一.概念:
- Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。
- 存储,计算,搜索
- Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)
- ELK的核心:
- 存储,搜索和分析数据
- Kibana:数据可视化(可视化界面)
- Logstash 数据抓取
- es的来源:
- 基于lucene,他也是一个搜索引擎,Apache下的一个顶级项目,是基于Java的类库
- Lucene的优势:
- 易扩展,高性能(基于倒排索引)
- Lucene的缺点:
- 只限于Java,不支持水平扩展
- ES的优势:
- 支持分布式,支持水平扩展,
- 提供restfull接口,可以被任何语言使用
- 为什么要学es
- 目前排名:第一,es;第二,splunk;第三,solr(Apache基金会)
- 架构分析:
-
,mysql事物类型的搜索
-
-
必须要清楚:什么是es,elk,lucene?
- 正向索引,倒排索引
- id title price
- 1 小米手机 2000
- 2 华为手机 5000
- 3 小米手环 5000
- 词条term 文档ID
- 小米 1,3
- 手机 1,2
- 华为 2
- 小米手环 3
- 文档document 相当于一条记录row
- 什么是文档,什么是词条?
- 词条:文档内容进行分词,得到的词语就是词条
- 正向索引,倒排索引
- es是面向文档来存储的。
- 文档数据会被序列化为json格式后,存储在es中
- 索引:
- 文档的集合,可以对比理解为表
- 用户索引,商品索引,订单索引,图书索引。。。
- 映射mapping
- 索引当中文档的字段约束信息,可以理解为表中结构的约束
- es与MySQL的对应关系类比
- MySQL es
- table index
- row document
- column field
- schema mapping
- sql DSL
- 架构分析对比:
- MySQL:事务类型的操作,可以保证数据的安全和一致性
- es: 海量数据数据的搜索,分析,计算
二.使用
- 右键会话,将es.tar,kibana.tar拖上去

- 我们上面的操作其实也可以直接拉取,但是文件太大,下载好从客户端上传镜像直接拖会快
- 要让es和kibana互联,所以需要先创建网络(es-net名字随便起)
-
docker network create es-net 
-
-
加载es镜像
-
docker load -i es.tar 
-
- 创建容器
-
docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.1 -

-
-
查看 docker images
-
-
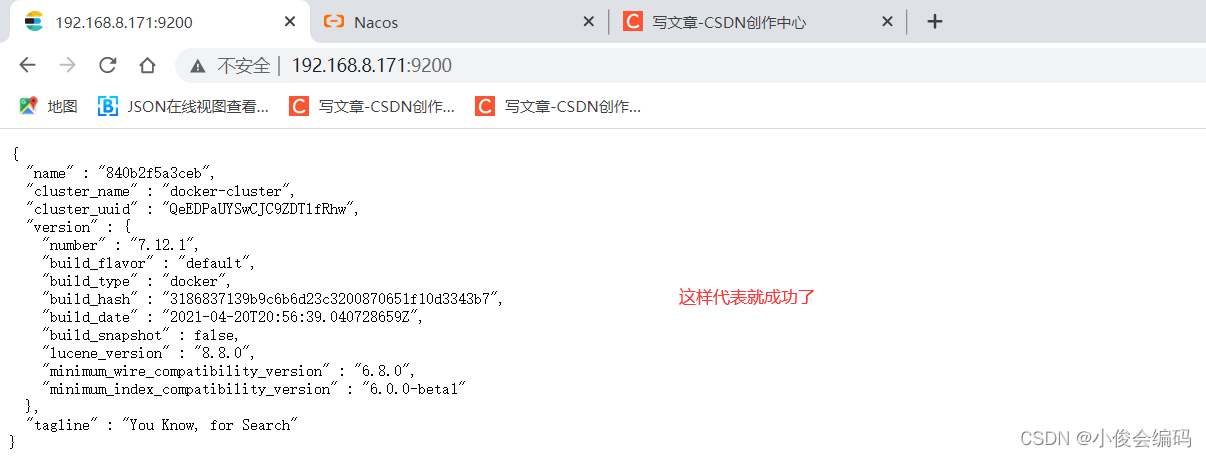
查看是否成功启动
-
http://192.168.8.171:9200/ -
-
-
加载kibana镜像
-
docker load -i kibana.tar -

