让冒泡排序是活的,而不是固定只能排升序或降序,在C++中我们就喜欢用仿函数来解决这样的方式。
2.
在对冒泡排序进行泛型编程时,我们利用两个模板参数,一个代表排序的数据类型是泛型,一个代表逻辑泛型,用于修改冒泡排序里面具体排序的逻辑,这个参数接收的就是我们前面所说的仿函数对象,我们将冒泡排序的比较逻辑改为仿函数对象的operator()函数调用,这样就可以通过模板参数的逻辑泛型的类型不同,实例化出不同的仿函数对象,在修改冒泡的比较逻辑那里,就可以调用不同对象所属仿函数类的operator()函数了。
3.
当然如果你觉得先定义出仿函数对象,然后再传仿函数对象比较麻烦的话,你可以直接给冒泡排序传仿函数的匿名对象,这时候就体现出来C++匿名对象的优势所在了。
4.
所以,C语言和C++在解决回调函数这样的方式上,实际函数参数类型就发生了天翻地覆的变化,C语言中的是函数指针类型定义出来的变量作为参数,C++用的是自定义类型仿函数实例化出来的仿函数对象作为参数。并且C++还支持了模板泛型编程,这也解决了代码冗余的问题。
namespace wyn
{
template <class T>
class less
{
public:
bool operator()(const T& x, const T& y)const
{
return x < y;
}
};
template <class T>
class greater
{
public://将仿函数放成public,要不然class默认是私有的
bool operator()(const T& x, const T& y)const
{
return x > y;
}
};
}
template<class T, class Compare>
void BubbleSort(T* a, int n, const Compare com)//传一个仿函数类型,这里的Compare是一个逻辑泛型。
//仿函数没有传引用,因为传值拷贝的代价不大,仿函数所在类中没有成员变量,所以其对象所占字节大小为1,代价很小。
{
for (int j = 0; j < n; ++j)
{
int exchange = 0;
for (int i = 1; i < n - j; ++i)
{
//if (a[i] < a[i - 1])
if (com(a[i], a[i - 1]))//我们不希望这里是写死的,而是希望这里是一个泛型,通过所传参数的不同,调用达到不同
{
swap(a[i - 1], a[i]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
}
}
int main()
{
wyn::less<int> lessFunc;
wyn::greater<int> greaterFunc;
lessFunc(1, 2);//你以为lessFunc是个函数名,但是lessFunc是一个仿函数的对象,函数对象调用运算符重载
//lessFunc.operator()(1,2);
//C语言解决升序降序的问题是通过函数指针来解决的,传一个函数指针,通过调用函数指针来实现升序和降序
//C++觉得使用函数指针太挫了,尤其函数指针的定义形式还特别的长。
//函数模板一般是推演实例化,类模板一般是显示实例化
int arr[] = {
1,3,4,5,6,7,8,2,1 };
BubbleSort(arr, sizeof(arr) / sizeof(int), lessFunc);//传lessFunc,而不是函数指针
//BubbleSort(arr, sizeof(arr) / sizeof(int), wyn::less<int>());//这里可以传一个匿名对象
for (auto e : arr)
{
cout << e << " ";
}
cout << endl;
//BubbleSort(arr, sizeof(arr) / sizeof(int), greaterFunc);
BubbleSort(arr, sizeof(arr) / sizeof(int), wyn::greater<int>());
for (auto e : arr)
{
cout << e << " ";
}
cout << endl;
//利用仿函数的函数对象,取代C语言的函数指针回调这样比较挫的方式。
return 0;
}
二、priority_queue中的仿函数
1.模拟实现优先级队列
1.1 优先级队列的本质(底层容器为vector的适配器)
1.
优先级队列实际就是数据结构初阶所学的堆,堆的本质就是优先级,父节点比子节点大就是大堆,父节点比子节点小就是小堆,这其实就是优先级队列。
可以看到优先级队列中的核心成员函数包括top,push,pop以及迭代器区间为参的构造函数。

2.
priority_queue和queue以及stack一样,他们都是由底层容器适配出来的适配器,之不过priority_queue采用的适配容器不再是deque而是vector,选择vector的原因也非常简单,在调用向上或向下调整算法时,需要大量频繁的进行下标随机访问,这样的情境下,vector就可以完美展现出自己结构的绝对优势。
1.2 向下调整算法建堆
1.
