CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Grid-guided Neural Radiance Fields for Large Urban Scenes

标题:用于大型城市场景的网格引导神经辐射场
作者:Linning Xu, Yuanbo Xiangli, Sida Peng, Xingang Pan, Nanxuan Zhao, Christian Theobalt, Bo Dai, Dahua Lin
文章链接:https://arxiv.org/abs/2303.14001
项目代码:https://city-super.github.io/gridnerf/

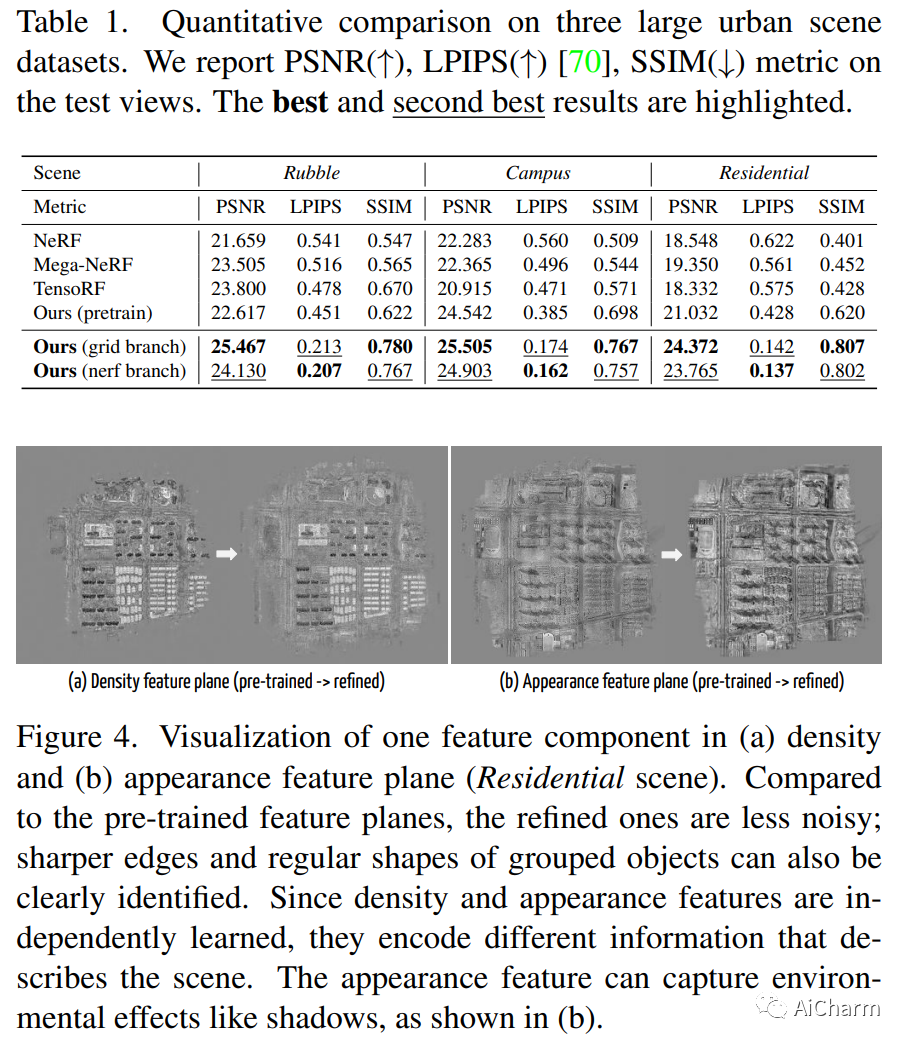
摘要:
由于模型容量有限,纯基于 MLP 的神经辐射场(基于 NeRF 的方法)在大型场景上经常会出现渲染模糊的欠拟合问题。最近的方法提出在地理上划分场景并采用多个子 NeRF 分别对每个区域进行建模,从而导致训练成本和子 NeRF 的数量随着场景的扩展而线性增加。另一种解决方案是使用特征网格表示,它计算效率高,并且可以自然地扩展到具有更高网格分辨率的大场景。然而,特征网格往往受到较少的约束并且经常达到次优的解决方案,从而在渲染中产生嘈杂的伪影,特别是在具有复杂几何和纹理的区域中。在这项工作中,我们提出了一个新的框架,可以在计算效率高的同时实现大型城市场景的高保真渲染。我们建议使用紧凑的多分辨率地面特征平面表示来粗略捕获场景,并通过另一个 NeRF 分支用位置编码输入对其进行补充,以联合学习方式进行渲染。我们表明,这种集成可以利用两种替代解决方案的优势:在特征网格表示的指导下,轻量级 NeRF 足以渲染具有精细细节的逼真新颖视图;和联合优化的地面特征平面,可以同时获得进一步的细化,形成更准确和紧凑的特征空间,输出更自然的渲染结果。
2.Progressively Optimized Local Radiance Fields for Robust View Synthesis

标题:渐进优化的局部辐射场,用于稳健的视图合成
作者:Andreas Meuleman, Yu-Lun Liu, Chen Gao, Jia-Bin Huang, Changil Kim, Min H. Kim, Johannes Kopf
文章链接:https://arxiv.org/abs/2303.13791
项目代码:https://localrf.github.io/


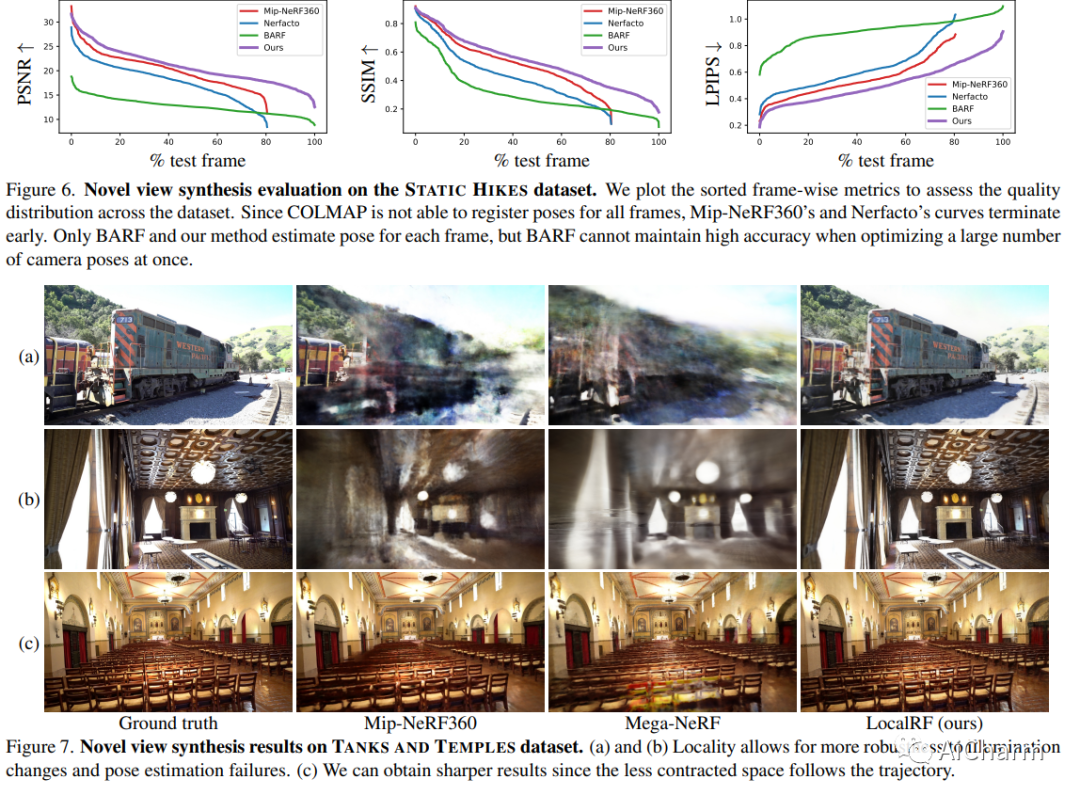
摘要:
我们提出了一种算法,用于从一个随意拍摄的视频中重建大型场景的辐射场。这项任务提出了两个核心挑战。首先,大多数现有的辐射场重建方法都依赖于从运动结构算法中准确预估的相机姿态,这在野外视频中经常失败。其次,使用具有有限表示能力的单一全局辐射场不能扩展到无界场景中的更长轨迹。为了处理未知姿势,我们以渐进的方式联合估计具有辐射场的相机姿势。我们表明,渐进优化显着提高了重建的稳健性。为了处理大型无界场景,我们动态分配新的局部辐射场,在时间窗口内用帧训练。这进一步提高了鲁棒性(例如,即使在适度的姿势漂移下也表现良好)并允许我们扩展到大场景。我们对 Tanks and Temples 数据集和我们收集的户外数据集 Static Hikes 的广泛评估表明,我们的方法与最先进的方法相比毫不逊色。
3.Reflexion: an autonomous agent with dynamic memory and self-reflection