-
-
创建kibana容器
-
docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.12.1 -

-
-
启动容器需要时间,下面查看日志
-
docker logs -f kibana
-
-
浏览器访问查看是否成功(注意IP不要填我的哈)
-
http://192.168.8.171:5601/
-
-
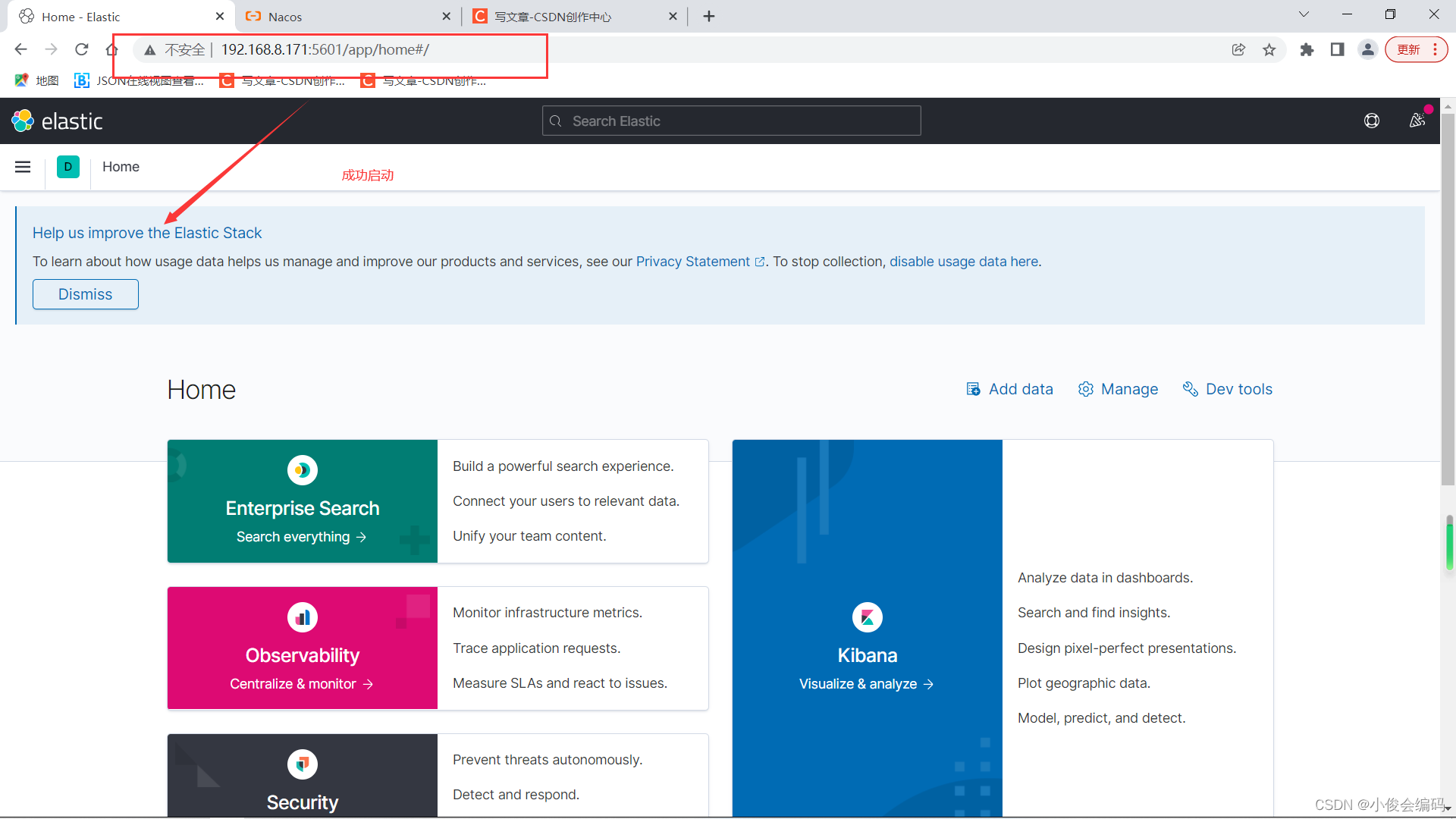
-
选explore on my own进入
-
进入可视化工具,进入我们要用的地方(dev tools)
