InceptionV4 Inception-ResNet 论文研读及Pytorch代码复现
论文地址: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
文章最大的贡献就是在Inception引入残差结构后,研究了残差结构对Inception的影响,得到的结论是,残差结构的引入
可以加快训练速度,但是在参数量大致相同的Inception v4(纯Inception,无残差连接)模型和Inception-ResNet-v2(有残差连接),其识别效果大致相同,只是训练速度稍有不同。并且文章最后指出,其最新模型InceptionV4模型优于之前的所有模型,仅仅是因为增加了模型大小。
1 相关工作
该部分第二段,稍微总结了Inception的发展创新点,Inception就是最原始的GoogleNet,于2015年提出,之后在GoogleNet中添加BN层,形成了InceptionV2模型;再然后,针对Inception中卷积操作进行改善,例如分解大卷积核(两个33卷积核替换原先的一个55卷进核)、将卷积核沿深度展开(用17和71串行卷积替换原先的77卷积核)、将卷积核沿长度方向展开(使用31和13卷积核替换原先的33卷积核)
2 模型构建
2.1 Inception V4:
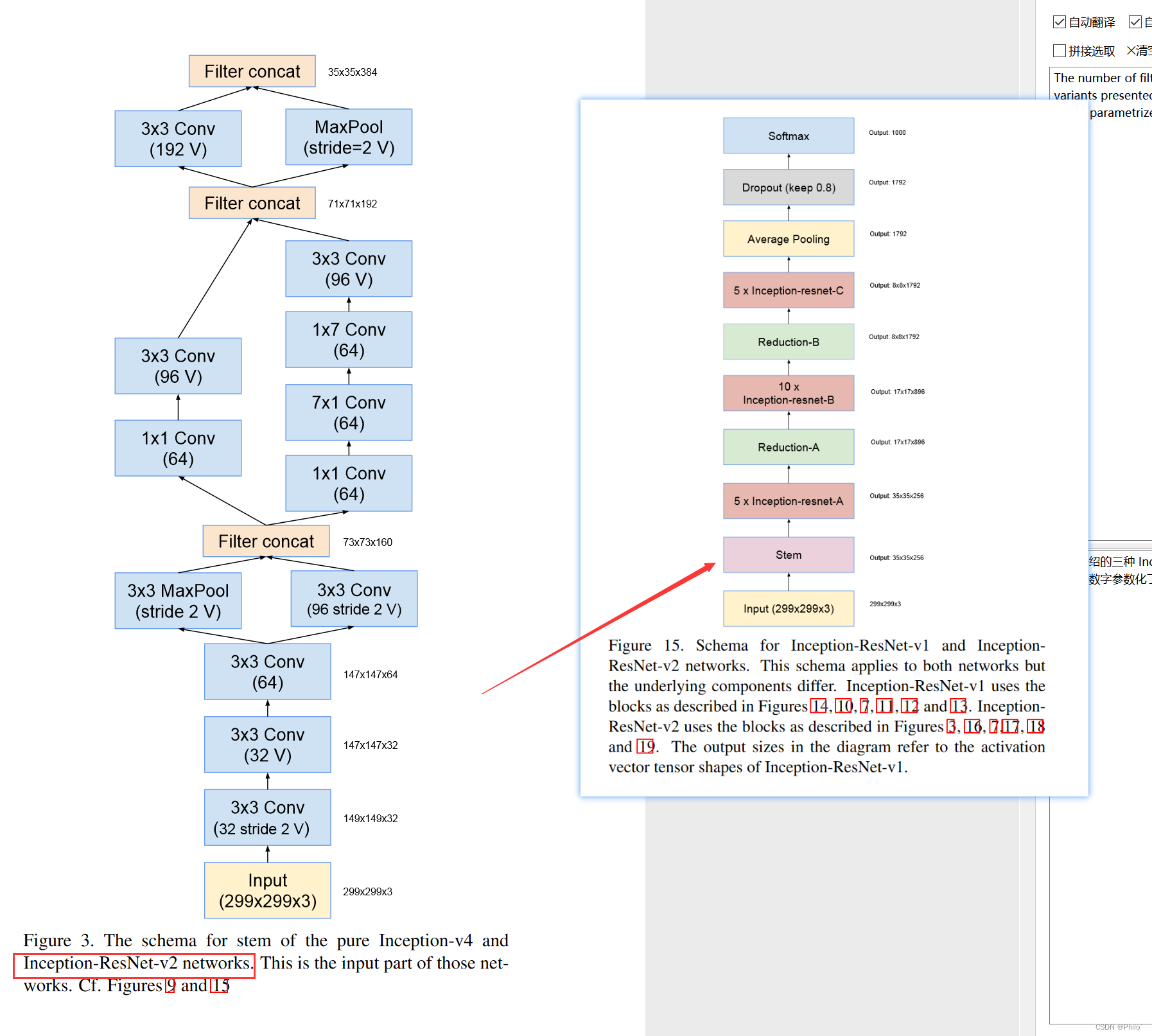
该模型有8个主要结构构成,这也就是论文中到处都是图的原因,需要认真看,以下是将主干图和分解图放在一起,可以看模块输出后大小,用来辅助理解!!
