CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.AutoNeRF: Training Implicit Scene Representations with Autonomous Agents

标题:AutoNeRF:使用自主代理训练隐式场景表示
作者:Pierre Marza, Laetitia Matignon, Olivier Simonin, Dhruv Batra, Christian Wolf, Devendra Singh Chaplot
文章链接:https://arxiv.org/abs/2304.11241
项目代码:https://pierremarza.github.io/projects/autonerf/

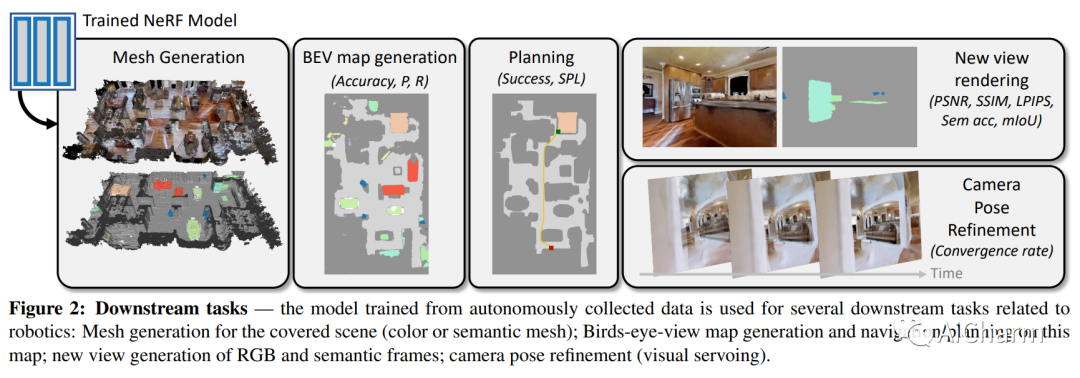



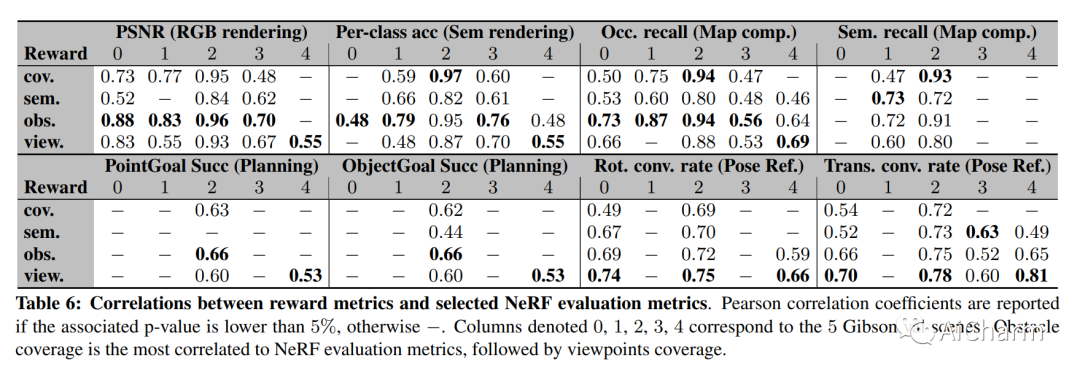
摘要:
神经辐射场 (NeRF) 等隐式表示已被证明在新视图合成方面非常有效。然而,这些模型通常需要手动和仔细的人类数据收集来进行训练。在本文中,我们介绍了 AutoNeRF,这是一种使用自主体现代理收集训练 NeRF 所需数据的方法。我们的方法允许代理有效地探索看不见的环境,并利用经验自主构建隐式地图表示。我们比较了不同探索策略的影响,包括手工制作的基于前沿的探索和由训练有素的高级规划者和经典的低级路径追随者组成的模块化方法。我们使用针对此问题量身定制的不同奖励函数来训练这些模型,并评估学习表示在四种不同下游任务上的质量:经典视点渲染、地图重建、规划和姿态优化。实证结果表明,NeRF 可以在未见过的环境中仅使用一次经验就可以根据主动收集的数据进行训练,并且可以用于多个下游机器人任务,并且经过模块化训练的探索模型明显优于经典基线。
2.Segment Anything in 3D with NeRFs