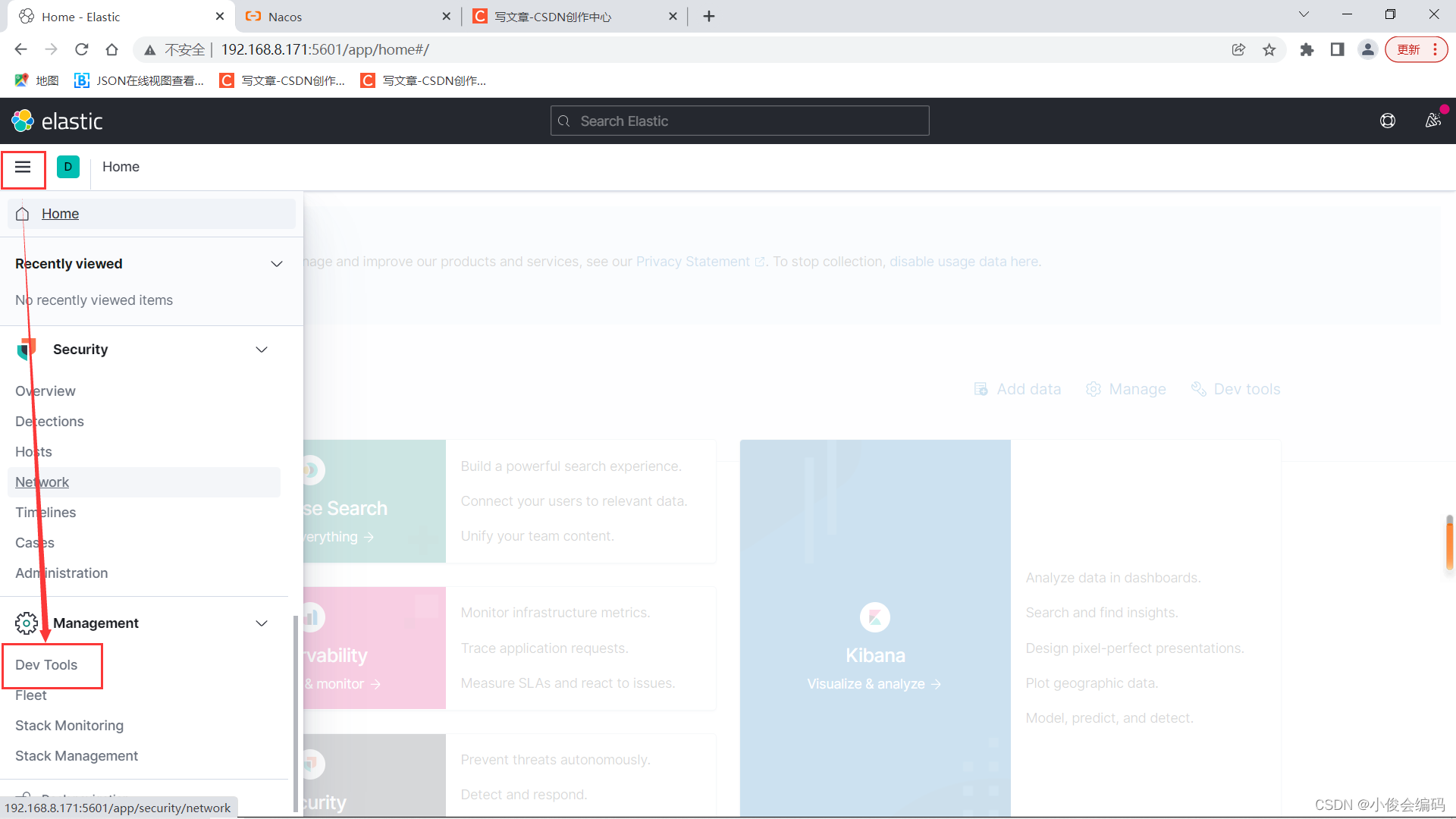
- 就可以看到es+kibana可视化工具,在这里,我们可以写我们要写的东西
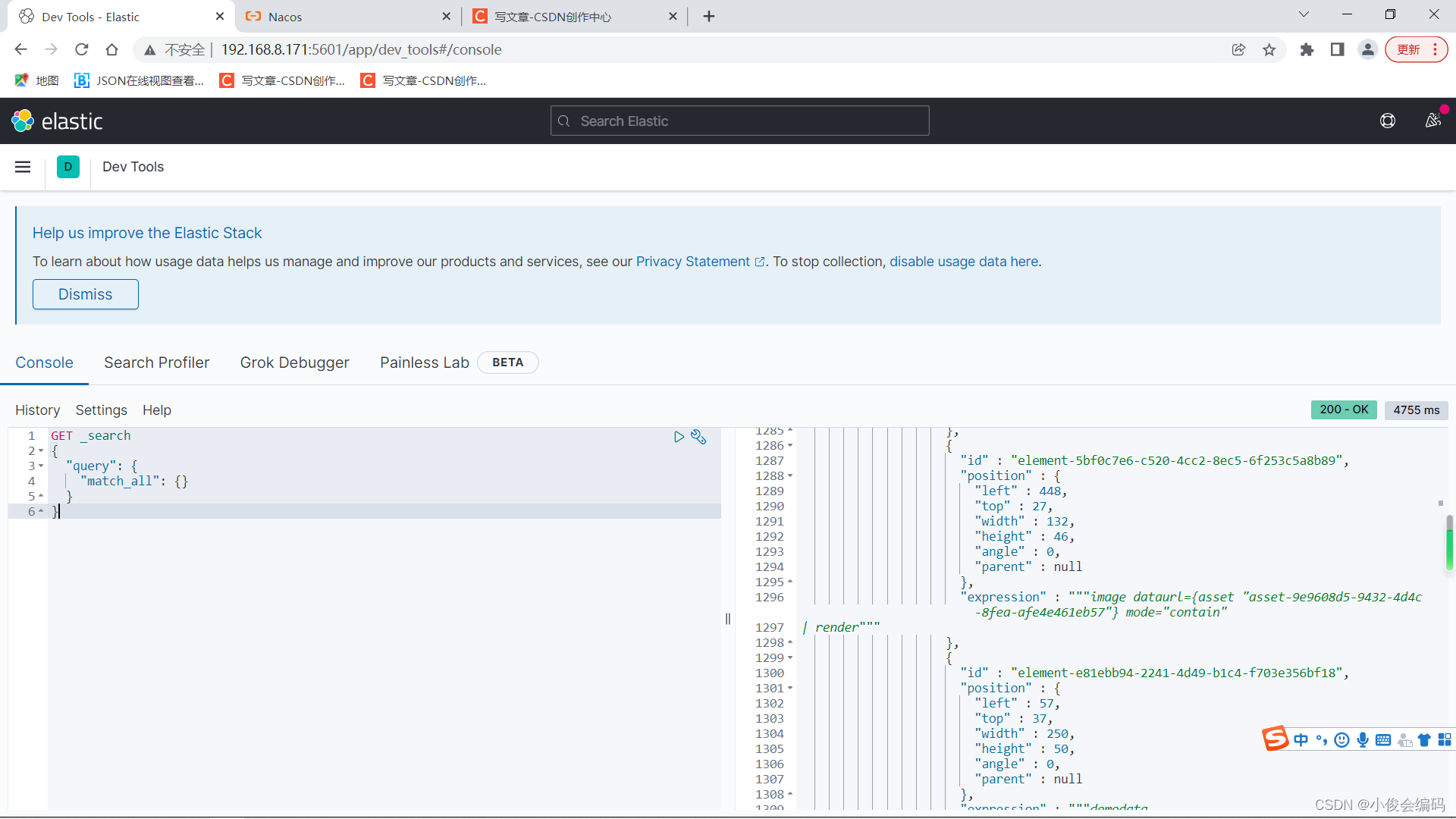