标题:Reflexion: 具有动态记忆和自我反射的自治代理
作者:Jiayu Jiao, Yu-Ming Tang, Kun-Yu Lin, Yipeng Gao, Jinhua Ma, YaoWei Wang, Wei-Shi Zheng
文章链接:https://arxiv.org/abs/2303.11366
项目代码:https://github.com/noahshinn024/reflexion
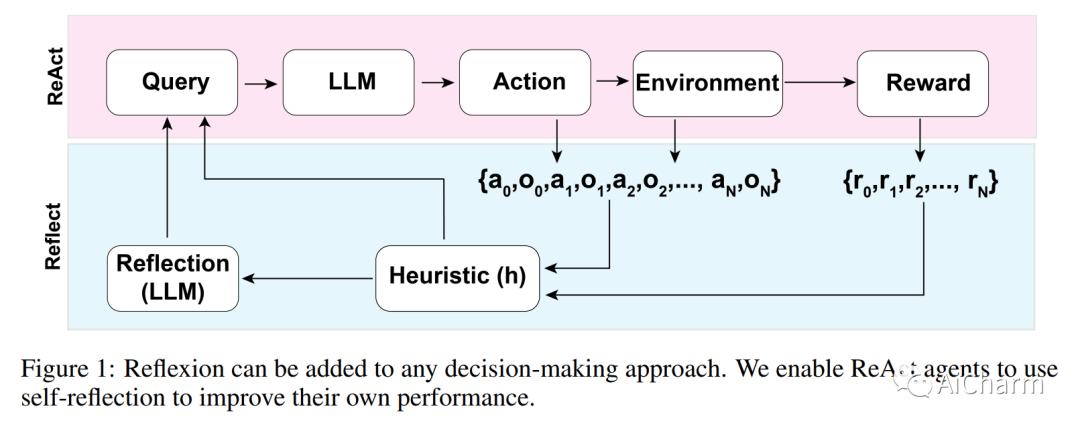

摘要:
决策制定大型语言模型 (LLM) 代理的最新进展在各种基准测试中展示了令人印象深刻的性能。然而,这些最先进的方法通常需要对定义的状态空间进行内部模型微调、外部模型微调或策略优化。由于缺乏高质量的训练数据或缺乏明确定义的状态空间,实施这些方法可能具有挑战性。此外,这些代理不具备人类决策过程所固有的某些品质,特别是从错误中学习的能力。自我反省使人类能够通过反复试验的过程有效地解决新问题。基于最近的研究,我们提出了 Reflexion,这是一种赋予代理动态记忆和自我反思能力的方法,以增强其现有的推理轨迹和特定任务的行动选择能力。为了实现完全自动化,我们引入了一种简单而有效的启发式方法,使代理能够查明幻觉实例,避免重复动作序列,并且在某些环境中构建给定环境的内部记忆映射。为了评估我们的方法,我们评估了代理在 AlfWorld 环境中完成决策任务的能力,以及在 HotPotQA 环境中完成知识密集型、基于搜索的问答任务的能力。我们观察到成功率分别为 97% 和 51%,并讨论了自我反思的涌现特性。
更多Ai资讯:公主号AiCharm