目录

一、环境配置:
线上环境:
线下安装:
环境要求——python>=3.6、paddlehub>=1.7.0
使用pycharm创建项目:
python环境3.7
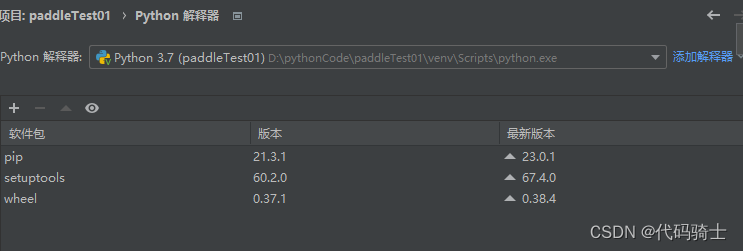
安装paddlehub库
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
升级paddlehub库
pip install --upgrade paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple二、问题需求
图像分类是计算机视觉的重要领域,它的目标是将图像分类到预定义的标签。近期,许多研究者提出很多不同种类的神经网络,并且极大的提升了分类算法的性能。本文以自己创建的数据集:五位女演员图片,并使用PaddleHub中图像分类预处理模型进行小样本的迁移训练。
五位女演员分别是:
刘亦菲:

迪丽热巴:

古力娜扎:

安妮海瑟薇:

斯嘉丽约翰逊:

三、实验内容
1、准备数据集
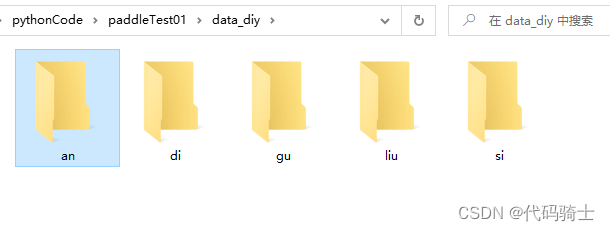
(1)建立数据文件夹:
分别用来存储不同演员的照片。
(2)使用爬虫爬取图片,保存到目录
import os
import time
import requests
import re
import time
import urllib3
urllib3.disable_warnings()
def imgdata_set(save_path,word,epoch):
q=0 #停止爬取图片条件
a=0 #图片名称
while(True):
time.sleep(1)
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn={}&ct=&ic=0&lm=-1&width=0&height=0".format(word,q)
#word=需要搜索的名字
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
session = requests.session()
try:
response = session.get(url, headers=headers, verify=False)
except:
response=requests.get(url,headers=headers,verify=False)
# print(response.request.headers)
html=response.text
# print(html)
urls=re.findall('"objURL":"(.*?)"',html)
# print(urls)
for url in urls:
time.sleep(1)
print(a) #图片的名字
response = requests.get(url, headers=headers,verify=False)
image=response.content
with open(os.path.join(save_path,"{}.jpg".format(a)),'wb') as f:
f.write(image)
a=a+1
q=q+20
if (q/20)>=int(epoch):
break
if __name__=="__main__":
save_path = input('你想保存的路径:')
word = input('你想要下载什么图片?请输入:')
epoch = input('你想要下载几轮图片?请输入(一轮为60张左右图片):') # 需要迭代几次图片
imgdata_set(save_path, word, epoch)你想保存的路径:./data_diy/di
你想要下载什么图片?请输入:迪丽热巴
你想要下载几轮图片?请输入(一轮为60张左右图片):2

每个人物保存五十张。
由于爬虫下载的图片有可能失效,在数据量较小的情况下,人为排除失效图片。
清理好后,图片名字会乱,下面重新给图片命名:
import os
import random
def rename():
i = 0
path = "data_diy/di" # 读取的文件夹路径
filelist = os.listdir(path) # 该文件夹下所有的文件(包括文件夹)
for files in filelist: # 遍历所有文件
i = i + 1
Olddir = os.path.join(path, files) # 原来的文件路径
if os.path.isdir(Olddir): # 如果是文件夹则跳过
continue
filename = str(i) # 文件名
filetype = '.jpg' # 文件扩展名
Newdir = os.path.join(path, filename + filetype) # 新的文件路径
os.rename(Olddir, Newdir) # 重命名
return True
if __name__ == '__main__':
rename()处理文件名参考
python实现文件重命名_python 文件重命名_王过836的博客-CSDN博客
解决报错:
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。附文件重命名代码_略孤狼的博客-CSDN博客_fileexistserror处理好的数据集可以打包为zip格式压缩包上传线上环境:

通过该指令进行解压:
!unzip -o /home/aistudio/data_diy/data_diy.zip2、拆分数据集
将数据集拆分成四个部分
 新建训练集、测试集、验证集和标签四个txt文本文件,并在标签列表中记下五个分类名称。
新建训练集、测试集、验证集和标签四个txt文本文件,并在标签列表中记下五个分类名称。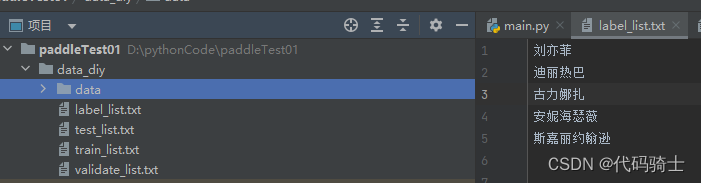
手动拆分训练集合测试集和验证集,通常按照8:1:1的比例进行拆分。
5个文件夹中各有50张图片,总共有250张图片,所以按照8:2的比例划分,训练集有200张,测试集和验证集50张,将测试集和验证集按照对应的方式划分则测试集和验证集数据相同。
所以训练集为:
an:1.jpg~40.jpg、si:1.jpg~40.jpg、liu:1.jpg~40.jpg、di:1.jpg~40.jpg、gu:1.jpg~40.jpg
测试集为:
an:41.jpg~50.jpg、si:41.jpg~50.jpg、liu:41.jpg~50.jpg、di:41~50.jpg、gu:41~50.jpg
验证集为:
an:41.jpg~50.jpg、si:41.jpg~50.jpg、liu:41.jpg~50.jpg、di:41.jpg~50.jpg、gu:41.jpg~50.jpg
文件内容格式:
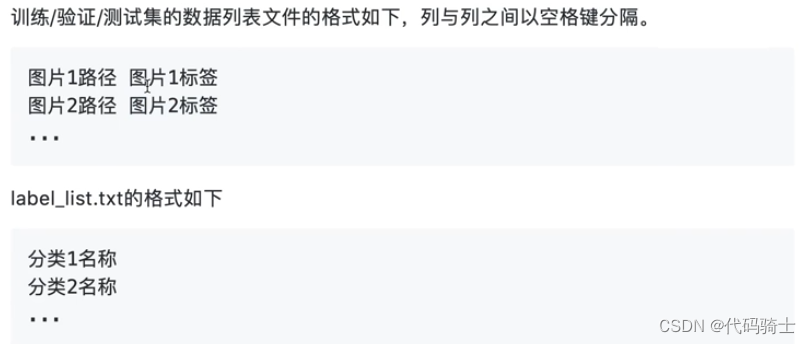
使用代码分别编写数据集:
file_names = [
'data_diy/train_list.txt',
'data_diy/test_list.txt',
'data_diy/validate_list.txt'
]
path_list = [
'data_diy/data/liu/',
'data_diy/data/di/',
'data_diy/data/gu/',
'data_diy/data/an/',
'data_diy/data/si/'
]
#编写训练集
with open(file_names[0],'w+',encoding='utf8') as f:
for i in range(5):
for j in range(1,41):
aline = path_list[i] + str(j) + '.jpg ' + str(i)+'\n'
f.write(aline)
#编写测试集
with open(file_names[1],'w+',encoding='utf8') as f:
for i in range(5):
for j in range(41,51):
aline = path_list[i] + str(j) + '.jpg ' + str(i)+'\n'
f.write(aline)
#编写验证集
with open(file_names[2],'w+',encoding='utf8') as f:
for i in range(5):
for j in range(41,51):
aline = path_list[i] + str(j) + '.jpg ' + str(i)+'\n'
f.write(aline)训练集