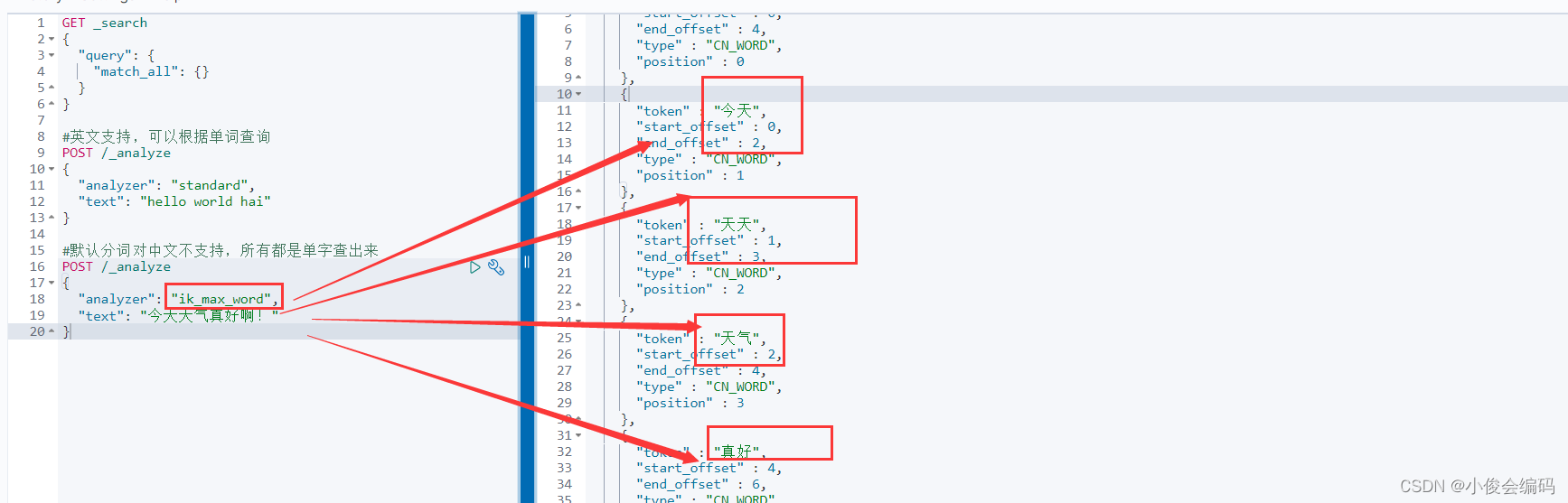
- 随便测试一下(此时我们还没加分词器):
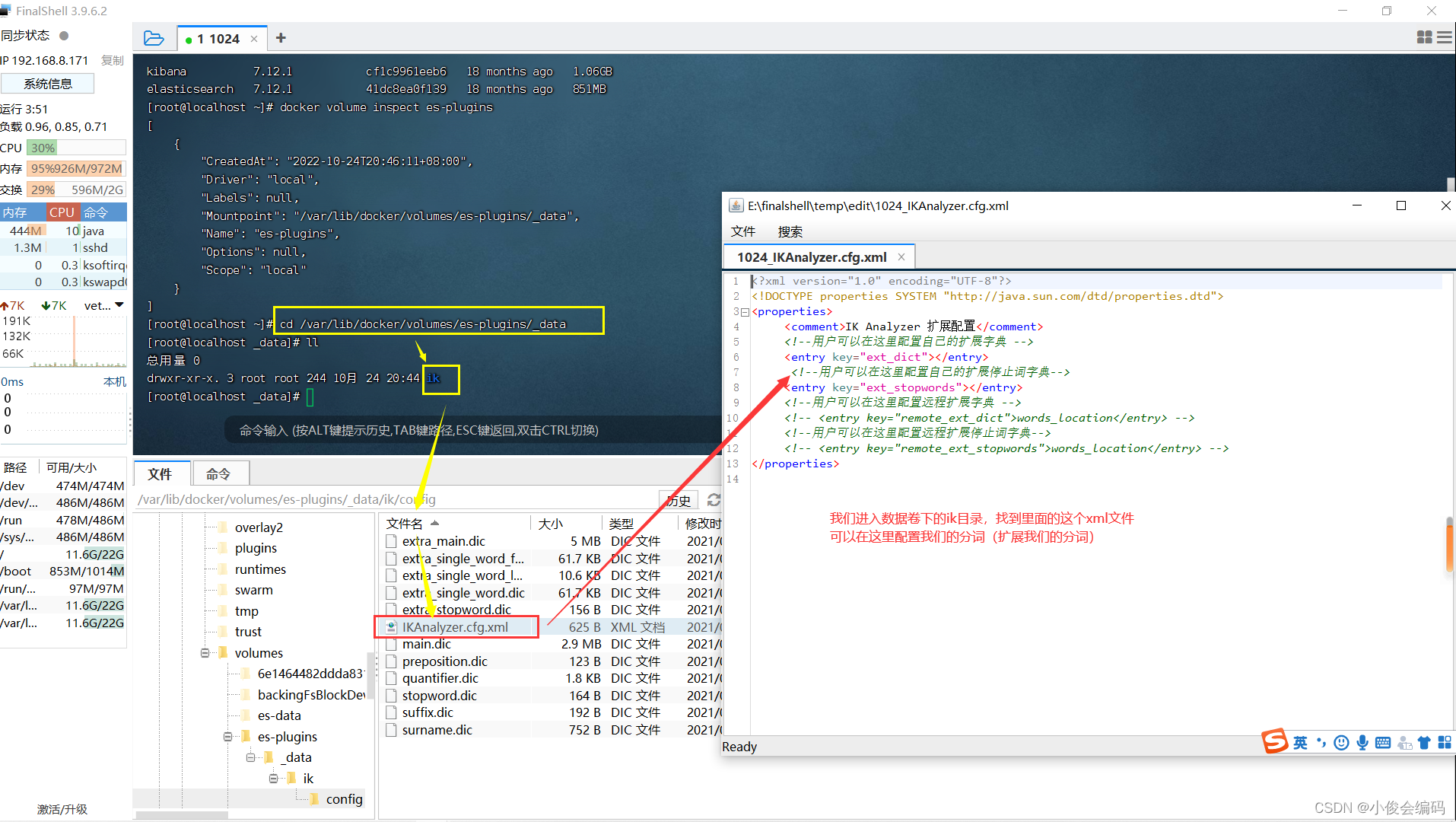
- 查看数据卷的信息:
-
docker volume inspect es-plugins 
-
-
分词器