在建堆时如果采用向上调整算法建堆,则算法时间复杂度为O(N*logN),如果采用向下调整算法,则时间复杂度为O(N),所以在建堆时,为了提升效率,采用向下调整算法来进行建堆。
堆的向上向下调整算法的分析
2.
在实现时还是有很多坑的,找出子节点中两个的最大一个和父节点进行比较,但是父节点不一定有右孩子,所以如果你上来就定义left_child和right_child的话,逻辑就出问题了,你只能定义一个child,是否有右孩子还需要进行判断。
3.
这里还涉及一个编程技巧,我们先假设child是子节点中大的那个,然后后面在判断,如果有右孩子,并且右孩子大于左孩子,那我们就让child+=1,这样child始终都表示的是孩子结点中最大的那个结点。(这样的方法称之为假设法,如果假设错误,我们就修改一下,让假设变成对的即可)
4.
向下调整算法的结束条件就是父节点的child小于堆的size大小。
5.
在利用迭代器区间为参的构造函数构造优先级队列时,使用的也是向下调整算法,从堆的倒数第二层的父节点开始进行遍历,依次进行向下调整,直到父节点为根节点时,是最后一次调整。
void adjust_down(size_t parent)//默认建成大堆
{
//父结点一定有左孩子,但不一定有右孩子,所以下面的定义方式是错的。
//size_t left = parent * 2 + 1, right = parent * 2 + 2;
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && _con[child] < _con[child + 1])//必须保证在有右孩子的前提下才能child+=1
child += 1;
if(_con[parent]<_con[child])
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
template <class InputIterator>
priority_queue(InputIterator first,InputIterator last)
:_con(first,last)
{
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; --i)
{
adjust_down(i);//对于建堆来说,向下调整算法比较高,因为不用管最后一行的元素
}
}
1.3 pop堆顶元素时向下调整算法重新调整堆
1.
如果直接pop堆顶元素,利用vector挪动数据的特征,然后从根节点位置开始向下调整堆,这样的方法确实可以将堆重新搞好。
但是挪动数据的消耗可不低,而且一旦挪动数据势必会打乱堆的结构,再次向下调整,那就不是向下调整了,而是向下重新建堆,这也会带来性能的消耗。
2.
所以在pop后,我们采用首尾元素交换的方法,然后尾删掉交换后的尾部元素,最后再从根节点向下调整建堆,而不是在打乱堆结构之后向下调整建堆,这样的方式性能就会高很多了。
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);//pop交换元素之后,老大可能坐的位置不稳了,我们需要判断他是否还有资格坐在老大的位置。
}
1.4 push堆尾元素时向上调整算法重新调整堆
1.
push队尾元素后,我们用父节点和子节点进行比较,直到child到根节点位置的时候,循环结束,利用的思想还是迭代,将父节点和子节点的位置不断向上迭代,直到堆结构调整完毕。
2.
向上和向下调整的核心思想实际都是一样的,都是用父节点和子节点进行比较,唯一不同的就是在建堆这个场景下,向下调整无需考虑最后一层结点,而向下调整需要从最后一层结点开始调整。
两个算法就是一个将父子结点位置向下迭代(adjust_down),一个将父子结点位置向上迭代(adjust_up)。
void adjust_up(size_t child)//默认建成大堆
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (_con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size() - 1);//push插入子结点后,需要向上欺师灭祖,调整自己在族谱的地位。
}
1.5 priority_queue的OJ题
1.
我们可以直接利用优先级队列的结构特点,先利用vector的迭代器区间构造一个默认是大堆的优先级队列,然后依次pop k-1次堆顶的数据,最后的堆顶数据就是第K个最大的元素,直接返回即可。
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
priority_queue<int> q(nums.begin(),nums.end());
while(--k)
q.pop();
return q.top();
}
};
2.
