B树
在前面几章中我们介绍了AVL树和红黑树,简单复习一下,我们说到原本的二叉搜索树会存在缺陷(不能保证树的平衡,可能会退化成一个链表),由此引入了AVL树和红黑树来限制树的高度,以提高搜索的效率。
但是,不管是以上的哪种树,在对树进行元素查找的时候,都是需要先将数据加载到内存中再进行查找的,而如果数据量太大,以至于内存已经存储不下了,那么再使用上面的这些数据结构就都不成立了。
为了解决这个问题,就引出了一种适合外查找(也就是不需要依赖内存,一般来说外部查找是在磁盘或其他外部存储设备上进行的)的树,它是一种平衡的多叉树,称为B树。
其中,一颗M阶的B树,是一颗平衡的M路平衡搜索树,可以是空树或者是满足以下的性质:
(1)根节点至少有两个孩子。
(2)每个非根节点至少有M/2-1(上取整)个关键字,至多有M-1个关键字,并且以升序排序。
(3)每个非根节点至少有M/2(上取整)个孩子,至多有M个孩子。
(4)key[i]和key[i+1]之间的孩子节点的值是介于key[i]和key[i+1]之间的。
(5)所有叶子节点都在同一层上。
以上是B树的性质,在操作B树无论什么时候都要遵循这些性质,下面以一个简单的例子看一下B树插入的流程:
第一阶段:
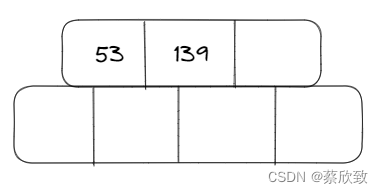
当插入一个元素值为75的时候:

第二阶段:
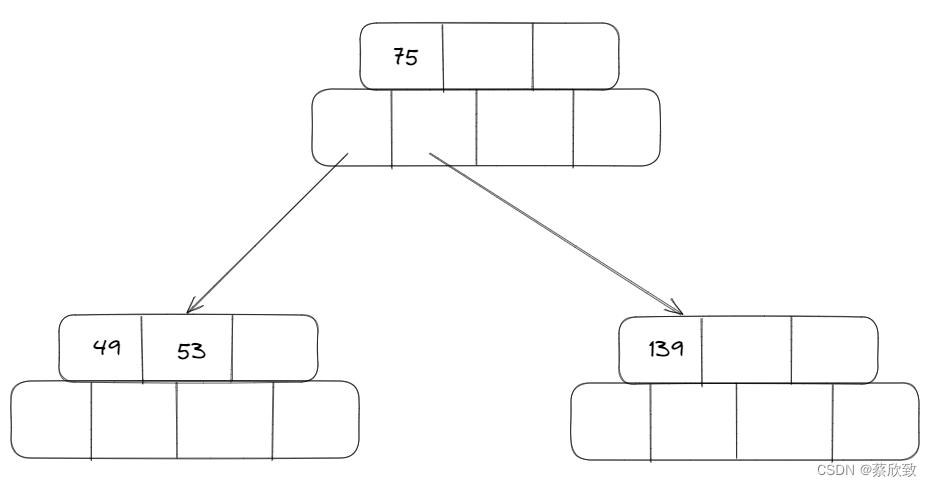
当插入一个元素值为36的时候:
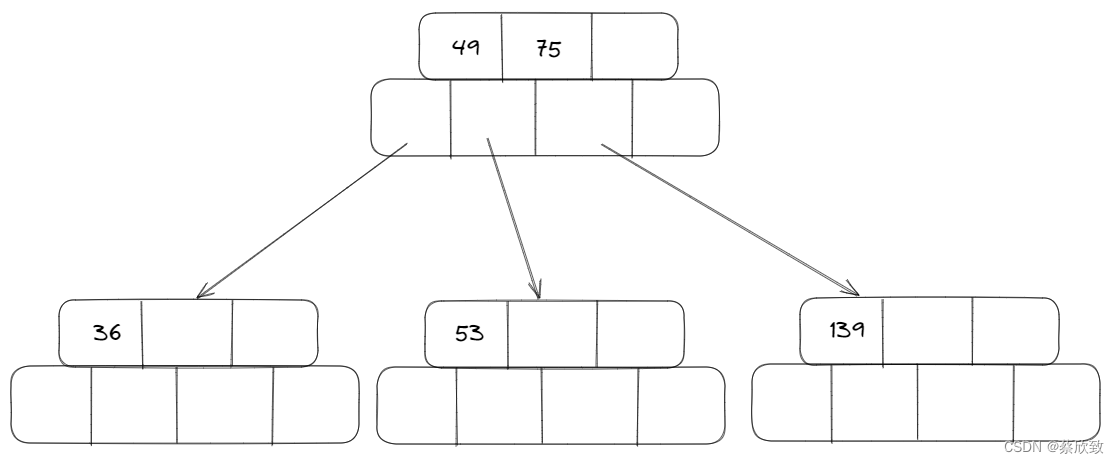
第三阶段:
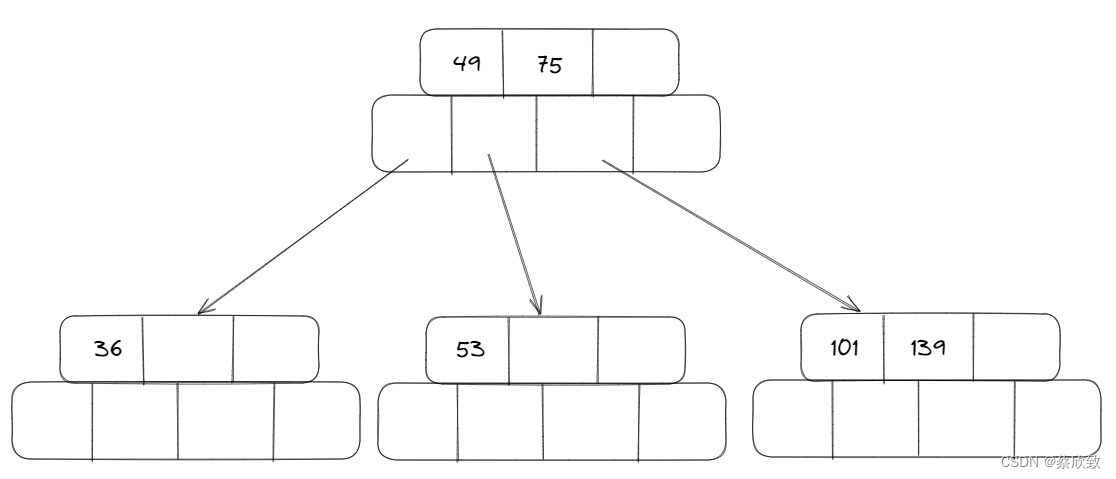
当插入一个元素值为145的时候:
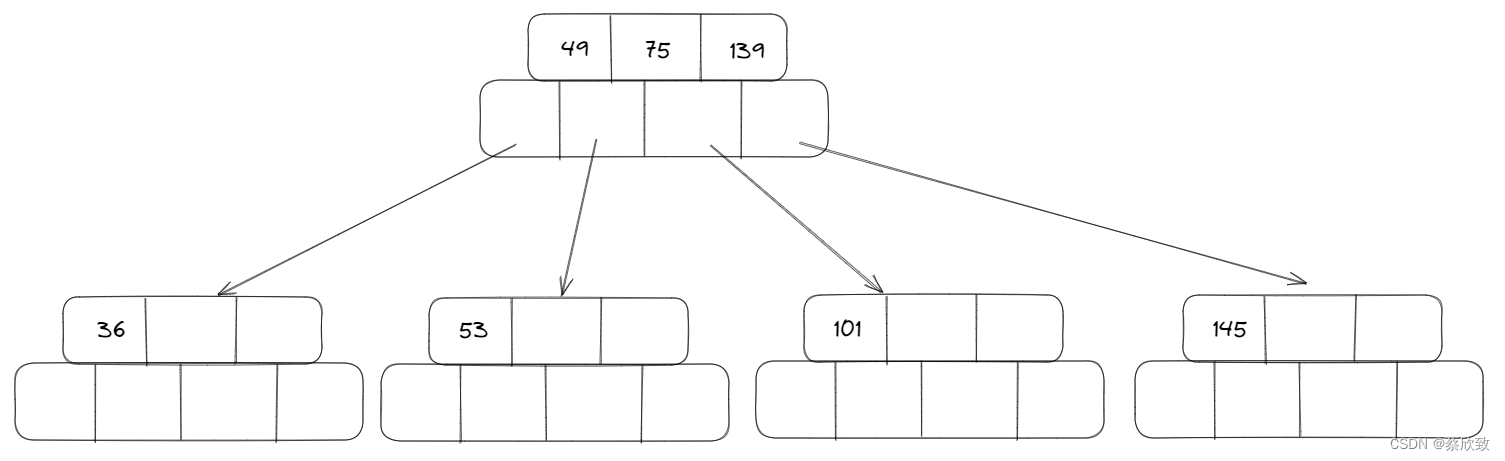
首先会变成这样,但是不满足B树的性质,所以还需要继续调整:
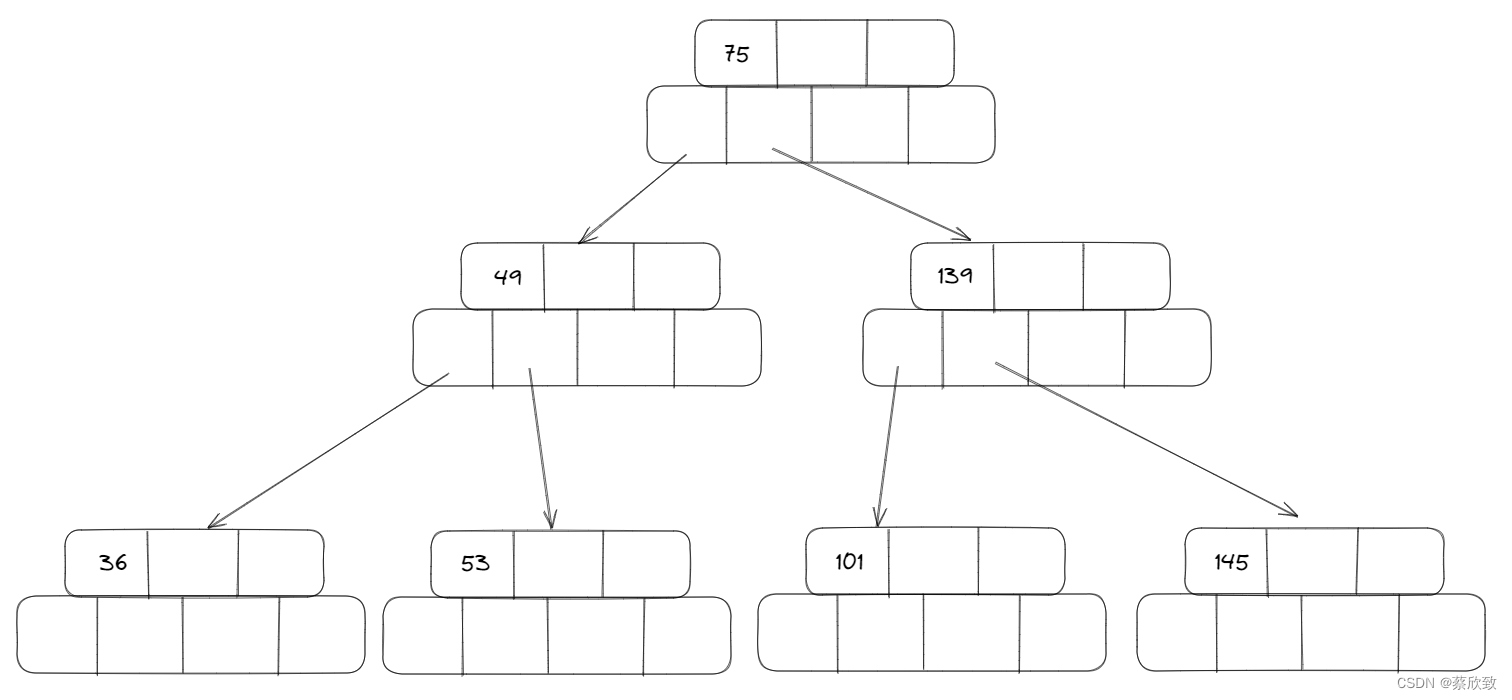
总结:
1. 如果树为空的话,直接插入新节点中,该节点为树的根节点。
2. 树非空的时候,找待插入元素在树中的插入位置(找到的插入节点位置一定要在叶节点中)。
3. 检测是否找到插入位置(假设树中的key唯一,即这个元素已经存在,不允许再插入)。
4. 按照插入排序的思想将该元素插入到找到的节点中。
5. 检测节点是否满足B树的性质(即该节点中的元素个数是否等于M,如果小于则满足)。
6. 如果插入后节点不满足B树的性质,则需要对该节点进行分裂(申请新节点、找到该节点的中间位置、将该节点中间位置右侧的元素以及其孩子搬移到新节点中、将中间位置元素以及新节点往该节点的双亲节点中插入)。
7. 如果向上已经分裂到根节点的位置,则插入结束。
B树节点的设计
static class BTreeNode{
public int[] keys; //关键字
public BTreeNode[] subs; //孩子
public BTreeNode parent; //父节点
public int usedSize; //关键字数量
public BTreeNode(){
this.keys = new int[M];
this.subs = new BTreeNode[M + 1];
}
}
插入key的过程
//插入操作
public boolean insert(int key){
if(root == null){
root = new BTreeNode();
root.keys[0] = key;
root.usedSize++;
return true;
}
//首先查看当前树中是否存在key节点
Pair<BTreeNode, Integer> pair = find(key);
if(pair.value != -1){
return false;
}
BTreeNode parent = pair.key;