- 移动ik文件到数据卷的目录下
-
mv ik /var/lib/docker/volumes/es-plugins/_data 
-
- 移动之后需要重启es
-
docker restart es
-
- 再次访问 http://192.168.8.171:9200 直到成功
-
分词成功:
- ik_max_word 细粒度切分
- ik_smart 最少切分

-
finalshell的使用
- 安装好之后,我们来新建一个连接

- 查看一下镜像体验并和crt对比一下

- 可以在这个xml文件下配置分词
- 到这里,我们大概了解了这个软件的使用,现在继续回到crt来操作
- 一样的,进入到这个目录下,修改我们的配置

- 进入xml修改
-
vim IKAnalyzer.cfg.xml
-
-
按i进入编辑模式
-

-
退出保存
-
esc : wq
-

-
-
创建ext.dic文件(因为没有这个文件)然后编辑这个文件,加入新词
-
vim ext.dic -
添加新词
-
-
-
编辑stopword.dic这个文件,编辑那些不用分词的文字
-
vim stopword.dic -

-
-
配置好之后,需要重启es
-
docker restart es
-
- 然后在dev tools里面再来试一下:
- 可以发现,我们新添的分词和不分词也可以起作用了

-



现在我们有几个问题:
- 分词器的作用是什么?
- ik分词器有几种模式
- ik分词器如何扩展词条?如何停用某词?
索引库(表):可以对表进行增删改查的操作
mapping可以对索引库中文档进行约束
type:字段的数据类型:常见的类型有:
- 字符串:text(可以分词的文本),
- keyword(精确值,国家,品牌)
- 数值:long,integer,short,byte,double,float
- 布尔:boolean
- 日期:date
- 对象:object
index:是否创建索引 默认为true
analyzer:使用哪种分词器
properties:当前字段的子字段
xx为索引库
创建索引库:(增删改查操作)
#创建索引库
PUT /xx
{
"mappings": {
"properties": {
"info":{
"type":"text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}

#查看索引库
GET /xx

#删除索引库
DELETE /xx

#修改,索引库跟mapping一旦创建则无法修改,但是可以添加字段
PUT /xx/_mapping
{
"properties":{
"age":{
"type":"integer"
}
}
}

对文档的操作
- put 添加数据
- get 查询数据
- put和post 方式 修改数据
- delete 删除数据
向索引库添加文档
put/xx/_doc/1
{
"info":"未知数程序员傅丹丹",
"email":"[email protected]",
"name":{
"firstName":"傅",
"lastName":"丹丹"
}
}

查看单个文档
GET /xx/_doc/1

查看所有文档
GET /xx/_search

删除文档
DELETE /xx/_doc/1

修改文档,put和post
#修改有二,1、全量修改2、添加文档
有就修改,没有就添加pu
PUT /xx/_doc/1
{
"info":"未知数程序员傅丹丹",
"email":"[email protected]",
"name":{
"firstName":"傅",
"lastName":"丹丹"
}
}

现在我们要使用idea来操作了
- 一个网址
- Elasticsearch Clients | Elastic
-
https://www.elastic.co/guide/en/elasticsearch/client/index.html - 导入hotel数据库,MySQL用的是docker里面的
-
然后根据数据库,创建索引库

-
# hotel PUT /hotel { "mappings": { "properties": { "id":{ "type": "keyword" }, "name":{ "type": "text", "analyzer": "ik_max_word", "copy_to": "all" }, "address":{ "type": "keyword", "index": false }, "price":{ "type": "integer" }, "score":{ "type": "integer" }, "brand":{ "type": "keyword", "copy_to": "all" }, "city":{ "type": "keyword" }, "starName":{ "type": "keyword" }, "business":{ "type": "keyword", "copy_to": "all" }, "location":{ "type": "geo_point" }, "pic":{ "type": "keyword", "index": false }, "all":{ "type": "text", "analyzer": "ik_max_word" } } } } - geo_point: 经纬度
- geo_shape
- 上面这二者啥关系?
然后我们现在开始创建项目
- 用idea自动创建springboot项目
- 引入es的依赖。7.12.1.版本
-
<!-- https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.12.1</version> </dependency> -