上面那样的方法,需要不断的挪动数据,而且每次都会打乱堆结构,效率比较低。另一种方法就是建造k个数的小堆,然后遍历剩余的vector元素,只要元素大于小堆堆顶元素,我们就pop小堆,然后将遍历到的元素push到小堆里面,等到数组遍历结束之后,小堆中的元素就是数组中前k个最大的元素,小堆堆顶就是第k个最大的元素,然后将此元素返回即可。
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
priority_queue<int, vector<int>, greater<int>>
kq(nums.begin(), nums.begin()+k);//构造k个数的小堆
for(int i=k; i<nums.size(); i++)
{
if(nums[i] > kq.top())
{
kq.pop();
kq.push(nums[i]);
}
}
return kq.top();
}
};
2.在优先级队列中增加仿函数(类模板参数和函数模板参数的不同)
1.
在优先级队列中增加仿函数也是比较简单的,具体的逻辑和前面所说的冒泡排序实际是差不多的,唯一不同的是,冒泡排序那里是函数模板,对于函数模板所传参数是仿函数实例化出来的对象,或者是函数指针类型定义出来的指针变量,所以函数模板接收的参数是变量或者对象。而priority_queue是一个类,类模板接受的是类型,是仿函数这样的自定义类型,或者是其他的内置类型。
2.
下面实现中,我们可以给priority_queue的成员变量多加一个仿函数按照所传类模板参数实例化出来的对象,这样的话只要将adjust_down和adjust_up里面比较的逻辑换成仿函数对象的operator()调用即可,这样的priority_queue就可以根据类模板参数的不同实例化出不同的类,默认建大堆,但只要传greater< int >仿函数,优先级队列就可以建小堆了。
namespace wyn
{
template <class T>
class less
{
public:
bool operator()(const T& x, const T& y)const
{
return x < y;
}
};
template <class T>
class greater
{
public://将仿函数放成public,要不然class默认是私有的
bool operator()(const T& x, const T& y)const
{
return x > y;
}
};
//模板的第三个缺省参数是仿函数,仿函数是一种自定义类型,像类一样,和vector<T>地位一样。
template <class T,class Container = vector<T>,class compare = less<T>>
//默认建堆用的是向下调整,父节点向下和子节点比较,如果父结点小于子节点,发生交换,所以compare缺省参数是less<T>
class priority_queue
{
public:
//只要我们写了构造函数,编译器就不会默认生成,无论你写的是带参的还是不带参的构造,编译器都不会生成。
priority_queue()//自己写一个无参的构造函数
{
}
template <class InputIterator>
priority_queue(InputIterator first,InputIterator last)
:_con(first,last)
{
for (size_t i = (_con.size() - 1 - 1) / 2; i >= 0; --i)
{
adjust_down(i);//对于建堆来说,向下调整算法比较高,因为不用管最后一行的元素
}
}
void adjust_up(size_t child)//默认建成大堆
{
//int parent = (child - 1) / 2;//我们传child==0时,parent是-1,下面会发生越界访问。
size_t parent = (child - 1) / 2;
while (child > 0)
{
//if (_con[child] > _con[parent])
if (comp(_con[parent],_con[child]))
//comp为less<T>()匿名对象时,父节点小于子节点发生交换,默认建大堆
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void adjust_down(size_t parent)//默认建成大堆
{
//父结点一定有左孩子,但不一定有右孩子,所以下面的定义方式是错的。
//size_t left = parent * 2 + 1, right = parent * 2 + 2;
size_t child = parent * 2 + 1;
//while (child < _con.size())
while (child < _con.size())
{
//if (child + 1 < _con.size() && _con[child] < _con[child + 1])//必须保证在有右孩子的前提下才能child+=1
if (child + 1 < _con.size() && comp(_con[child],_con[child+1]))
child += 1;
//if(_con[parent]<_con[child])
if (comp(_con[parent],_con[child]))//这里不是死的,取决于所传的仿函数对象是什么。
{
swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size() - 1);//push插入子结点后,需要向上欺师灭祖,调整自己在族谱的地位。
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);//pop交换元素之后,老大可能坐的位置不稳了,我们需要判断他是否还有资格坐在老大的位置。
}
const T& top()const//非const和const对象都能调用
{
return _con[0];
}
bool empty()
{
return _con.empty();
}
size_t size()const
{
return _con.size();
}
private:
Container _con;//成员变量为自定义类型实例化出来的对象。
compare comp;//仿函数实例化出来的comp对象
};
}
测试wyn优先级队列的仿函数
int main()
{
wyn::priority_queue<int> pq;//默认建大堆,和库里面的priority_queue保持一致
//wyn::priority_queue<int, vector<int>, greater<int>> pq;//大于建小堆,出来的是升序
pq.push(3);
pq.push(1);
pq.push(2);
pq.push(5);
pq.push(7);
pq.push(8);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
//由依次取堆顶元素后的打印结果可知,默认是大堆.