int index = parent.usedSize - 1;
for(; index >= 0; index--){
if(parent.keys[index] >= key){
parent.keys[index + 1] = parent.keys[index];
}else{
break;
}
}
parent.keys[index + 1] = key;
parent.usedSize++;
if(parent.usedSize >= M){
split(parent);
return true;
}else{
return true;
}
}
//分裂当前节点
private void split(BTreeNode cur) {
BTreeNode newNode = new BTreeNode();
BTreeNode parent = cur.parent;
int mid = cur.usedSize >> 1;
int i = mid + 1;
int j = 0;
for(; i < cur.usedSize; i++, j++){
newNode.keys[j] = cur.keys[i];
newNode.subs[j] = cur.subs[i];
//记得更新父节点
if(newNode.subs[j] != null){
newNode.subs[j].parent = newNode;
}
}
newNode.subs[j] = cur.subs[i]; //记得多拷贝一次
//记得更新父节点
if(newNode.subs[j] != null){
newNode.subs[j].parent = newNode;
}
//更新新节点的参数
newNode.parent = parent;
newNode.usedSize = j;
cur.usedSize = cur.usedSize - j - 1;
//特殊处理根节点的情况
if(cur == root){
root = new BTreeNode();
root.keys[0] = cur.keys[mid];
root.subs[0] = cur;
root.subs[1] = newNode;
root.usedSize = 1;
cur.parent = root;
newNode.parent = root;
return;
}
int endT = parent.usedSize - 1;
int midVal = cur.keys[mid];
for(; endT >= 0; endT--){
if(parent.keys[endT] >= midVal){
parent.keys[endT + 1] = parent.keys[endT];
parent.subs[endT + 2] = parent.subs[endT + 1];
}else{
break;
}
}
parent.keys[endT + 1] = midVal;
parent.subs[endT + 2] = newNode;
parent.usedSize++;
if(parent.usedSize >= M){
split(parent);
}
}
//查找元素是否在树中存在
private Pair<BTreeNode, Integer> find(int key) {
BTreeNode cur = root;
BTreeNode parent = null;
while(cur != null){
int i = 0;
while(i < cur.usedSize){
if(cur.keys[i] == key){
return new Pair<>(cur, i);
}else if(cur.keys[i] < key){
i++;
}else{
break;
}
}
parent = cur;
cur = cur.subs[i];
}
