文章目录
关于更新
学校的出勤系统升级了,所以本文章的代码不能用了。
PS:新系统很不错,突然不想重写代码了 ︿( ̄︶ ̄)︿,老版的就当个例子看看吧。
提示一下新系统的登录为加密传输。
发送的是 json 的报文,大概这样:
client: "web_atd"
loginName: "1234567890"
pwd: "XXXXXXXXXXXXXXXXXXXXXX"
type: "1"
verificationCode: "1234"
loginName 为用户名。
pwd 为 AES 加密后的密码。
verificationCode 为验证码。
关于 AES 算法的详细配置我已通过网站源代码找到:
加密模式:ECB
填充方式:pkcs7
编码:utf-8
密钥:k;)*(+nmjdsf$#@d
设置好表单后用下面方法发送 json 的报文
requests.post(url,json=form)
前言
初学爬虫时我就想做一个针对学校系统的爬虫,学校电脑端的出勤系统又正好适合用爬虫来爬取出勤信息。也有另一个原因,这个系统的响应是真的慢(点击打开中南大学学生学习行为信息系统),我的电脑大概要4秒左右才能完全显示,而且每次登录后不能保存账号密码,输错了还得全部重输一次,所以我产生了用 python 做出勤系统爬虫的想法
实现流程
抓取登录需要提交的表单
使用用 Chrome 自带的抓包工具进行抓取,单击右键选择检查即可调出开发者工具,然后进入 Network 栏,先输入错误的账号密码使登录失败,抓取到的 POST 请求如下图所示,得到了登录请求的 url (Request URL)和提交的表单格式(Form Data)
表单为明文发送,格式如下:
- userName 账号
- password 密码
- code 验证码


模拟登录
采用 requests 库的 session() 建立一个会话对象来保存请求网页信息时的cookie,按照我的理解,这是为了保证我们登陆时填写的验证码和我们获取的验证码是相同的(向服务器说明我们登录使用的是哪个验证码)以及后续操作的进行
s = requests.sessions.Session() #调用session()保存cookie
首先获取验证码的资源地址,可以通过查看网页源代码找到,再通过字节流(BytesIO)和 PIL 库生成图片对象将其存在内存中
验证码 url:http://classroom.csu.edu.cn/logincode.do?t1=1568253421304
check_html = s.get(check_url,timeout = 3)
im=Image.open(BytesIO(check_html.content))#将图片信息输入字节流再用Image打开生成图片对象
再通过 pytesseract 库调用光学字符识别引擎 Tesseract OCR(这个是安装在电脑上的软件)来识别验证码(验证码很简单就是4个数字),如果没有安装 Tesseract OCR 请参考这个教程 tesseract-ocr的安装及使用。
最后按表单格式提交表单进行 POST 请求登录
account = '在此输入你的账号'#账号
password = '在此输入你的密码'#密码
form ={
'userName': account, 'password': password, 'code': pytesseract.image_to_string(im)}#提交的表单
s.post(login_url,timeout = 10,data = form)
获取基本信息
提交后查看返回的信息: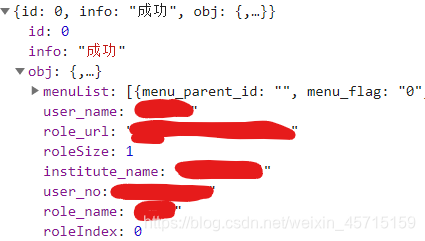
可以看出,返回的信息为 json 格式,通过 requests 库 response 对象的json() 方法将 json 格式的信息转换为 python 的字典格式
r_text = s.post(login_url,timeout = 10,data = form).json() #转换为字典格式
info1 = r_text['obj']
info1['user_name']#学生姓名
info1['user_no']#学号
info1['institute_name']#学院
info1['role_name']#身份
登录成功后,以此类推,获取出勤信息需要请求的出勤界面的 url(通过手动点击出勤界面再抓包获得)
- http://classroom.csu.edu.cn/student/homedata.do 主页
- http://classroom.csu.edu.cn/student/stuCourseList.do 考勤页
其中考勤页的请求需要 post 请求。
关于中英文格式化输出
在我的程序中有这样一段代码:
def print_format(string,way,width,fill= ' ',ed = ''):#格式输出函数,默认格式填充用单空格,不换行。
try:
count = 0#长宽度中文字符数量
for word in string:#检测长宽度中文字符
if (word >='\u4e00' and word <= '\u9fa5') or word in [';',':',',','(',')','!','?','——','……','、','》','《']:
count+=1
width = width-count if width>=count else 0
print('{0:{1}{2}{3}}'.format(string,fill,way,width),end = ed,flush=True)
except:
print('print_format函数参数输入错误!')