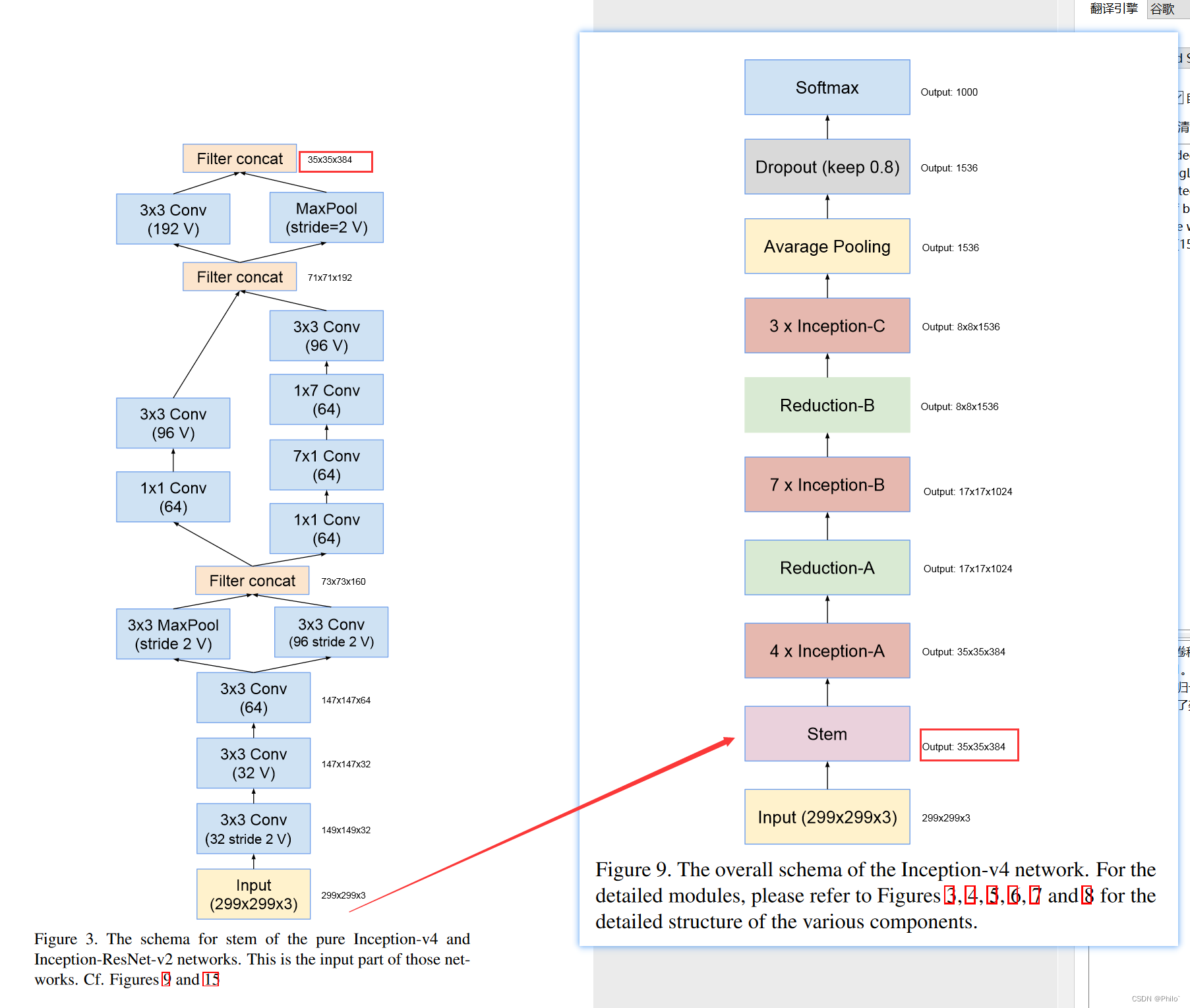
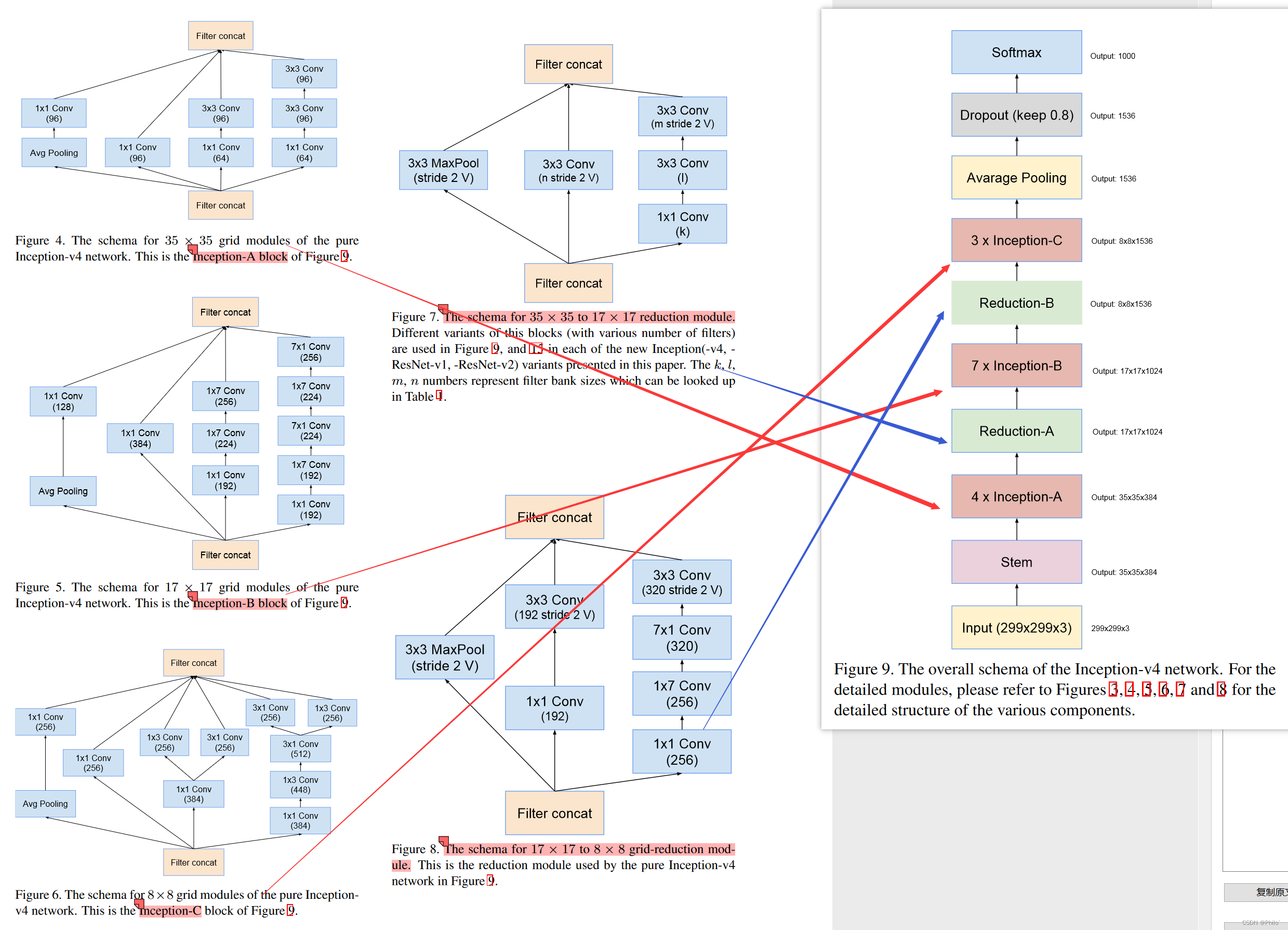
Stem Block:
# 定义一个卷积模块(带BatchNormalization及ReLU激活函数)
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x)
class Stem(nn.Module):
def __init__(self, in_channels, out_channels):
super(Stem, self).__init__()
#conv3*3(32 stride2 valid)
self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)
#conv3*3(32 valid)
self.conv2 = BasicConv2d(32, 32, kernel_size=3)
#conv3*3(64)
self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
#maxpool3*3(stride2 valid) & conv3*3(96 stride2 valid)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv4 = BasicConv2d(64, 96, kernel_size=3, stride=2)
#conv1*1(64) --> conv3*3(96 valid)
self.conv5_1_1 = BasicConv2d(160, 64, kernel_size=1)
self.conv5_1_2 = BasicConv2d(64, 96, kernel_size=3)
#conv1*1(64) --> conv7*1(64) --> conv1*7(64) --> conv3*3(96 valid)
self.conv5_2_1 = BasicConv2d(160, 64, kernel_size=1)
self.conv5_2_2 = BasicConv2d(64, 64, kernel_size=(7,1), padding=(3,0))
self.conv5_2_3 = BasicConv2d(64, 64, kernel_size=(1,7), padding=(0,3))
self.conv5_2_4 = BasicConv2d(64, 96, kernel_size=3)
#conv3*3(192 valid)
self.conv6 = BasicConv2d(192, 192, kernel_size=3, stride=2)
#maxpool3*3(stride2 valid)
self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2)
def forward(self, x):
y1_1 = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))
y1_2 = self.conv4(self.conv3(self.conv2(self.conv1(x))))
y1 = torch.cat([y1_1, y1_2], 1)
y2_1 = self.conv5_1_2(self.conv5_1_1(y1))
y2_2 = self.conv5_2_4(self.conv5_2_3(self.conv5_2_2(self.conv5_2_1(y1))))
y2 = torch.cat([y2_1, y2_2], 1)
y3_1 = self.conv6(y2)
y3_2 = self.maxpool6(y2)
y3 = torch.cat([y3_1, y3_2], 1)
return y3
Inception-A Block
class InceptionA(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionA, self).__init__()
#branch1: avgpool --> conv1*1(96)
self.b1_1 = nn.AvgPool2d(kernel_size=3, padding=1, stride=1)
self.b1_2 = BasicConv2d(in_channels, 96, kernel_size=1)
#branch2: conv1*1(96)
self.b2 = BasicConv2d(in_channels, 96, kernel_size=1)
#branch3: conv1*1(64) --> conv3*3(96)
self.b3_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.b3_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
#branch4: conv1*1(64) --> conv3*3(96) --> conv3*3(96)
self.b4_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.b4_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.b4_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