标题:使用 NeRFs 在 3D 中分割任何东西
作者:Jiazhong Cen, Zanwei Zhou, Jiemin Fang, Wei Shen, Lingxi Xie, Xiaopeng Zhang, Qi Tian
文章链接:https://arxiv.org/abs/2304.12308
项目代码:https://jumpat.github.io/SA3D/


摘要:
Segment Anything Model (SAM) 已证明其在各种 2D 图像中分割任何对象/部分的有效性,但其 3D 能力尚未得到充分探索。现实世界由无数的 3D 场景和物体组成。由于可访问的 3D 数据稀缺及其获取和注释的高成本,将 SAM 提升到 3D 是一个具有挑战性但有价值的研究途径。考虑到这一点,我们提出了一个新的框架来在 3D 中分割任何东西,称为 SA3D。给定神经辐射场 (NeRF) 模型,SA3D 允许用户在单个渲染视图中仅通过一次性手动提示获得任何目标对象的 3D 分割结果。根据输入提示,SAM 从相应的视图中剪切出目标对象。获得的 2D 分割蒙版通过密度引导逆渲染投影到 3D 蒙版网格上。然后渲染来自其他视图的 2D 蒙版,这些蒙版大部分未完成,但用作跨视图自我提示以再次输入 SAM。可以获得完整的蒙版并将其投影到蒙版网格上。此过程通过迭代方式执行,最终可以学习到准确的 3D 蒙版。SA3D无需任何额外的重新设计即可有效适应各种辐射场。整个分割过程可以在大约两分钟内完成,无需任何工程优化。我们的实验证明了 SA3D 在不同场景中的有效性,突出了 SAM 在 3D 场景感知中的潜力。
Subjects: cs.AI
3.CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval

标题:CLaMP:用于跨模态符号音乐信息检索的对比语言-音乐预训练
作者:Shangda Wu, Dingyao Yu, Xu Tan, Maosong Sun
文章链接:https://arxiv.org/abs/2304.11029
项目代码:https://github.com/microsoft/muzic/tree/main/clamp

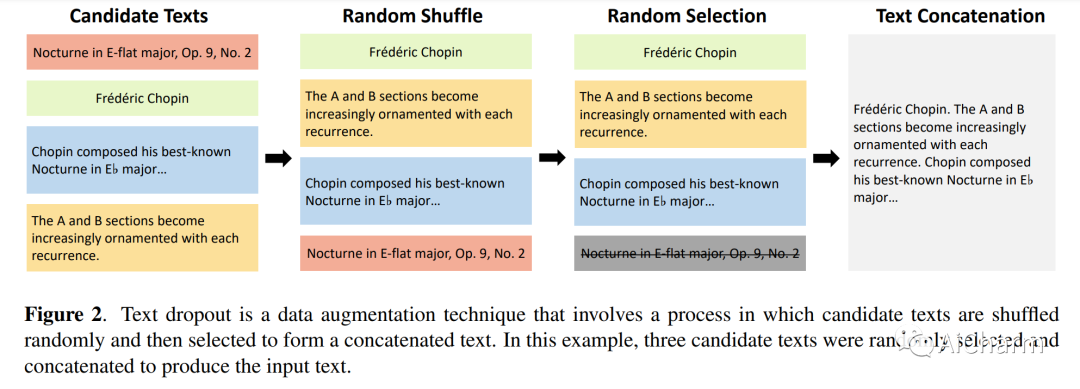
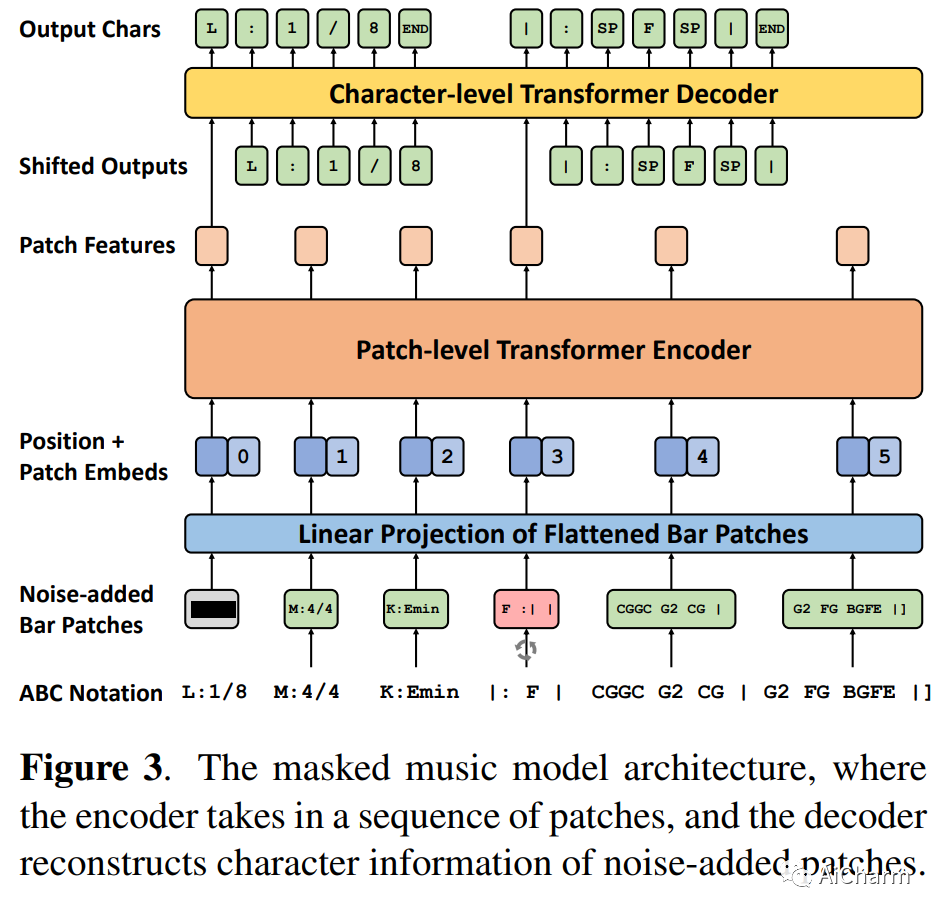

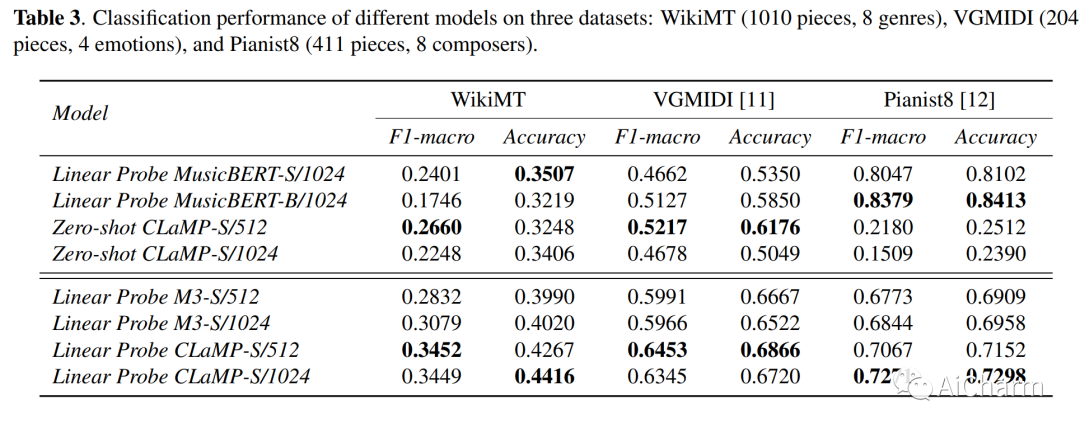
摘要:
我们介绍了 CLaMP:对比语言-音乐预训练,它使用音乐编码器和文本编码器通过对比损失联合训练来学习自然语言和符号音乐之间的跨模态表示。为了预训练 CLaMP,我们收集了 140 万个音乐文本对的大型数据集。它采用文本丢失作为数据增强技术和条形修补来有效地表示音乐数据,从而将序列长度减少到不到 10%。此外,我们开发了一个掩码音乐模型预训练目标,以增强音乐编码器对音乐背景和结构的理解。CLaMP 集成了文本信息,可以对符号音乐进行语义搜索和零样本分类,超越了之前模型的能力。为了支持语义搜索和音乐分类的评估,我们公开发布了 WikiMusicText (WikiMT),这是一个包含 1010 个 ABC 符号表的数据集,每个表都附有标题、艺术家、流派和描述。与需要微调的最先进模型相比,零样本 CLaMP 在面向分数的数据集上表现出相当或更优的性能。我们的模型和代码可从这个 https URL 获得。
更多Ai资讯:公主号AiCharm