-
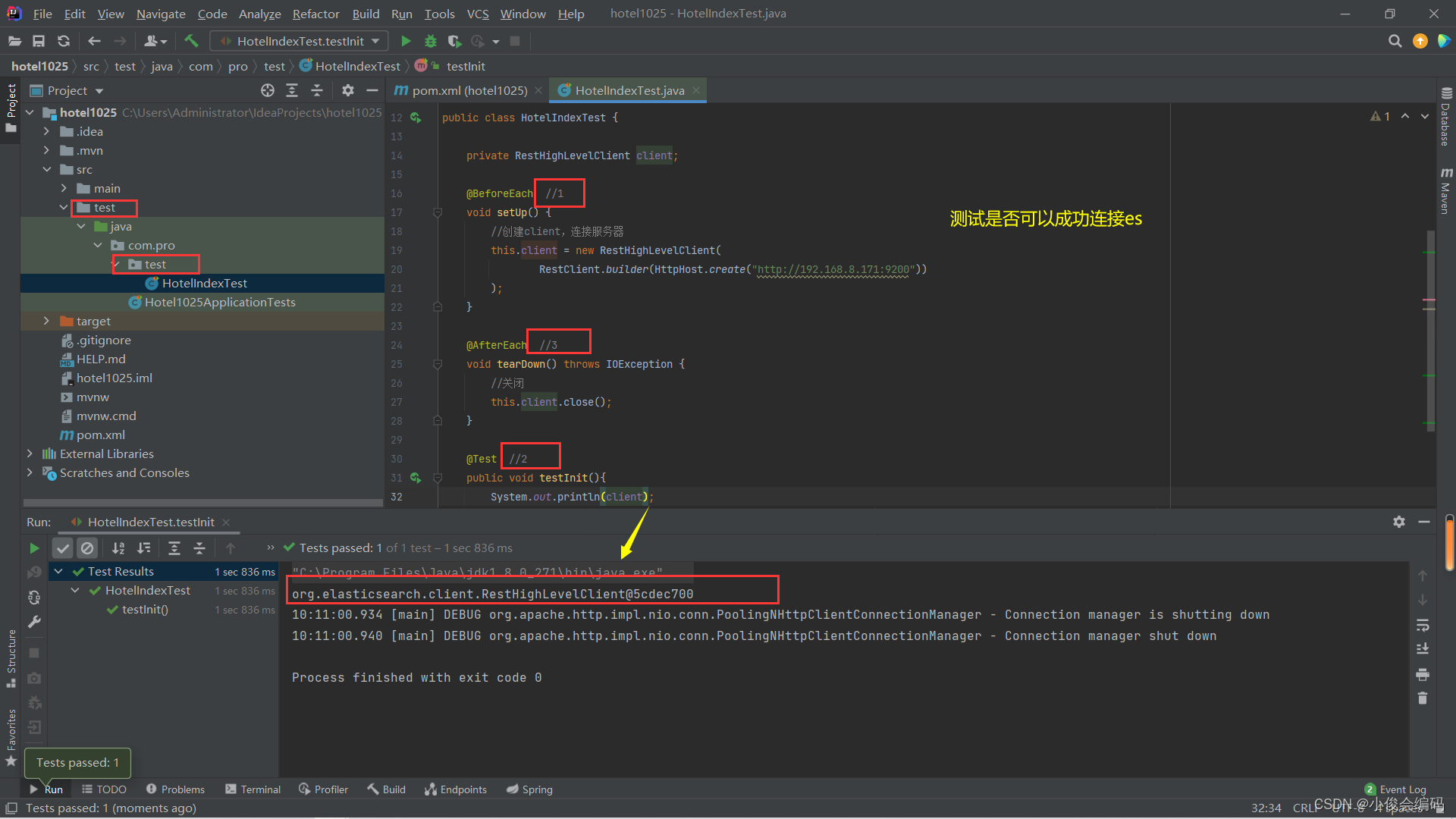
编写HotelIndexTest测试类,测试es是否可以成功连接
-
RestClient -
package com.pro.test; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import java.io.IOException; public class HotelIndexTest { private RestHighLevelClient client; @BeforeEach //1 void setUp() { //创建client,连接服务器 this.client = new RestHighLevelClient( RestClient.builder(HttpHost.create("http://192.168.8.171:9200")) ); } @AfterEach //3 void tearDown() throws IOException { //关闭 this.client.close(); } @Test //2 public void testInit(){ System.out.println(client); } }连接成功
-
-
然后我们想要在idea里面去创建一个和刚刚在dev tools里面一样的hotel索引库
-
那么我们首先应该先删除之前的索引库(delete hotel)
-