def forward(self, x):
y1 = self.b1_2(self.b1_1(x))
y2 = self.b2(x)
y3 = self.b3_2(self.b3_1(x))
y4 = self.b4_3(self.b4_2(self.b4_1(x)))
outputsA = [y1, y2, y3, y4]
return torch.cat(outputsA, 1)
Inception-B Block
class InceptionB(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionB, self).__init__()
#branch1: avgpool --> conv1*1(128)
self.b1_1 = nn.AvgPool2d(kernel_size=3, padding=1, stride=1)
self.b1_2 = BasicConv2d(in_channels, 128, kernel_size=1)
#branch2: conv1*1(384)
self.b2 = BasicConv2d(in_channels, 384, kernel_size=1)
#branch3: conv1*1(192) --> conv1*7(224) --> conv1*7(256)
self.b3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.b3_2 = BasicConv2d(192, 224, kernel_size=(7,1), padding=(3,0))
self.b3_3 = BasicConv2d(224, 256, kernel_size=(1,7), padding=(0,3))
#branch4: conv1*1(192) --> conv1*7(192) --> conv7*1(224) --> conv1*7(224) --> conv7*1(256)
self.b4_1 = BasicConv2d(in_channels, 192, kernel_size=1, stride=1)
self.b4_2 = BasicConv2d(192, 192, kernel_size=(1,7), padding=(0,3))
self.b4_3 = BasicConv2d(192, 224, kernel_size=(7,1), padding=(3,0))
self.b4_4 = BasicConv2d(224, 224, kernel_size=(1,7), padding=(0,3))
self.b4_5 = BasicConv2d(224, 256, kernel_size=(7,1), padding=(3,0))
def forward(self, x):
y1 = self.b1_2(self.b1_1(x))
y2 = self.b2(x)
y3 = self.b3_3(self.b3_2(self.b3_1(x)))
y4 = self.b4_5(self.b4_4(self.b4_3(self.b4_2(self.b4_1(x)))))
outputsB = [y1, y2, y3, y4]
return torch.cat(outputsB, 1)
Inception-C Block
class InceptionC(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionC, self).__init__()
#branch1: avgpool --> conv1*1(256)
self.b1_1 = nn.AvgPool2d(kernel_size=3, padding=1, stride=1)
self.b1_2 = BasicConv2d(in_channels, 256, kernel_size=1)
#branch2: conv1*1(256)
self.b2 = BasicConv2d(in_channels, 256, kernel_size=1)
#branch3: conv1*1(384) --> conv1*3(256) & conv3*1(256)
self.b3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.b3_2_1 = BasicConv2d(384, 256, kernel_size=(1,3), padding=(0,1))
self.b3_2_2 = BasicConv2d(384, 256, kernel_size=(3,1), padding=(1,0))
#branch4: conv1*1(384) --> conv1*3(448) --> conv3*1(512) --> conv3*1(256) & conv7*1(256)
self.b4_1 = BasicConv2d(in_channels, 384, kernel_size=1, stride=1)
self.b4_2 = BasicConv2d(384, 448, kernel_size=(1,3), padding=(0,1))
self.b4_3 = BasicConv2d(448, 512, kernel_size=(3,1), padding=(1,0))
self.b4_4_1 = BasicConv2d(512, 256, kernel_size=(3,1), padding=(1,0))