//算法库的默认排序是升序,推荐传参数为随机迭代器sort(RandomAccessIterator first,RandomAccessIterator last)
//优先级队列适配器提供的top返回的是const引用,不允许被修改,如果你修改数据之后,还得手动调用向下调整算法,
//库就需要暴露向下调整算法,这破坏了封装性,所以不可能提供给你普通引用,让你有修改数据的可能性。
return 0;
}
3.仿函数的高级用法(当原有仿函数无法满足要求时,需要重新写满足要求的仿函数)
1.
当优先级队列存储的数据为日期类对象时,在push对象到priority_queue后,一定会出现比较两个日期大小的情况,所以我们必须在日期类里面提供operator>()和operator<()的运算符重载函数,在发生比较时,会先调用仿函数,然后仿函数内部比较对象时,日期类对象就会调用运算符重载。
2.
但是当优先级队列存储的数据不再是日期类对象,而是日期类对象的地址时,那在优先级队列内部比较的时候,就不再是比较日期了,而变成比较地址的大小了,但是各个对象之间的地址又没有关系,这个时候原有的仿函数无法满足我们的要求了,因为我们不是简单的比较存储内容之间的大小了,而是要比较对象地址所指向的内容,那么这个时候就需要重新写仿函数。
3.
重新写的仿函数也比较简单,只需要将优先级队列内容先进行解引用,拿到地址所指向的内容后,再对指向的内容进行比较,这个时候就回到刚开始的日期类对象之间的运算符重载的调用了。
4.
在显示实例化类模板时,我们就不再使用之前的仿函数,而是使用新写的仿函数,这个仿函数可以支持优先级队列存储内容为日期类对象地址的这样一种情况。
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{
}
bool operator<(const Date& d)const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
friend ostream& operator<<(ostream& _cout, const Date& d)//友元函数
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
private:
int _year;
int _month;
int _day;
};
struct PDateLess
{
bool operator()(const Date* d1, const Date* d2)
{
return *d1 < *d2;//直接调用成员函数
}
};
struct PDateGreater
{
bool operator()(const Date* d1, const Date* d2)
{
return *d1 > *d2;
}
};
void TestPriorityQueue()
{
// 大堆,需要用户在自定义类型中提供<的重载
priority_queue<Date> q1;
q1.push(Date(2018, 10, 29));//让优先级队列存储日期类的匿名构造
q1.push(Date(2018, 10, 28));
q1.push(Date(2018, 10, 30));
cout << q1.top() << endl;
// 如果要创建小堆,需要用户提供>的重载
priority_queue<Date, vector<Date>, greater<Date>> q2;//用库里面模板的仿函数
q2.push(Date(2018, 10, 29));
q2.push(Date(2018, 10, 28));
q2.push(Date(2018, 10, 30));
cout << q2.top() << endl;
//大堆
priority_queue<Date*, vector<Date*>, PDateLess> q3;//用自己写的仿函数,没搞模板,这里只针对日期类,不用模板也行。
q3.push(new Date(2018, 10, 29));
q3.push(new Date(2018, 10, 28));
q3.push(new Date(2018, 10, 30));
cout << *q3.top() << endl;
// 如果要创建小堆,需要用户提供>的重载
//小堆
priority_queue<Date*,vector<Date*>,PDateGreater> q4;
//优先级队列底层的vector存的是日期类的指针,比较大小的时候按照日期类对象的地址进行比较,而不是日期的大小进行比较
//所以我们需要自己写仿函数,用wyn里的那个仿函数已经无法满足我们的要求了。
q4.push(new Date(2018, 10, 29));
q4.push(new Date(2018, 10, 28));
q4.push(new Date(2018, 10, 30));
cout << *q4.top() << endl;
}
int main()
{
TestPriorityQueue();
return 0;
}
三、reverse_iterator(正向迭代器适配器)
1.反向迭代器的思想(代码复用,适配模式,类封装)
1.