return new Pair<>(parent, -1);
}
B树的验证
对B树的验证其实就是对B树进行中序遍历,如果此时能得到一个有序的序列,那么则可以说明B树的插入是正确的。
private void inorder(BTreeNode root){
if(root == null)
return;
for(int i = 0; i < root.usedSize; ++i){
inorder(root.subs[i]);
System.out.println(root.keys[i]);
}
inorder(root.subs[root.usedSize]);
}
B树的性能分析
对于一棵节点为N度为M的B树来说,树的高度会在log(M-1)N和log(M/2)N之间,采用二分查找的方式可以快速定位到该元素,大大减少了读取磁盘的次数。
B+树和B*树
B+树
B+树也是一种多路搜索树,是B树的一种变形,他的定义基本和B树是相同的。
不同点:
1. 非叶子节点的子树指针与关键字个数相同。
2. 非叶子节点的子树指针p[i],指向关键字值属于(k[i], k[i+1])的子树。
为所有叶子节点增加一个链指针。
5. 所有关键字都在叶子节点出现。
以下是B+树的基本示意图(辅助理解):
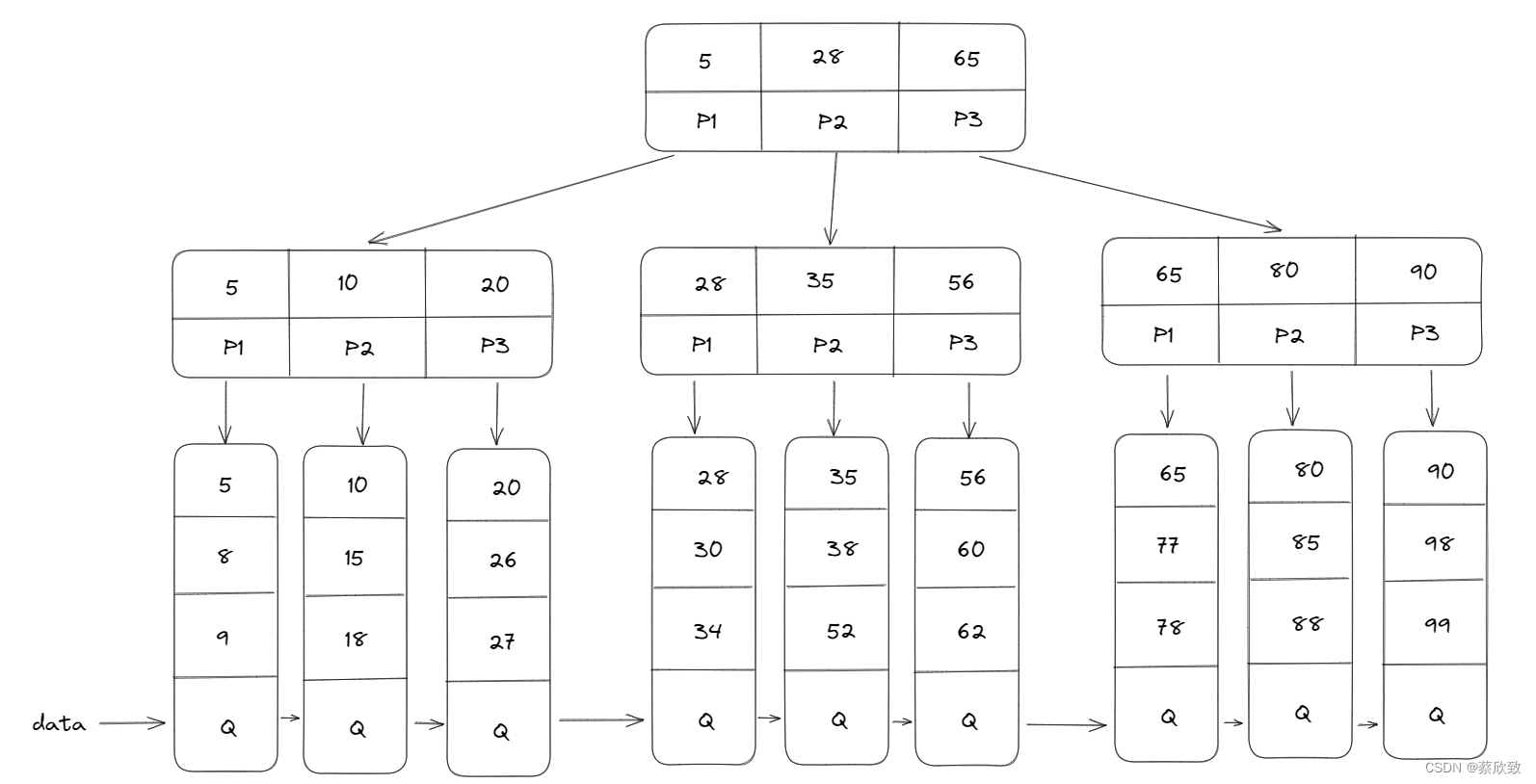
总结: B+树的搜索基本上和B树是相同的,区别是B+树只有达到叶子节点才能命中(B树可以在非叶子节点中命中),此处的命中指的是查询插入操作,他的性能也是等价于在关键字全集做一个二分查找。所有关键字都出现在叶子节点的链表中(稠密索引),且链表中的节点都是有序的;非叶子节点相当于是叶子节点的稀疏索引(不可能会在非叶子节点中命中),叶子节点相当于是存储数据的数据层;综上所述:B+树整体上来说,会更适合做文件索引的系统。
B*树
B*树又是B+树的变形,在B+树的非根和非叶子节点再增加指向兄弟节点的指针。
以下是B树的基本示意图(辅助理解):
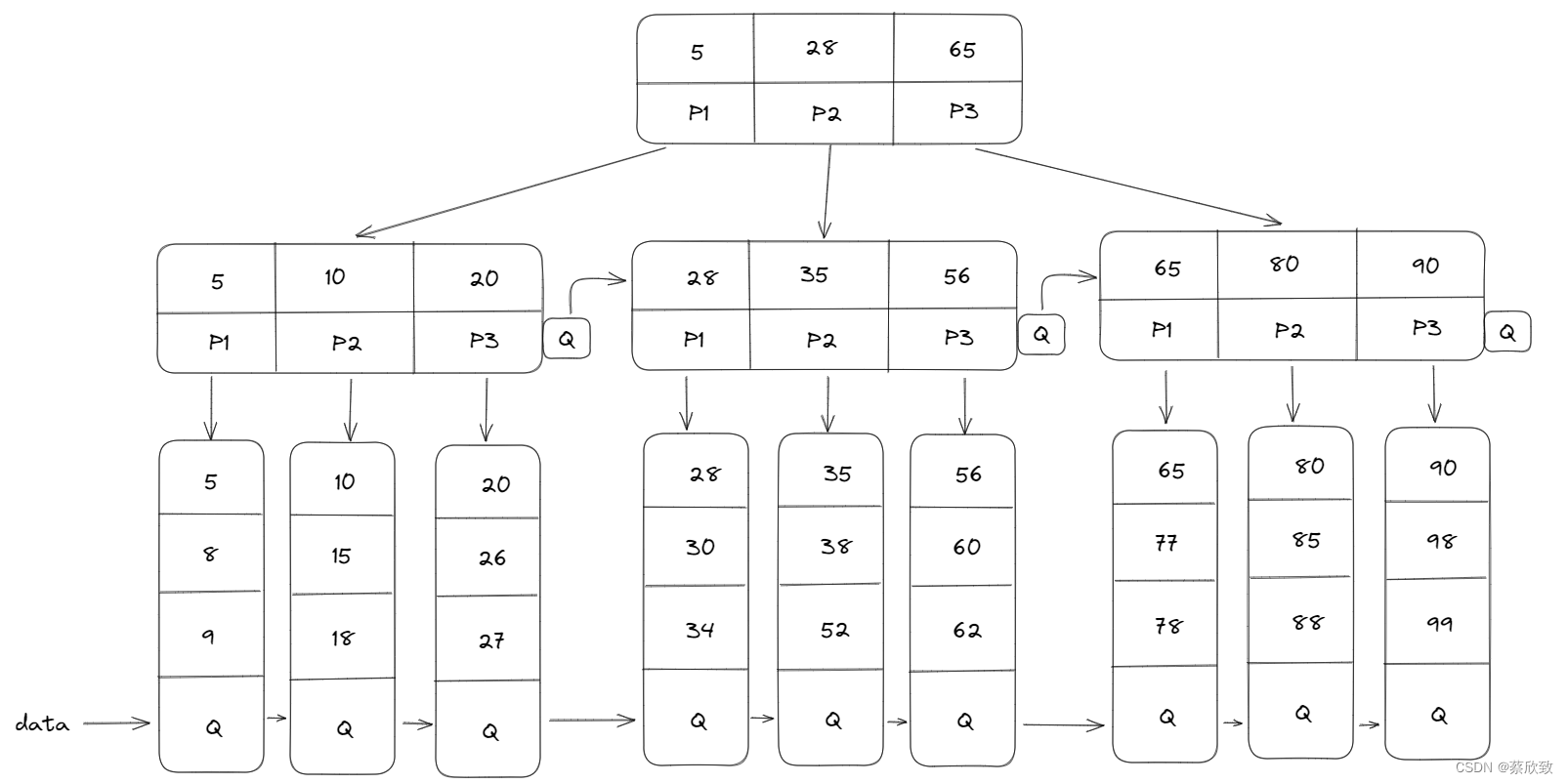
总结: B树在分裂的时候,当一个节点满的时候,如果它的下一个兄弟节点未满,那么将一部分数据移到兄弟节点中,再在原节点插入关键字,最后修改父节点中的兄弟节点的关键字,最后修改父节点中兄弟节点的关键字(因为兄弟节点的关键字范围被改变了);如果兄弟也满了,则会在原节点与兄弟节点之间增加新节点,并各复制1/3的数据到新节点,最后在父节点增加新节点的指针。所以,B*树分配新节点的概率比B+树要低,空间的使用率更高。
总结B树、B+树、B*树
B树:多路搜索树,每个节点存储M/2到M个关键字,非叶子节点存储指向关键字范围的子节点,所有关键字在整棵树中只会出现一次,非叶子节点可以命中。
B+树:在B树的基础上,为叶子节点增加链表指针,所有关键字都在叶子节点中出现,非叶子节点仅作为叶子节点的索引,只有到叶子节点才会被命中。
B*树:在B+树的基础上,为非叶子节点也增加了链表指针,将节点的最低利用率从1/2提高到2/3。
B树的应用
做索引
B树最常见的应用就是用来做索引。索引通俗来说就是为了方便用户快速找到目标的东西,例如我们的搜索网站,本质上就是互联网页面中的索引结构,有了这个索引就可以快速找到有价值的分类网站(这让我想到之前做的搜索引擎项目中倒排索引的构建,是比较相似的)。
索引在MySQL数据库中也有被应用,MySQL官方对索引的定义:索引是帮助MySQL高效获取的数据结构,当数据量很大的时候,为了能够方便管理数据,提高数据查询的效率,一般都会选择将数据保存到数据库中,因此数据库不仅仅是帮助用户管理数据,而且还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法,这个数据结构就是索引。
MySQL索引
对于MySQL底层使用的数据结构,我之前有写过一篇相关文章,地址:https://blog.csdn.net/Faith_cxz/article/details/125871321?spm=1001.2014.3001.5501,可以当做部分参考~
MyISAM
MyISAM引擎是MySQL5.5.8版本之前默认的存储引擎,不支持事务,支持全文检索,使用B+树作为索引结构,叶节点的data域存放的是数据记录的地址。
MyISAM中索引检索的算法为首先按照B+树搜索算法搜索索引,如果指定的key存在,则取出其data域的值,然后以data域的值为地址,读取相应的数据记录,MyISAM的索引方式也叫做“非聚簇索引”。(关于聚簇索引和非聚簇索引的相关知识点可以先简单看一下这篇文章:一分钟明白MySQL聚簇索引和非聚簇索引)
InnoDB
InnoDB存储引擎支持事务,其设计目标主要面向在线事务处理的应用,从MySQL5.5.8版本开始,InnoDB存储引擎就是默认的存储引擎。InnoDB支持B+树索引、全文索引、哈希索引,但是InnoDB使用B+树作为索引结构是,具体的实现方式与MyISAM是不一样的。
区别一: MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址;而InnoDB的表数据文件本身就是按B+树组织的索引结构,这棵树的叶节点data域保存了完整的数据记录,这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
区别二: InnoDB的辅助索引data域存储相应记录主键的值而不是地址,所有辅助索引都引用主键作为data域。聚簇索引的这种实现方式使得按主键的搜索十分高效,但是辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
注意:索引是基于表的,不是基于数据库的。
由于本文总结的是B树和B+树相关的知识点,所以MySQL的底层简略带过,后面我会查阅更多文章,总结出MySQL详细的知识点~