self.b4_4_2 = BasicConv2d(512, 256, kernel_size=(1,3), padding=(0,1))
def forward(self, x):
y1 = self.b1_2(self.b1_1(x))
y2 = self.b2(x)
y3_1 = self.b3_2_1(self.b3_1(x))
y3_2 = self.b3_2_2(self.b3_1(x))
y4_1 = self.b4_4_1(self.b4_3(self.b4_2(self.b4_1(x))))
y4_2 = self.b4_4_2(self.b4_3(self.b4_2(self.b4_1(x))))
outputsC = [y1, y2, y3_1, y3_2, y4_1, y4_2]
return torch.cat(outputsC, 1)
ReductionA Block
class ReductionA(nn.Module):
def __init__(self, in_channels, out_channels, k, l, m, n):
super(ReductionA, self).__init__()
#branch1: maxpool3*3(stride2 valid)
self.b1 = nn.MaxPool2d(kernel_size=3, stride=2)
#branch2: conv3*3(n stride2 valid)
self.b2 = BasicConv2d(in_channels, n, kernel_size=3, stride=2)
#branch3: conv1*1(k) --> conv3*3(l) --> conv3*3(m stride2 valid)
self.b3_1 = BasicConv2d(in_channels, k, kernel_size=1)
self.b3_2 = BasicConv2d(k, l, kernel_size=3, padding=1)
self.b3_3 = BasicConv2d(l, m, kernel_size=3, stride=2)
def forward(self, x):
y1 = self.b1(x)
y2 = self.b2(x)
y3 = self.b3_3(self.b3_2(self.b3_1(x)))
outputsRedA = [y1, y2, y3]
return torch.cat(outputsRedA, 1)
ReductionB Block
class ReductionB(nn.Module):
def __init__(self, in_channels, out_channels):
super(ReductionB, self).__init__()
#branch1: maxpool3*3(stride2 valid)
self.b1 = nn.MaxPool2d(kernel_size=3, stride=2)
#branch2: conv1*1(192) --> conv3*3(192 stride2 valid)
self.b2_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.b2_2 = BasicConv2d(192, 192, kernel_size=3, stride=2)
#branch3: conv1*1(256) --> conv1*7(256) --> conv7*1(320) --> conv3*3(320 stride2 valid)
self.b3_1 = BasicConv2d(in_channels, 256, kernel_size=1)
self.b3_2 = BasicConv2d(256, 256, kernel_size=(1,7), padding=(0,3))
self.b3_3 = BasicConv2d(256, 320, kernel_size=(7,1), padding=(3,0))
self.b3_4 = BasicConv2d(320, 320, kernel_size=3, stride=2)
def forward(self, x):
y1 = self.b1(x)
y2 = self.b2_2(self.b2_1((x)))
y3 = self.b3_4(self.b3_3(self.b3_2(self.b3_1(x))))
outputsRedB = [y1, y2, y3]
return torch.cat(outputsRedB, 1)
Inception V4网络
class Googlenetv4(nn.Module): # 这里默认了输入通道是3,输出是1000,有需要的话,可以自己改一下
def __init__(self):
super(Googlenetv4, self).__init__()
self.stem = Stem(3, 384)
self.icpA = InceptionA(384, 384)
self.redA = ReductionA(384, 1024, 192, 224, 256, 384)
self.icpB = InceptionB(1024, 1024)
self.redB = ReductionB(1024, 1536)
self.icpC = InceptionC(1536, 1536)
self.avgpool = nn.AvgPool2d(kernel_size=8)
self.dropout = nn.Dropout(p=0.8)
self.linear = nn.Linear(1536, 1000)
def forward(self, x):
#Stem Module
out = self.stem(x)
#InceptionA Module * 4
out = self.icpA(self.icpA(self.icpA(self.icpA(out))))
#ReductionA Module
out = self.redA(out)
#InceptionB Module * 7
out = self.icpB(self.icpB(self.icpB(self.icpB(self.icpB(self.icpB(self.icpB(out)))))))
#ReductionB Module
out = self.redB(out)
#InceptionC Module * 3
out = self.icpC(self.icpC(self.icpC(out)))
#Average Pooling
out = self.avgpool(out)
out = out.view(out.size(0), -1)
#Dropout
out = self.dropout(out)
#Linear(Softmax)
out = self.linear(out)
return out
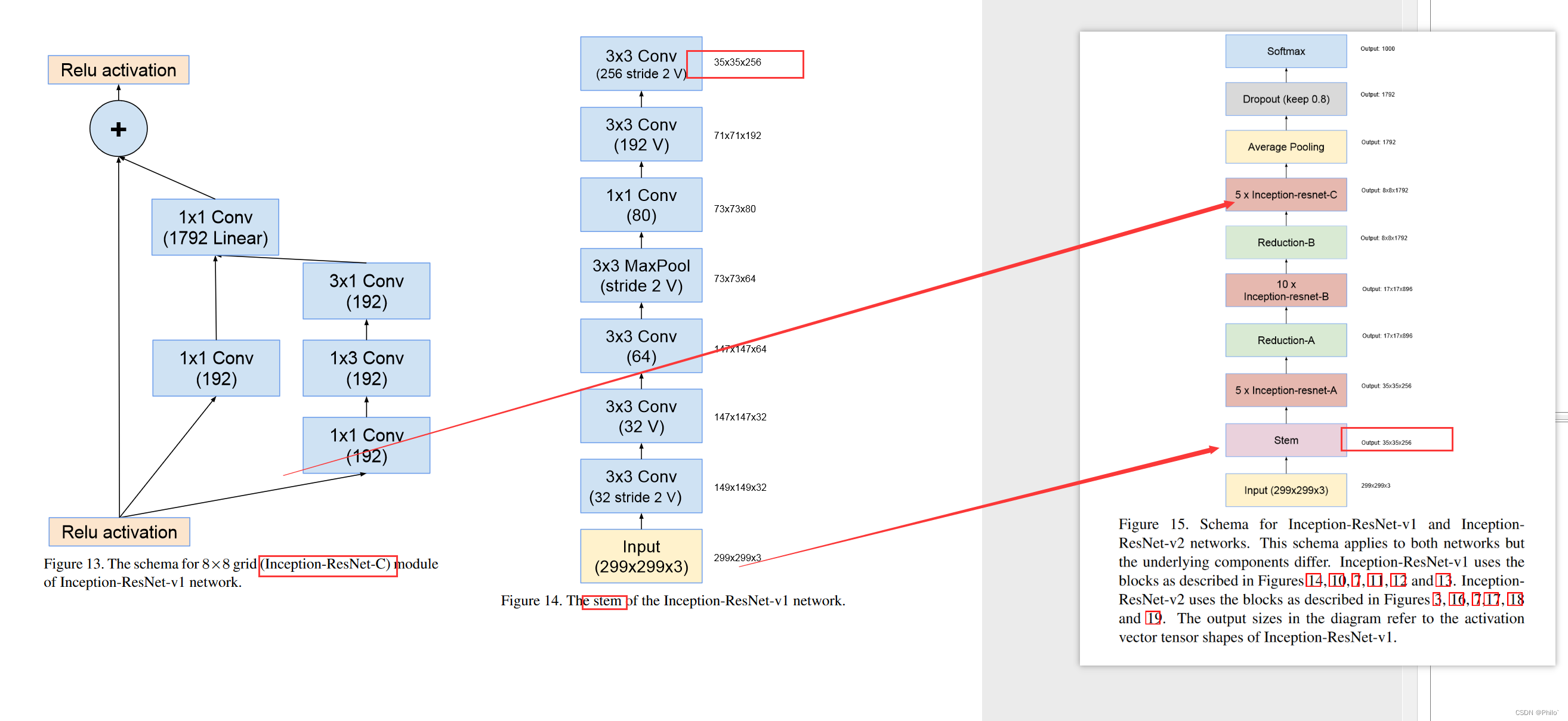
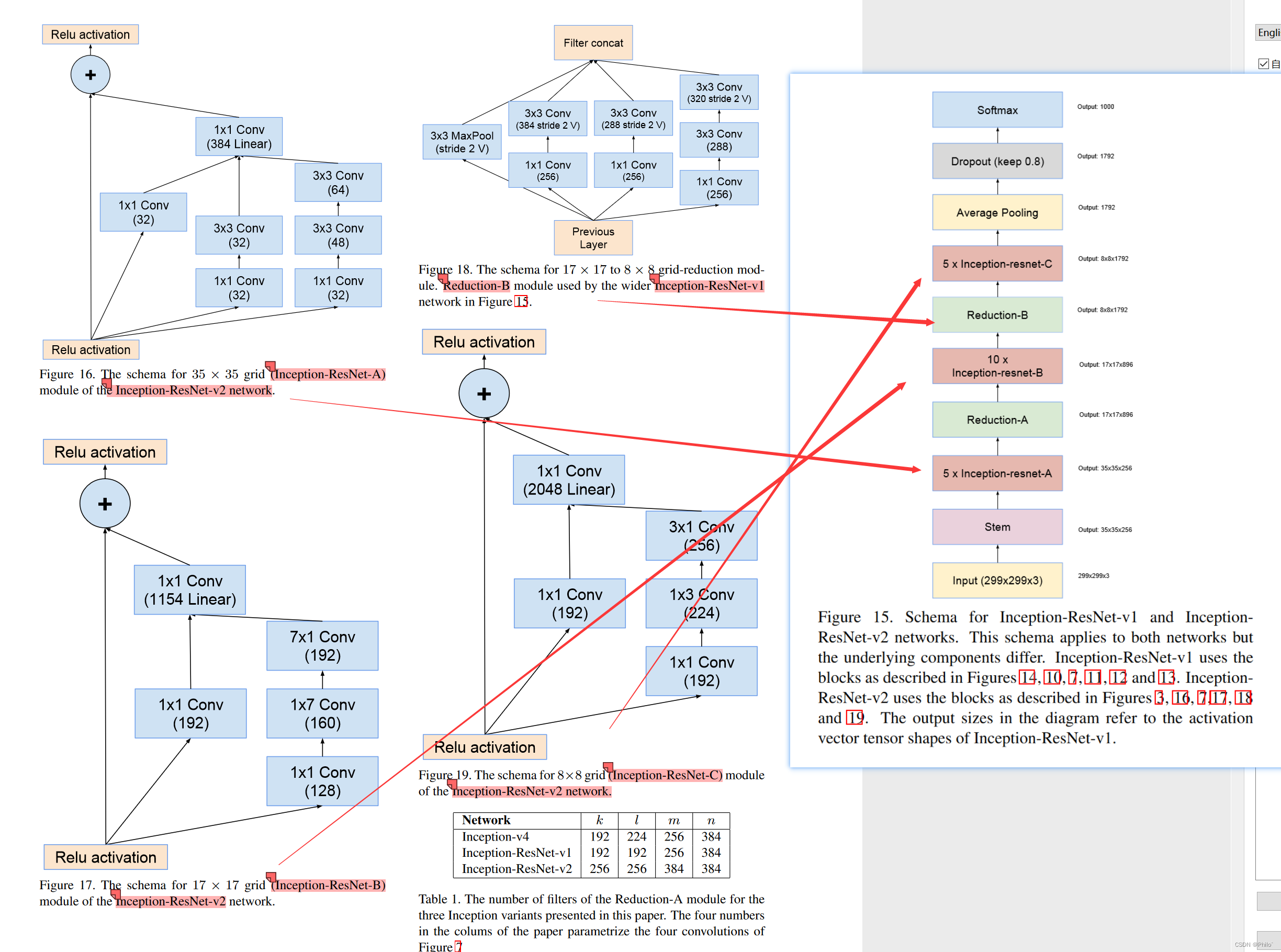
2.2 Inception-ResNet:
Inception-ResNet网络一共有两个版本,v1对标Inception V3,v2对标Inception V4,但是主体结构不变,主要是底层模块过滤器使用的不同,以下给出主体结构和相关代码
Inception-ResNet v1网络结构
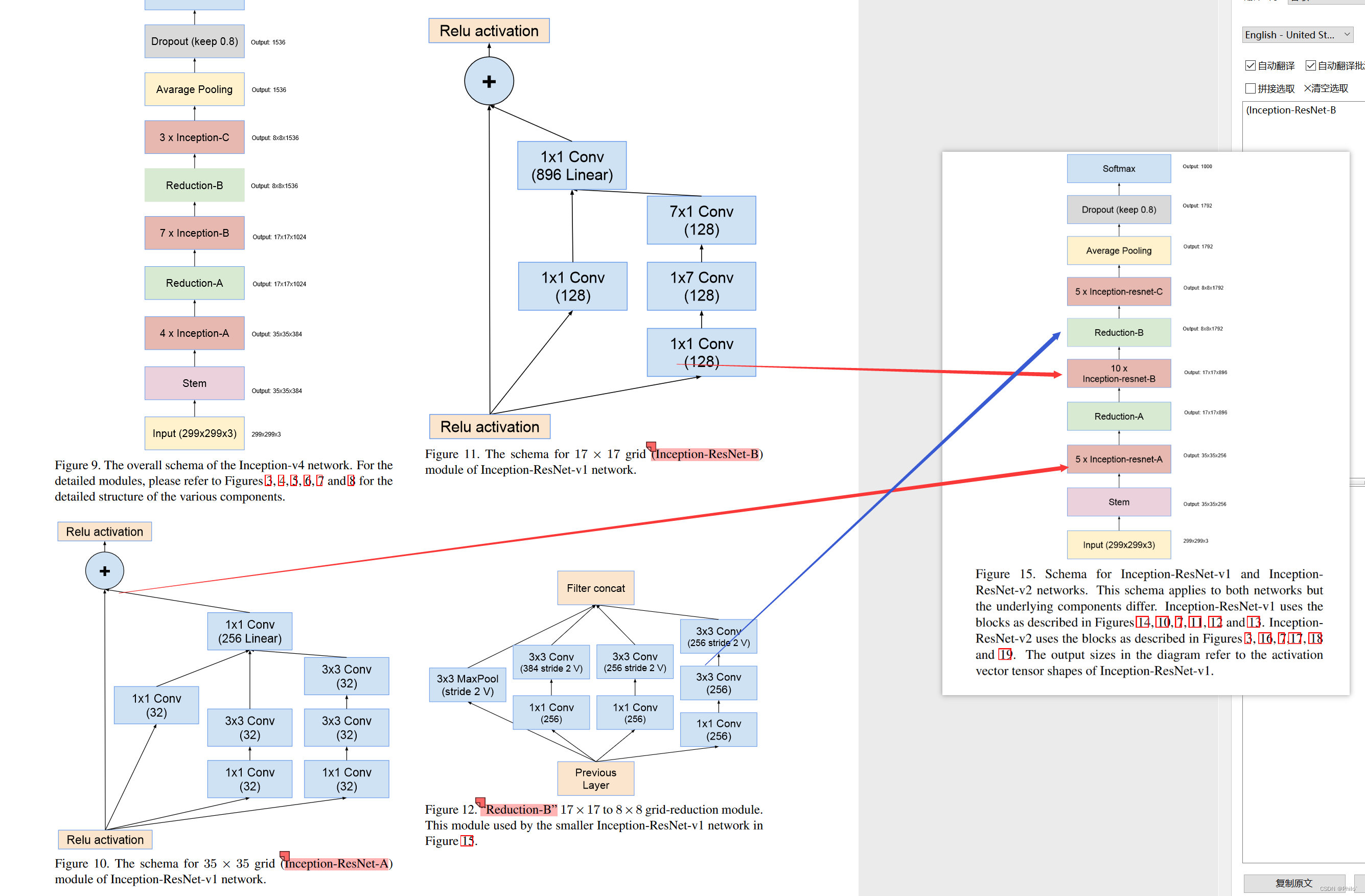

Inception-ResNet v2网络结构
from __future__ import print_function, division, absolute_import
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
import os
import sys
__all__ = ['InceptionResNetV2', 'inceptionresnetv2']
pretrained_settings = {
'inceptionresnetv2': {
'imagenet': {
'url': 'http://data.lip6.fr/cadene/pretrainedmodels/inceptionresnetv2-520b38e4.pth',
'input_space': 'RGB',
'input_size': [3, 299, 299],
'input_range': [0, 1],
'mean': [0.5, 0.5, 0.5],
'std': [0.5, 0.5, 0.5],
'num_classes': 1000
},
'imagenet+background': {
'url': 'http://data.lip6.fr/cadene/pretrainedmodels/inceptionresnetv2-520b38e4.pth',
'input_space': 'RGB',
'input_size': [3, 299, 299],
'input_range': [0, 1],
'mean': [0.5, 0.5, 0.5],
'std': [0.5, 0.5, 0.5],
'num_classes': 1001
}
}
}
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, bias=False) # verify bias false
self.bn = nn.BatchNorm2d(out_planes,
eps=0.001, # value found in tensorflow
momentum=0.1, # default pytorch value
affine=True)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class Mixed_5b(nn.Module):
def __init__(self):
super(Mixed_5b, self).__init__()
self.branch0 = BasicConv2d(192, 96, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(192, 48, kernel_size=1, stride=1),
BasicConv2d(48, 64, kernel_size=5, stride=1, padding=2)
)
self.branch2 = nn.Sequential(
BasicConv2d(192, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1),
BasicConv2d(96, 96, kernel_size=3, stride=1, padding=1)
)
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(192, 64, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
class Block35(nn.Module):
def __init__(self, scale=1.0):
super(Block35, self).__init__()
self.scale = scale
self.branch0 = BasicConv2d(320, 32, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(320, 32, kernel_size=1, stride=1),
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=1)
)
self.branch2 = nn.Sequential(
BasicConv2d(320, 32, kernel_size=1, stride=1),
BasicConv2d(32, 48, kernel_size=3, stride=1, padding=1),
BasicConv2d(48, 64, kernel_size=3, stride=1, padding=1)
)
self.conv2d = nn.Conv2d(128, 320, kernel_size=1, stride=1)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
out = self.conv2d(out)
out = out * self.scale + x
out = self.relu(out)
return out
class Mixed_6a(nn.Module):
def __init__(self):
super(Mixed_6a, self).__init__()
self.branch0 = BasicConv2d(320, 384, kernel_size=3, stride=2)
self.branch1 = nn.Sequential(
BasicConv2d(320, 256, kernel_size=1, stride=1),
BasicConv2d(256, 256, kernel_size=3, stride=1, padding=1),
BasicConv2d(256, 384, kernel_size=3, stride=2)
)
self.branch2 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
return out
class Block17(nn.Module):
def __init__(self, scale=1.0):
super(Block17, self).__init__()
self.scale = scale
self.branch0 = BasicConv2d(1088, 192, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(1088, 128, kernel_size=1, stride=1),
BasicConv2d(128, 160, kernel_size=(1,7), stride=1, padding=(0,3)),
BasicConv2d(160, 192, kernel_size=(7,1), stride=1, padding=(3,0))
)
self.conv2d = nn.Conv2d(384, 1088, kernel_size=1, stride=1)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
out = self.conv2d(out)
out = out * self.scale + x
out = self.relu(out)
return out
class Mixed_7a(nn.Module):
def __init__(self):
super(Mixed_7a, self).__init__()
self.branch0 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 384, kernel_size=3, stride=2)
)
self.branch1 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 288, kernel_size=3, stride=2)
)
self.branch2 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 288, kernel_size=3, stride=1, padding=1),
BasicConv2d(288, 320, kernel_size=3, stride=2)
)
self.branch3 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
class Block8(nn.Module):
def __init__(self, scale=1.0, noReLU=False):
super(Block8, self).__init__()
self.scale = scale
self.noReLU = noReLU
self.branch0 = BasicConv2d(2080, 192, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(2080, 192, kernel_size=1, stride=1),
BasicConv2d(192, 224, kernel_size=(1,3), stride=1, padding=(0,1)),
BasicConv2d(224, 256, kernel_size=(3,1), stride=1, padding=(1,0))
)
self.conv2d = nn.Conv2d(448, 2080, kernel_size=1, stride=1)
if not self.noReLU:
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
out = self.conv2d(out)
out = out * self.scale + x
if not self.noReLU:
out = self.relu(out)
return out
class InceptionResNetV2(nn.Module):
def __init__(self, num_classes=1001):
super(InceptionResNetV2, self).__init__()
# Special attributs
self.input_space = None
self.input_size = (299, 299, 3)
self.mean = None
self.std = None
# Modules
self.conv2d_1a = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.conv2d_2a = BasicConv2d(32, 32, kernel_size=3, stride=1)
self.conv2d_2b = BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.maxpool_3a = nn.MaxPool2d(3, stride=2)
self.conv2d_3b = BasicConv2d(64, 80, kernel_size=1, stride=1)
self.conv2d_4a = BasicConv2d(80, 192, kernel_size=3, stride=1)
self.maxpool_5a = nn.MaxPool2d(3, stride=2)
self.mixed_5b = Mixed_5b()
self.repeat = nn.Sequential(
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17)
)
self.mixed_6a = Mixed_6a()
self.repeat_1 = nn.Sequential(
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10)
)
self.mixed_7a = Mixed_7a()
self.repeat_2 = nn.Sequential(
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20)
)
self.block8 = Block8(noReLU=True)
self.conv2d_7b = BasicConv2d(2080, 1536, kernel_size=1, stride=1)
self.avgpool_1a = nn.AvgPool2d(8, count_include_pad=False)
self.last_linear = nn.Linear(1536, num_classes)
def features(self, input):
x = self.conv2d_1a(input)
x = self.conv2d_2a(x)
x = self.conv2d_2b(x)
x = self.maxpool_3a(x)
x = self.conv2d_3b(x)
x = self.conv2d_4a(x)
x = self.maxpool_5a(x)
x = self.mixed_5b(x)
x = self.repeat(x)
x = self.mixed_6a(x)
x = self.repeat_1(x)
x = self.mixed_7a(x)
x = self.repeat_2(x)
x = self.block8(x)
x = self.conv2d_7b(x)
return x
def logits(self, features):
x = self.avgpool_1a(features)
x = x.view(x.size(0), -1)
x = self.last_linear(x)
return x
def forward(self, input):
x = self.features(input)
x = self.logits(x)
return x
def inceptionresnetv2(num_classes=1000, pretrained='imagenet'):
r"""InceptionResNetV2 model architecture from the
`"InceptionV4, Inception-ResNet..." <https://arxiv.org/abs/1602.07261>`_ paper.
"""
if pretrained:
settings = pretrained_settings['inceptionresnetv2'][pretrained]
assert num_classes == settings['num_classes'], \
"num_classes should be {}, but is {}".format(settings['num_classes'], num_classes)
# both 'imagenet'&'imagenet+background' are loaded from same parameters
model = InceptionResNetV2(num_classes=1001)
model.load_state_dict(model_zoo.load_url(settings['url']))
if pretrained == 'imagenet':
new_last_linear = nn.Linear(1536, 1000)
new_last_linear.weight.data = model.last_linear.weight.data[1:]
new_last_linear.bias.data = model.last_linear.bias.data[1:]
model.last_linear = new_last_linear
model.input_space = settings['input_space']
model.input_size = settings['input_size']
model.input_range = settings['input_range']
model.mean = settings['mean']
model.std = settings['std']
else:
model = InceptionResNetV2(num_classes=num_classes)
return model
#TEST
#Run this code with:
#cd $HOME/pretrained-models.pytorch
#python -m pretrainedmodels.inceptionresnetv2
if __name__ == '__main__':
assert inceptionresnetv2(num_classes=10, pretrained=None)
print('success')
assert inceptionresnetv2(num_classes=1000, pretrained='imagenet')
print('success')
assert inceptionresnetv2(num_classes=1001, pretrained='imagenet+background')
print('success')
# fail
assert inceptionresnetv2(num_classes=1001, pretrained='imagenet')
Inception ResNet V2 代码的通道数和类别数没有修改,有需要的可以自行修改,该论文出处为:
pretrained-models.pytorch
3 实验结果
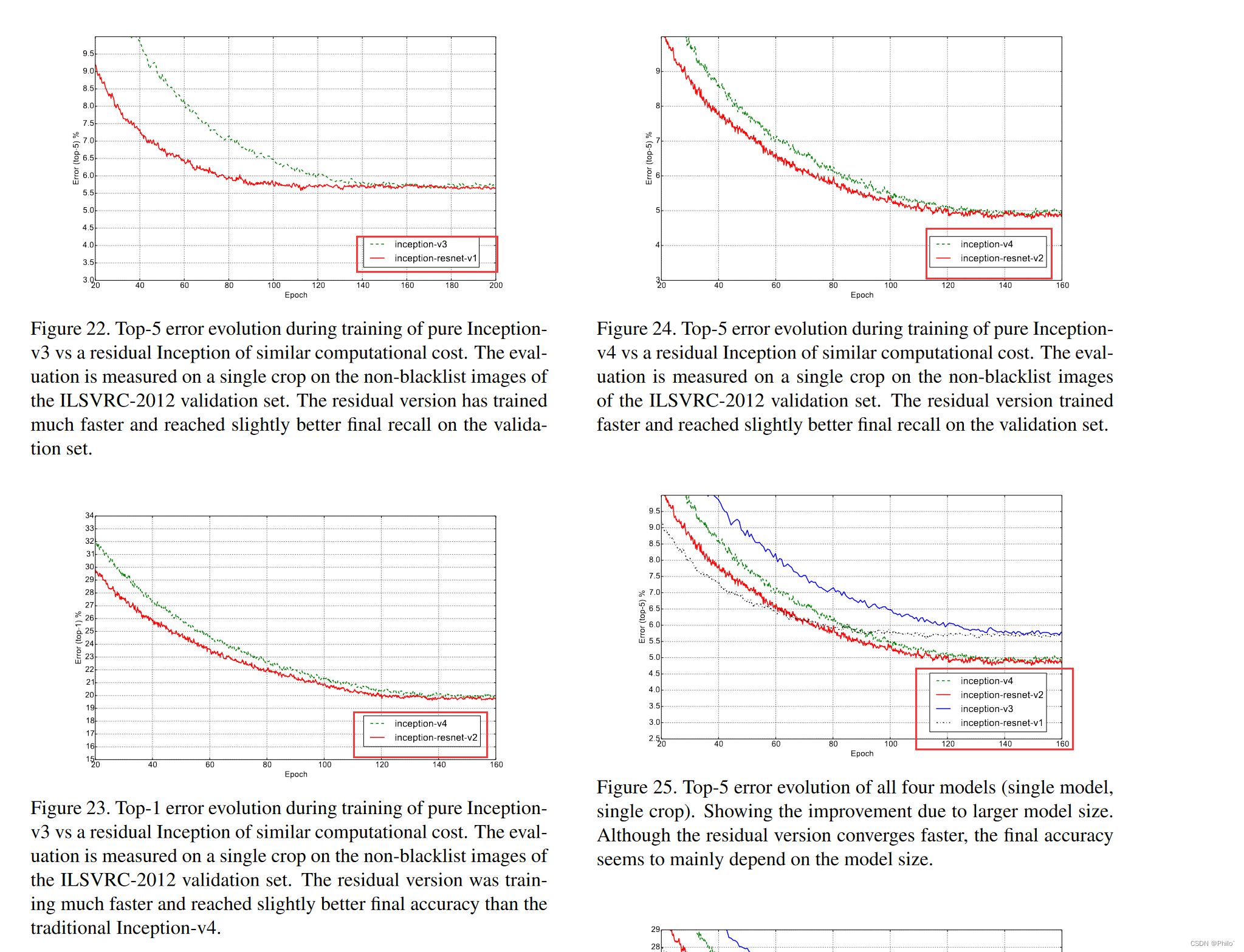
网络训练速度加快!!