- 该函数负责将中英文混合的字符串像英文字符串一样格式化输出,因为如果采用传统的 print 函数的格式化输出方法的话,中文汉字和一些中文字符(例如 《 》)的宽度为英文字符宽度的两倍,而 print 格式化输出是用英文单空格填充的,即使采用 chr(12288) 即中文单空格来填充的话也只能针对全为中文的字符串
- 我的这个字符串格式化输出函数的原理是将宽中文字符视为 2 个英文字符,对齐宽度依照英文字符的个数,通过检测字符串中的宽中文字符数量每一个宽中文字符实际对齐宽度减一,来实现中英文混合格式化输出
该函数同样能自定义对齐方式,填充字符和结束字符
例如:
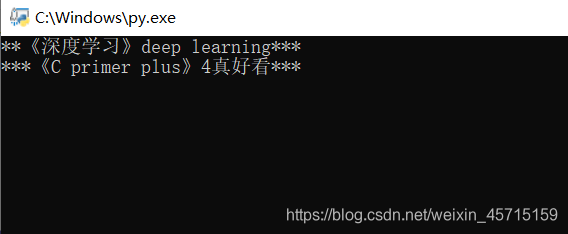
print_format('《深度学习》deep learning','^',30,'*','\n')
print_format('《C primer plus》4真好看','^',30,'*')
效果:
完整代码
验证码自动识别版 (pytesseract)
程序需要安装的库是:pytesseract,Pillow,requests
import pytesseract#图像识别库
from PIL import Image
import requests
from io import BytesIO#字节流
check_url = 'http://classroom.csu.edu.cn/logincode.do?t1=1568253421304'#验证码页面
login_url = 'http://classroom.csu.edu.cn/sys/login.do?aa=123'#登陆页面
home_url = 'http://classroom.csu.edu.cn/student/homedata.do'#主页
class_url = 'http://classroom.csu.edu.cn/student/stuCourseList.do'#考勤页
s = requests.sessions.Session()#调用session()保存cookie
def print_format(string,way,width,fill= ' ',ed = ''):#格式输出函数,默认格式填充用单空格,不换行。
try:
count = 0#长宽度中文字符数量
for word in string:#检测长宽度中文字符
if (word >='\u4e00' and word <= '\u9fa5') or word in [';',':',',','(',')','!','?','——','……','、','》','《']:
count+=1
width = width-count if width>=count else 0
print('{0:{1}{2}{3}}'.format(string,fill,way,width),end = ed,flush=True)
except:
print('print_format函数参数输入错误!')
try:
check_html = s.get(check_url,timeout = 5)#获取图片信息
except requests.exceptions.ConnectTimeout:#超时
input('出勤系统已关闭!')
exit(1)
except requests.exceptions.ConnectionError:#未连接网络
input('没有连接网络!')
exit(1)
im=Image.open(BytesIO(check_html.content))#将图片信息输入字节流再用Image打开生成图片对象
account = '在此输入你的账号'#账号
password = '在此输入你的密码'#密码
form ={
'userName': account, 'password': password, 'code': pytesseract.image_to_string(im)}#提交的表单
try:
r_text = s.post(login_url,timeout = 10,data = form).json()#提交账号密码和验证码,获取基本信息
print('登录状态:'+ r_text['info'],flush=True)#打印登录状态信息
info1 = r_text['obj']#转换为字典格式
stu_name = info1['user_name']#学生姓名
stu_id = info1['user_no']#学号
stu_institute = info1['institute_name']#学院
stu_role = info1['role_name']#身份
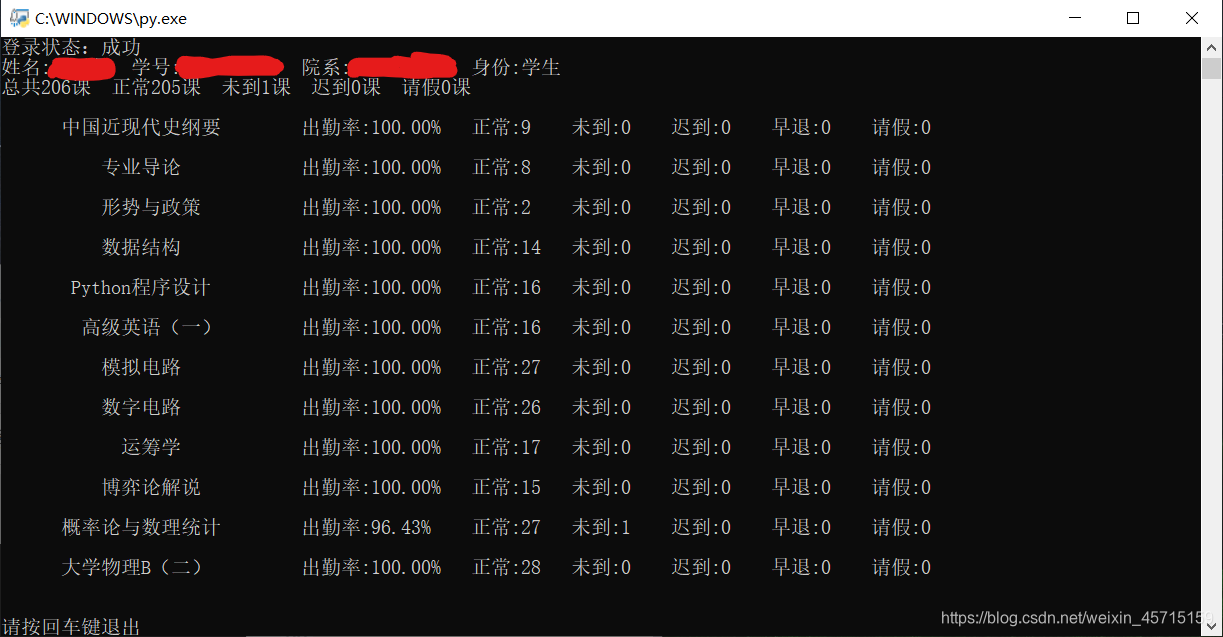
print(f'姓名:{stu_name} 学号:{stu_id} 院系:{stu_institute} 身份:{stu_role}',flush=True)
except:
input('登录发生错误!')
exit(1)
try:
r_text = s.post(home_url,timeout = 10).json()#获取主页
info2 = r_text['obj']['chart1']#转换为字典格式
total = info2['student_total']#总课时
late = info2['student_late']#迟到
leave = info2['student_leave']#请假
truant = info2['student_truant']#未到
normal = info2['student_normal']#正常
print(f'总共{total}课 正常{normal}课 未到{truant}课 迟到{late}课 请假{leave}课'+ '\n',flush=True)
except:
print('主页获取发生错误!')
try:
r_text = s.post(class_url,timeout = 10,data = {
'pageSize': '100'}).json()#获取考勤页
info3 = r_text['rows']#转换为字典格式
for i in info3:
name = i['course_name']#课程名称
att_percent = i['att_percent']#出勤率
leave = i['student_leave']#请假
late = i['student_late']#请假
truant = i['student_truant']#未到
normal = i['student_normal']#正常
leaveearly = i['student_leaveearly']#早退
print_format(name,'^',15)
print("出勤率:{0:<10}正常:{1:<5}未到:{2:<5}迟到:{3:<5}早退:{4:<5}请假:{5:<5}".format(att_percent,normal,truant,late,leaveearly,leave)+'\n',flush=True)
except:
print('出勤信息获取发生错误!')
input('\n'+"请按回车键退出")
无验证码自动识别版
下面的代码可以实现打开验证码图片自己输入验证码登录来获取出勤信息。
程序需要安装的库是:Pillow,requests,请自行安装。
from PIL import Image
import requests
from io import BytesIO#字节流
check_url = 'http://classroom.csu.edu.cn/logincode.do?t1=1568253421304'#验证码页面
login_url = 'http://classroom.csu.edu.cn/sys/login.do?aa=123'#登陆页面
home_url = 'http://classroom.csu.edu.cn/student/homedata.do'#主页
class_url = 'http://classroom.csu.edu.cn/student/stuCourseList.do'#考勤页
s = requests.sessions.Session()#调用session()保存cookie
def print_format(string,way,width,fill= ' ',ed = ''):#格式输出函数,默认格式填充用单空格,不换行。
try:
count = 0#长宽度中文字符数量
for word in string:#检测长宽度中文字符
if (word >='\u4e00' and word <= '\u9fa5') or word in [';',':',',','(',')','!','?','——','……','、','》','《']:
count+=1
width = width-count if width>=count else 0
print('{0:{1}{2}{3}}'.format(string,fill,way,width),end = ed,flush=True)
except:
print('print_format函数参数输入错误!')
try:
check_html = s.get(check_url,timeout = 5)#获取图片信息
except requests.exceptions.ConnectTimeout:#超时
input('出勤系统已关闭!')
exit(1)
except requests.exceptions.ConnectionError:#未连接网络
input('没有连接网络!')
exit(1)
im=Image.open(BytesIO(check_html.content))#将图片信息输入字节流再用Image打开生成图片对象
im.show()#打开验证码
account = '在此输入你的账号'#账号
password = '在此输入你的密码'#密码
form ={
'userName': account, 'password': password, 'code': input('请输入验证码:')}#提交的表单
try:
r_text = s.post(login_url,timeout = 10,data = form).json()#提交账号密码和验证码,获取基本信息
print('登录状态:'+ r_text['info'],flush=True)#打印登录状态信息
info1 = r_text['obj']#转换为字典格式
stu_name = info1['user_name']#学生姓名
stu_id = info1['user_no']#学号
stu_institute = info1['institute_name']#学院
stu_role = info1['role_name']#身份
print(f'姓名:{stu_name} 学号:{stu_id} 院系:{stu_institute} 身份:{stu_role}',flush=True)
except:
input('登录发生错误!')
exit(1)
try:
r_text = s.post(home_url,timeout = 10).json()#获取主页
info2 = r_text['obj']['chart1']#转换为字典格式
total = info2['student_total']#总课时
late = info2['student_late']#迟到
leave = info2['student_leave']#请假
truant = info2['student_truant']#未到
normal = info2['student_normal']#正常
print(f'总共{total}课 正常{normal}课 未到{truant}课 迟到{late}课 请假{leave}课'+ '\n',flush=True)
except:
print('主页获取发生错误!')
try:
r_text = s.post(class_url,timeout = 10,data = {
'pageSize': '100'}).json()#获取考勤页
info3 = r_text['rows']#转换为字典格式
for i in info3:
name = i['course_name']#课程名称
att_percent = i['att_percent']#出勤率
leave = i['student_leave']#请假
late = i['student_late']#请假
truant = i['student_truant']#未到
normal = i['student_normal']#正常
leaveearly = i['student_leaveearly']#早退
print_format(name,'^',24)
print("出勤率:{0:<10}正常:{1:<5}未到:{2:<5}迟到:{3:<5}早退:{4:<5}请假:{5:<5}".format(att_percent,normal,truant,late,leaveearly,leave)+'\n',flush=True)
except:
print('出勤信息获取发生错误!')
input('\n'+"请按回车键退出")
cookie 版
为模拟登录和 cookie 登录的复合版,实现模拟登陆后保存 cookie 在文本文件里,再次登录时读取文本文件里的 cookie 信息利用 cookie 直接登录,如果 cookie 过期再次登录时会自动更新,一般 cookie 的有效时间为 4 小时左右
需要安装的库:pytesseract,Pillow,requests
import requests
import os
user_url = 'http://classroom.csu.edu.cn/loadUser.do'#用户界面
home_url = 'http://classroom.csu.edu.cn/student/homedata.do'#主页
class_url = 'http://classroom.csu.edu.cn/student/stuCourseList.do'#考勤页
check_url = 'http://classroom.csu.edu.cn/logincode.do?t1=1568253421304'#验证码页面
login_url = 'http://classroom.csu.edu.cn/sys/login.do?aa=123'#登陆页面
s = requests.sessions.Session()#调用session()保存cookie
def print_format(string,way,width,fill= ' ',ed = ''):#格式输出函数,默认格式填充用单空格,不换行。
try:
count = 0#长宽度中文字符数量
for word in string:#检测长宽度中文字符
if (word >='\u4e00' and word <= '\u9fa5') or word in [';',':',',','(',')','!','?','——','……','、','》','《']:
count+=1
width = width-count if width>=count else 0
print('{0:{1}{2}{3}}'.format(string,fill,way,width),end = ed,flush=True)
except:
print('print_format函数参数输入错误!')
def login(check_url,login_url):#模拟登录并更新cookie
from pytesseract import image_to_string#调用图像识别库
from io import BytesIO#字节流
from PIL import Image
try:
s.cookies.clear()#清空cookie
r = s.get(check_url,timeout = 5)
except requests.exceptions.ConnectTimeout:
input('出勤系统已关闭!')
exit(1)
except requests.exceptions.ConnectionError:
input('没有连接网络!')
exit(1)
predict_code = image_to_string(Image.open(BytesIO(r.content)))#识别验证码
form ={
'userName': '你的账号', 'password': '你的密码', 'code': predict_code}#提交的表单
try:
r_text = s.post(login_url,timeout = 10,data = form).json()#提交账号密码和验证码,获取基本信息
if r_text['info'] != '成功':
raise ValueError(r_text['info'])
with open('cookies.txt','w') as f:#更新cookie
f.write(str(requests.utils.dict_from_cookiejar(s.cookies)))
print('cookie更新成功!')
except ValueError as e:
input(e)
exit(1)
def initial():#初始化
if os.path.exists('cookies.txt'):
with open('cookies.txt','r') as f:
s.cookies = requests.utils.cookiejar_from_dict(eval(f.readline()))#读取文本保存的cookie
else:
login(check_url,login_url)#登录获取cookie
def get_user_info(user_url):#获取用户信息
try:
if(s.post(user_url,timeout = 5).json()['info'] == '请先登录系统 !'):
print('cookie已过期!')
login(check_url,login_url)#cookie过期重新登录更新cookie
r_text = s.post(user_url,timeout = 5).json()
info1 = r_text['obj']#转换为字典格式
stu_name = info1['user_name']#学生姓名
stu_id = info1['user_no']#学号
stu_institute = info1['institute_name']#学院
stu_role = info1['role_name']#身份
print(f'姓名:{stu_name} 学号:{stu_id} 院系:{stu_institute} 身份:{stu_role}',flush=True)
except:
print('用户信息获取发生错误!')
def get_num_info(home_url):#获取课程出勤数量信息
try:
r_text = s.post(home_url,timeout = 10).json()#获取主页
info2 = r_text['obj']['chart1']#转换为字典格式
total = info2['student_total']#总课时
late = info2['student_late']#迟到
leave = info2['student_leave']#请假
truant = info2['student_truant']#未到
normal = info2['student_normal']#正常
print(f'\n总共{total}课 正常{normal}课 未到{truant}课 迟到{late}课 请假{leave}课\n',flush=True)
except:
print('\n出勤数量信息获取发生错误!\n')
def get_class_info(class_url):#获取出勤详细信息
try:
r_text = s.post(class_url,timeout = 10,data = {
'pageSize': '100'}).json()#获取考勤页
info3 = r_text['rows']#转换为字典格式
for i in info3:
name = i['course_name']#课程名称
att_percent = i['att_percent']#出勤率
leave = i['student_leave']#请假
late = i['student_late']#请假
truant = i['student_truant']#未到
normal = i['student_normal']#正常
leaveearly = i['student_leaveearly']#早退
print_format(name,'^',24)
print("出勤率:{0:<10}正常:{1:<5}未到:{2:<5}迟到:{3:<5}早退:{4:<5}请假:{5:<5}".format(att_percent,normal,truant,late,leaveearly,leave)+'\n',flush=True)
except:
print('出勤详细信息获取发生错误!')
initial()
get_user_info(user_url)
get_num_info(home_url)
get_class_info(class_url)
input('\n'+"请按回车键退出")
运行效果