-
用idea操作,要清楚几点:
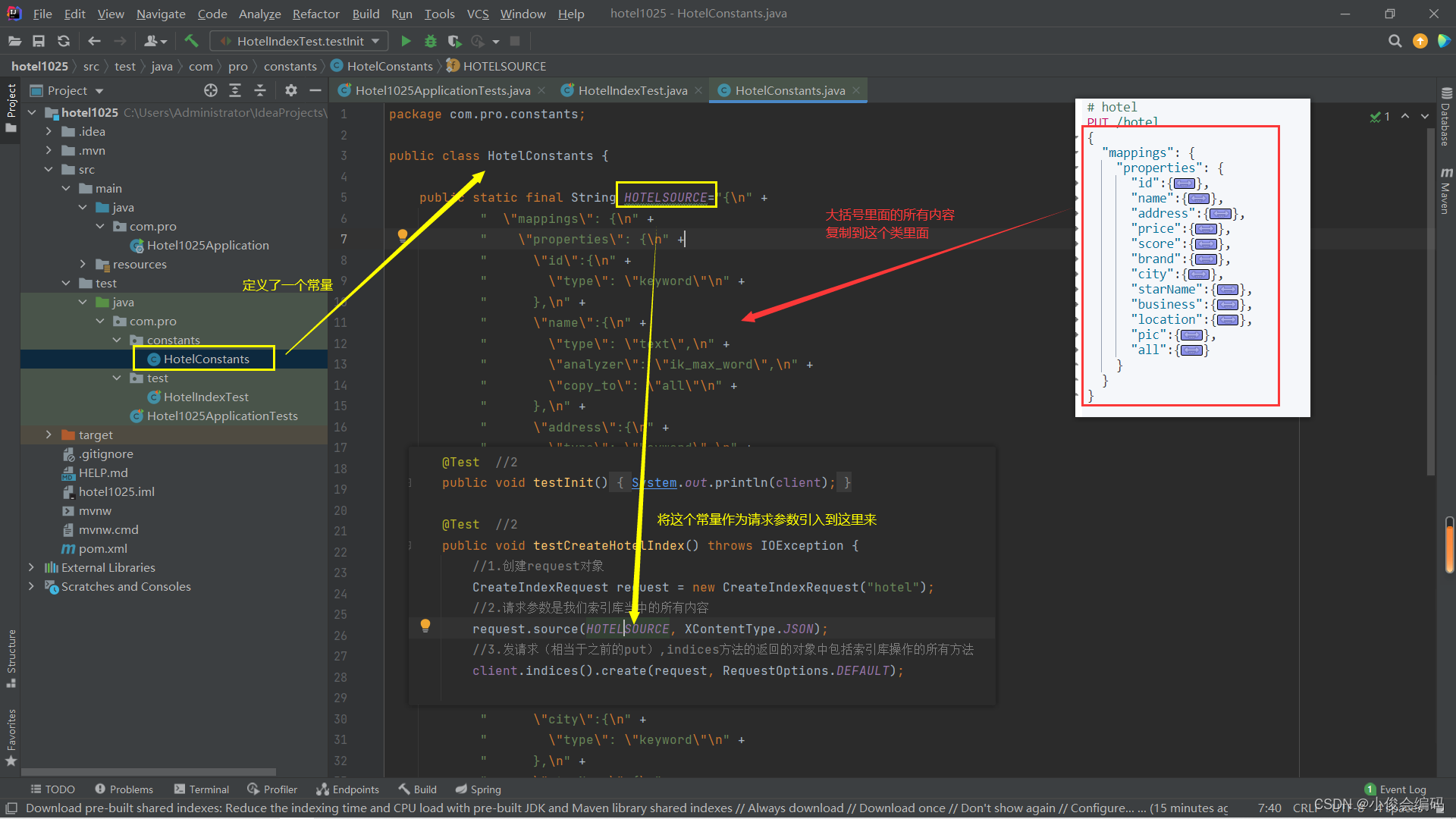
-
source:对应我们在可视化平台大括号里面的所有内容
-
indices()方法的返回的对象中包括索引库操作的所有方法
-

-
-
然后我们执行测试类,运行成功之后,我们去可视化平台get一下,如果有这个索引库,证明我们用idea创建hotel索引库成功了
-
然后我们来用idea把这个hotel索引库删除,然后再查看是否存在,不存在就创建,再查看,目的是熟悉indices()方法下面的操作
-
//创建 @Test //2 public void testCreateHotelIndex() throws IOException { //1.创建request对象 CreateIndexRequest request = new CreateIndexRequest("hotel"); //2.请求参数是我们索引库当中的所有内容 request.source(HOTELSOURCE, XContentType.JSON); //3.发请求(相当于之前的put),indices方法的返回的对象中包括索引库操作的所有方法 client.indices().create(request, RequestOptions.DEFAULT); } //删除 @Test void testDeleteHotelIndex() throws IOException { //1 DeleteIndexRequest request = new DeleteIndexRequest("hotel"); //2. client.indices().delete(request,RequestOptions.DEFAULT); } //获取,判断是否存在 @Test void testExistHotelIndex() throws IOException { GetIndexRequest request = new GetIndexRequest("hotel"); boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println(exists?"索引库存在":"索引库不存在"); } -
那么我们就成功通过RestClient用idea对索引库操作 “创建,删除,查看”,到此为止,相当于我们现在已经有了库indices(表table),那么我们现在就需要去对文档document(记录 row)进行操作了
-
后面的我们写到下一篇文章: