线性模型(Linear Model) 是机器学习中应用最广泛的模型,指通过样本特征的线性组合来进行预测的模型。
给定一个d维样本 [ z 1 , ⋅ ⋅ , z a ] T [z_1,··,z_a]^T [z1,⋅⋅,za]T,其线性组合函数为
f ( x , w ) = w 1 x 1 + w 2 x 2 + ⋯ + w d x d + b = w T x + b , \begin{aligned}f(\mathbf{x},\mathbf{w})&=w_1x_1+w_2x_2+\cdots+w_d x_d+b\\ &=\mathbf{w}^T\mathbf{x}+b,\end{aligned} f(x,w)=w1x1+w2x2+⋯+wdxd+b=wTx+b,
其中 w = [ w 1 , ⋯ , w d ] T \mathbf{w}=[w_{1},\cdots,w_{d}]^{\mathrm{T}} w=[w1,⋯,wd]T为d维的权重向量,b为偏置。上一章中介绍的线性回
归就是典型的线性模型,直接用 f ( x , w ) f(\mathbf{x},\mathbf{w}) f(x,w)来预测输出目标 y = f ( x , w ) y=f(\mathbf{x},\mathbf{w}) y=f(x,w)。
因此,本节将介绍如何只利用 Tensor 和 autograd 来实现一个线性回归的训练。
生成数据集
我们构造一个简单的人工训练数据集,它可以使我们能够直观比较学到的参数和真实的模型参数的区别。设训练数据集样本数为1000,输入个数 (特征数)为2。给定随机生成的批量样本特征 X ∈ R 1000 × 2 \boldsymbol{X}\in\mathbb{R}^{1000\times2} X∈R1000×2,我们使用线性回归模型真实权重 w = [ 2 , − 3.4 ] ⊤ \boldsymbol{w}=[2,-3.4]^{\top} w=[2,−3.4]⊤和偏差 b = 4.2 b=4.2 b=4.2。以及一个随机噪声项 ϵ \epsilon ϵ来生成标签。
y = X w + b + ϵ \boldsymbol{y}=\boldsymbol{X}\boldsymbol{w}+b+\epsilon\quad\quad\text{} y=Xw+b+ϵ
其中噪声项 ϵ \epsilon ϵ 服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰。下面,让我们生成数据集。
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.from_numpy(np.random.normal(0, 1, (num_examples,
num_inputs)))
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] +
true_b
labels += torch.from_numpy(np.random.normal(0, 0.01,
size=labels.size()))
features 的每一行是一个长度为2的向量,而 labels 的每一行是个长度为1的向量 (标量)。
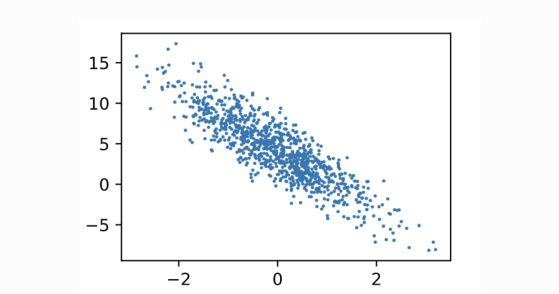
通过生成第二个特征 features[:,1]和标签labels的散点图,可以更直观地观察两者间的线性关系。
def use_svg_display():
# ⽤用⽮矢量量图显示
display.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺⼨寸
plt.rcParams['figure.figsize'] = figsize
# # 在../d2lzh_pytorch⾥里里⾯面添加上⾯面两个函数后就可以这样导⼊入
# import sys
# sys.path.append("..")
# from d2lzh_pytorch import *
set_figsize()
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
我们将上面的plt作图函数以及 use_svg display 函数和set figsize
函数定义在 d2lzh_pytorch 包里。以后在作图时,我们将直接调用 d2lzh_pytorch.plt 。由于 plt
在 d2lzh_pytorch包中是一个全局变量,我们在作图前只需要调
用 d2lzh_pytorch.set_figsize() 即可打印矢量图并设置图的尺寸。
读取数据
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数: 它每次返回 batch size(批量大小)个随机样本的特征和标签。
# 本函数已保存在d2lzh包中⽅方便便以后使⽤用
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size,
num_examples)]) # 最后⼀一次可能不不⾜足⼀一个batch
yield features.index_select(0, j), labels.index_select(0,
j)
让我们读取第⼀个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输入个数;标签形状为批量大小。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break
输出:
tensor([[-1.4239, -1.3788],
[ 0.0275, 1.3550],
[ 0.7616, -1.1384],
[ 0.2967, -0.1162],
[ 0.0822, 2.0826],
[-0.6343, -0.7222],
[ 0.4282, 0.0235],
[ 1.4056, 0.3506],
[-0.6496, -0.5202],
[-0.3969, -0.9951]])
tensor([ 6.0394, -0.3365, 9.5882, 5.1810, -2.7355, 5.3873,
4.9827, 5.7962,
4.6727, 6.7921])
初始化模型参数
我们将权重初始化成均值为0、标准差为0.01的正态随机数,偏差则初始化成0。
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)),
dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
之后的模型训练中需要对这些参数求梯度来迭代参数的值,因此我们要让它们的
requires_grad=True 。
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
定义模型
下面是线性回归的矢量计算表达式的实现。我们使用 mm 函数做矩阵乘法。
def linreg(X, w, b): # 本函数已保存在d2lzh_pytorch包中⽅方便便以后使⽤用
return torch.mm(X, w) + b
我们使用上一节描述的平方损失来定义线性回归的损失函数。在实现中,我们需要把真实值y 变形成预测值y_hat 的形状。以下函数返回的结果也将和y_hat 的形状相同。
定义优化算法
以下的 sgd 函数实现了上一节中介绍的小批量随机梯度下降算法。它通过不断迭代模型参数来优化损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和。我们将它除以批量大小来得到平均值。
def sgd(params, lr, batch_size): # 本函数已保存在d2lzh_pytorch包中⽅方便便
以后使⽤用
for param in params:
param.data -= lr * param.grad / batch_size # 注意这⾥里里更更改param
时⽤用的param.data
小批量数据大小:我们应该如何设置小批量数据的大小?
为了回答这个问题,让我们先假设正在进行在线学习,也就是说使用大小为 1的小批量数据。一个关于在线学习的担忧是使用只有一个样本的小批量数据会带来关于梯度的错误估计。实际上,误差并不会真的产生这个问题。原因在于单一的梯度估计不需要绝对精确。我们需要的是确保代价函数保持下降的足够精确的估计。就像你现在要去北极点,但是只有一个不大精确的(差个 10- 20 度)指南针。如果你不再频繁地检查指南针,指南针会在平均状况下给出正确
的方向,所以最后你也能抵达北极点。基于这个观点,这看起来好像我们需要使用在线学习。实际上,情况会变得更加复杂。
所以,取决于硬件和线性代数库的实现细节,这会比循环方式进行梯度更新快好多。也许是 50 和 100 倍的差别
现在,看起来这对我们帮助不大。我们使用 100 的小批量数据的学习规则如下:
w → w ′ = w − η 1 100 ∑ x ∇ C x w\to w'=w-\eta\frac{1}{100}\sum_x\nabla C_x w→w′=w−η1001x∑∇Cx
所以,选择最好的小批量数据大小也是一种折衷。太小了,你不会用上很好的矩阵库的快速计算。太大,你是不能够足够频繁地更新权重的。你所需要的是选择一个折衷的值,可以最大化学习的速度。幸运的是,小批量数据大小的选择其实是相对独立的一个超参数 (网络整体架构外的参数),所以你不需要优化那些参数来寻找好的小批量数据大小。