测试集

验证集
安装matplotlib库:
pip install matplotlib
查看图片
#显示图片
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('data_diy/data/an/1.jpg')
img1 = mpimg.imread('data_diy/data/di/1.jpg')
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.imshow(img)
plt.axis('off')
plt.subplot(1,2,2)
plt.imshow(img1)
plt.axis('off')
plt.show()
print(" 安妮海瑟薇 迪丽热巴")
3、载入数据集
线上版:
from paddlehub.dataset.base_cv_dataset import BaseCVDataset
class DemoDataset(BaseCVDataset):
def __init__(self):
# 数据集存放位置
self.dataset_dir = "data_diy"#数据文件保存目录
super(DemoDataset, self).__init__(
base_path=self.dataset_dir,
train_list_file="train_list.txt",
validate_list_file="validate_list.txt",
test_list_file="test_list.txt",
#predict_file="predict_list.txt",
label_list_file="label_list.txt",
)
dataset = DemoDataset()4、生成数据读取器
生成一个图像分类的reader,reader负责将dataset的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
当我们生成一个图像分类的reader时,需要指定输入图片的大小
data_reader = hub.reader.ImageClassificationReader(
image_width=module.get_expected_image_width(),
image_height=module.get_expected_image_height(),
images_mean=module.get_pretrained_images_mean(),
images_std=module.get_pretrained_images_std(),
dataset=dataset)5、配置策略
在进行Finetune前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
-
use_cuda:设置为False表示使用CPU进行训练。如果您本机支持GPU,且安装的是GPU版本的PaddlePaddle,我们建议您将这个选项设置为True; -
epoch:迭代轮数; -
batch_size:每次训练的时候,给模型输入的每批数据大小为32,模型训练时能够并行处理批数据,因此batch_size越大,训练的效率越高,但是同时带来了内存的负荷,过大的batch_size可能导致内存不足而无法训练,因此选择一个合适的batch_size是很重要的一步; -
log_interval:每隔10 step打印一次训练日志; -
eval_interval:每隔50 step在验证集上进行一次性能评估; -
checkpoint_dir:将训练的参数和数据保存到cv_finetune_turtorial_demo目录中; -
strategy:使用DefaultFinetuneStrategy策略进行finetune;
更多运行配置,请查看RunConfig
同时PaddleHub提供了许多优化策略,如AdamWeightDecayStrategy、ULMFiTStrategy、DefaultFinetuneStrategy等,详细信息参见策略
config = hub.RunConfig(
use_cuda=False, #是否使用GPU训练,默认为False;
num_epoch=3, #Fine-tune的轮数;
checkpoint_dir="cv_finetune_turtorial_demo",#模型checkpoint保存路径, 若用户没有指定,程序会自动生成;
batch_size=3, #训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
eval_interval=10, #模型评估的间隔,默认每100个step评估一次验证集;
strategy=hub.finetune.strategy.DefaultFinetuneStrategy()) #Fine-tune优化策略;6、组建Finetune Task
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个Task。
由于该数据设置是一个二分类的任务,而我们下载的分类module是在ImageNet数据集上训练的千分类模型,所以我们需要对模型进行简单的微调,把模型改造为一个二分类模型:
- 获取module的上下文环境,包括输入和输出的变量,以及Paddle Program;
- 从输出变量中找到特征图提取层feature_map;
- 在feature_map后面接入一个全连接层,生成Task;
input_dict, output_dict, program = module.context(trainable=True)
img = input_dict["image"]
feature_map = output_dict["feature_map"]
feed_list = [img.name]
task = hub.ImageClassifierTask(
data_reader=data_reader,
feed_list=feed_list,
feature=feature_map,
num_classes=dataset.num_labels,
config=config)7、开始Finetune
我们选择finetune_and_eval接口来进行模型训练,这个接口在finetune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。
run_states = task.finetune_and_eval()8、预测
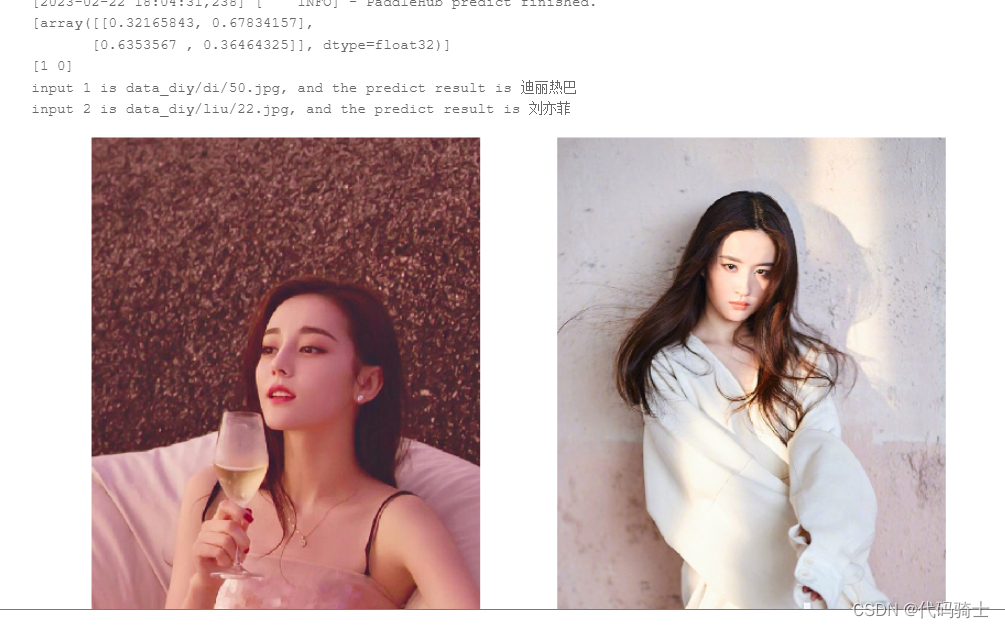
当Finetune完成后,我们使用模型来进行预测,先通过以下命令来获取测试的图片
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
data = ["data_diy/di/50.jpg","data_diy/liu/44.jpg"]
label_map = dataset.label_dict()
index = 0
run_states = task.predict(data=data)
results = [run_state.run_results for run_state in run_states]
for batch_result in results:
print(batch_result)
batch_result = np.argmax(batch_result, axis=2)[0]
print(batch_result)
for result in batch_result:
index += 1
result = label_map[result]
print("input %i is %s, and the predict result is %s" %
(index, data[index - 1], result))
img = mpimg.imread(data[0])
img1 = mpimg.imread(data[1])
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.imshow(img)
plt.axis('off')
plt.subplot(1,2,2)
plt.imshow(img1)
plt.axis('off')
plt.show()最后的预测效果并不怎么理想,五个人识别一顿扒瞎,最后只好弄成二分类的了,还勉强说得过去。
四、总结:
结果错误的三大原因:
1、数据样本太少了
2、模型调参不到位
3、预训练模型的选择可能不是太适合