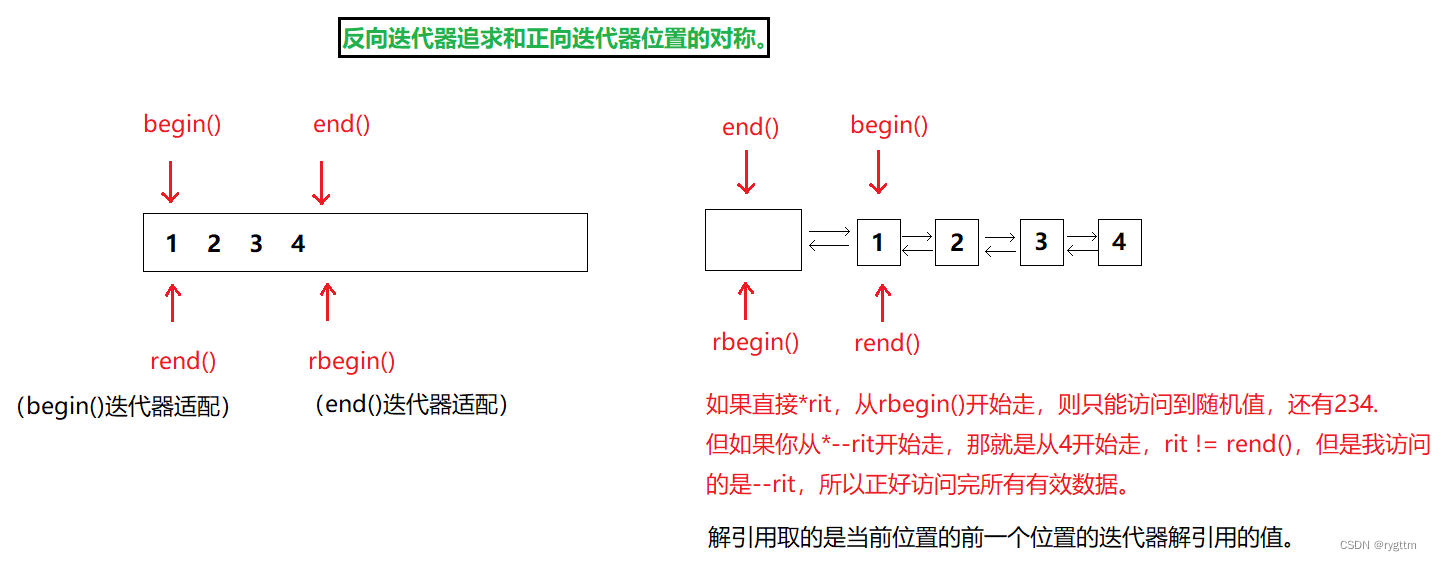
单向迭代器是不用支持反向迭代器的,例如单链表的迭代器就是单向迭代器,但是双向迭代器和随机迭代器都要支持反向迭代器,从使用的角度来看,其实反向迭代器的++就是正向迭代器的 - -,反向迭代器的 - -就是正向迭代器的++,只不过反向迭代器的rbegin是从end的前一个位置开始的,他的rend是到begin位置结束的。
2.
所以从上面反向迭代器和正向迭代器的关系我们就可以看出一些猫腻,反向迭代器的功能完全可以由正向迭代器来实现,那我们是不是可以封装正向迭代器变成一个新的类,这个类实例化出的对象就可以满足反向迭代器的要求。这里的思想实际又回到list的迭代器实现那里了,原生指针无法满足list迭代器的要求,那就封装原生指针为一个新的类,让这个类实例化出来的对象能够满足list迭代器的要求。是不是回到当初类封装的思想了呢?
3.
所以反向迭代器就是正向迭代器适配器,这里还是利用已有的东西封装出你想要的东西的设计思想,这样的思想就是适配模式。反向迭代器也支持++ - - * 解引用→!=等运算符重载,我们利用相应的正向迭代器完成这些运算符重载的功能。
4.
我们用一个类模板来完成反向迭代器的泛型编程,这样无论你是什么容器的正向迭代器,我都可以适配出相应的反向迭代器,反向迭代器的类模板与正向迭代器很相似,后两个参数分别为T&和T*,在实例化反向迭代器时,可以传const或非const的模板参数,以此来实例化出const或非const反向迭代器。
2.反向迭代器与正向迭代器位置的对称
1.
访问反向迭代器数据时,我们返回当前位置的前一个位置的迭代器,这样就可以正好访问完所有的有效数据,否则对于链表来说rbegin指向的正好是头结点位置,并且遍历的时候rbegin!=rend的话,rend位置的数据还无法访问到。
但又为了支持两个迭代器的对称,所以在解引用反向迭代器时,返回的是前一个位置的迭代器内容,修改完*运算符重载后,→的运算符重载也会由于代码复用被修改,我们无需关心。
Ref operator*()
{
Iterator tmp = _it;
return *--tmp;//返回的是当前位置的前一个位置的迭代器内容
}
Ptr operator->()
{
return &(*_it);
}
2.
实现const反向迭代器时,可以增加模板参数来解决,道理和之前实现const正向迭代器类似,这里也增加了Ref和Ptr两个模板参数,通过实例化类模板时所传参数便可以实现const_reverse_iterator
template <class Iterator, class Ref, class Ptr>
//用传过来的正向迭代器去适配出反向迭代器,这里是一个迭代器的模板,所有容器的迭代器都要适配出反向迭代器。
//Ref和Ptr分别对应const或非const版本的数据类型和数据类型的指针,对应着实现*和→两种解引用运算符的重载函数
class ReverseIterator
{
typedef ReverseIterator<Iterator, Ref, Ptr> Self;
public:
ReverseIterator(Iterator it)//用正向迭代器构造反向迭代器
:_it(it)
{
}
Ref operator*()
{
Iterator tmp = _it;
return *--tmp;//返回的是当前位置的前一个位置的迭代器内容
}
Ptr operator->()
{
return &(*_it);
}
Self& operator++()
{
--_it;
//只有双向迭代器和随机迭代器需要反向迭代器,单链表的单向迭代器是不需要反向迭代器的,因为他的迭代器只能++不能--
return *this;
}
Self& operator--()
{
++_it;
return *this;
}
bool operator!=(const Self& s)const
{
return _it != s._it;//两个由正向迭代器适配出来的反向迭代器进行比较。
}
private:
Iterator _it;//这里的迭代器有可能是原生指针,也有可能是类封装后迭代器类实例化出的对象。
};
3.
下面的vector和list容器都可以通过自身的正向迭代器来完成反向迭代器的适配。
#include "Iterator.h"
namespace wyn
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
typedef ReverseIterator<iterator, T&, T*> reverse_iterator;
typedef ReverseIterator<const_iterator, T&, T*> const_reverse_iterator;
reverse_iterator rbegin()
{
return reverse_iterator(end());
}
reverse_iterator rend()
{
return reverse_iterator(begin());
}
const_reverse_iterator rbegin()const
{
return const_reverse_iterator(end());
}
const_reverse_iterator rend()const
{
return const_reverse_iterator(begin());
}
}
template<class T>
class list
{
typedef list_node<T> node;
public:
typedef __list_iterator<T,T&,T*> iterator;//iterator是类模板的typedef,模板也是类型,只不过还没有实例化
//typedef __list_const_iterator<T> const_iterator;
typedef __list_iterator<T,const T&,const T*> const_iterator;
typedef ReverseIterator<iterator, T&, T*> reverse_iterator;
typedef ReverseIterator<const_iterator, const T&, const T*> const_reverse_iterator;
//反向迭代器就是正向迭代器的适配器
reverse_iterator rbegin()
{
return reverse_iterator(end());
}
reverse_iterator rend()
{
return reverse_iterator(begin());
}
const_reverse_iterator rbegin()const
{
return const_reverse_iterator(end());
}
const_reverse_iterator rend()const
{
return const_reverse_iterator(begin());
}
}