- 课程:《密码与安全新技术》
- 班级: 1792班
- 姓名: 李栋
- 学号:20179210
- 上课教师:谢四江
- 主讲人:赵绪营
- 上课日期:2018年5月24日
- 必修/选修: 必修
一、基础概念
模式识别 (Pattern Recognition)
- 用各种数学方法让计算机(软件与硬件)来实现人的模式识别能力,即用计算机实现人对各种事物或现象的分析、描述、判断、识别
人的模式识别能力
- 人通过视觉、嗅觉、听觉、味觉、触觉接收外界信息、再经过人脑根据已有知识进行适当的处理后作出的判别事物或者划分事物性质(类别)的能力
模式或者模式类
- 可以是研究对象的组成成分或影响因素之间存在的规律性关系,因素之间存在确定性或随机性规律的对象、过程或者事件的集合。
识别
- 对以前见过的对象的再认识(Re-cognition)
模式识别
- 对模式的区分与认识,将待识别的对象根据其特征归并到若干类别中某一类
类或者类别(class):
- 在样本集上定义的模式类子集合,同一类的样本在我们所关心的某种性质上是不可区分的,即具有相同的模式。
- 例:自行车:普通车、变速车、山地车、运动车
特征(feature)或者属性(attribute):
- 描述样本的若干观测值。多个特征或属性构造特征向量或者属性向量,通常与样本向量混用。
- 例:26英寸轮胎,人的身高与体重
二、模式识别的主要方法
- 划分的原则
- 问题的描述方式
- 问题或样本性质
- 理论基础
- 应用领域
根据问题的描述方式:
- 基于知识的模式识别方法:以专家系统为代表,根据人们已知的(从专家那里收集整理得到的)知识,整理出若干描述特征与类别间关系的准则,建立一定的计算机推理系统,再对未知样本决策其类别。
- 基于数据的模式识别方法:制定描述研究对象的描述特征,收集一定数量的已知样本作为训练集训练一个模式识别机器,再对未知样本预测其类别(主要研究内容)
根据问题的划分
- 监督模式识别:先有一批已知样本作为训练集设计分类器,再判断新的样本类别(分类)
- 非监督模式识别:只有一批样本,根据样本之间的相似性直接将样本集划分成若干类别(聚类)
根据理论基础的划分
- 统计模式识别:概率论与数理统计
- 模糊模式识别:模糊逻辑
- 人工神经网络:神经科学、最优化、概率论与数理统计
- 结构模式识别:形式语言
根据应用领域的划分
- 图象识别:染色体分类、遥感图象识别
- 文字识别:中外文印刷体、手写体识别
- 数字识别:0-9印刷体、手写体识别,典型例子:邮政手写数字识别
- 人脸识别:
- 指纹识别:
- 虹膜识别:
- 掌纹识别:
- 语音识别:
三、模式识别系统的典型构成
模式识别系统的四个主要组成部分:
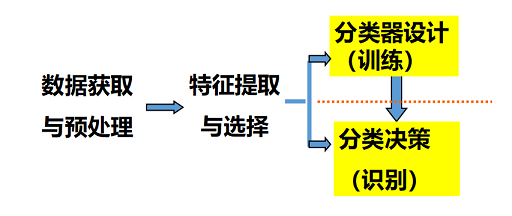
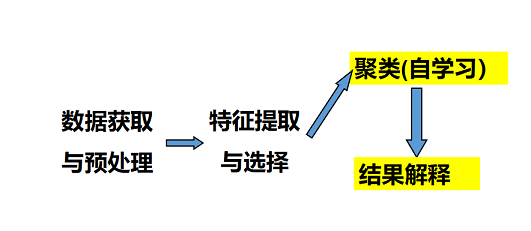
- 原始数据获取与预处理
- 特征提取和选择
- 分类或者聚类
- 后处理
监督模式识别系统的典型框图
非监督模式识别系统的典型框图
四、模式识别关注的内容
- 特征选择与提取
- 分类器的设计与评估
- 聚类算法的设计与评估
统计模式识别
- 贝叶斯(Bayes)决策理论
五、线性分类器
- Fisher准则(线性判别)
- 感知器学习算法(Perceptron Learning Algorithm )
Fisher线性判别分析(1936)的基本思想:
- 通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有性质:同类样本尽可能聚集在一起,不同类样本尽可能地远
感知器收敛定理
- 如果训练样本集是线性可分的,则,从任意的初始权向量出发,总可以在有限步迭代内找到一个权向量,使所有的样本正确分类
六、非线性分类器
- 神经网络(Neural Network)
- 引言
- 感知器
- 人工神经元及其学习规则
- 前馈神经网络及其主要算法(BP和RBF)
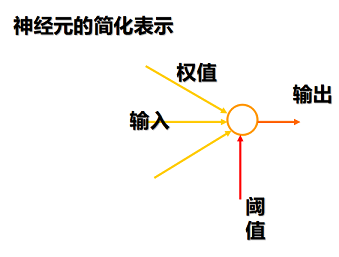
人工神经元(M-P神经元)
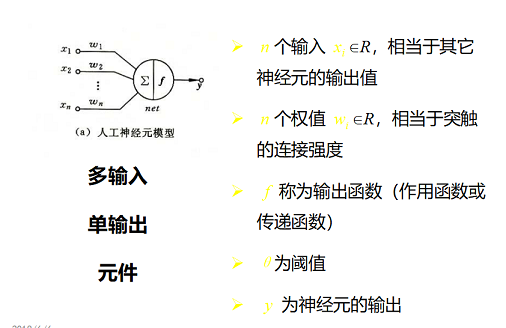
神经元的动作
- (1) 求加权和
- (2) 与阈值比较,再通过输出函数得到神经元的输出
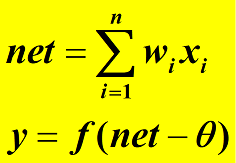
神经元的简化表示
神经元的学习算法
- Hebb学习规则的基本思想是:如果神经元 ui 接收来自另一个神经元 uj 的输出,则当这两个神经元同时兴奋时,从 ui 到 uj 的权值 wij 应该得到加强

- 一种变形是 delta 规则
(误差校正学习规则、Widrow-Hoff 规则) - 另一种变形是 Grossberg 学习规则
(竞争学习规则,1976)
前馈神经网络及其主要算法
- 前馈神经网络的结构:网络分成若干层,除输入层外,每一层神经元只接收前一层的输出,并输出到下一层,网络不存在反馈
- 反向传播算法(BP)
总结与思考
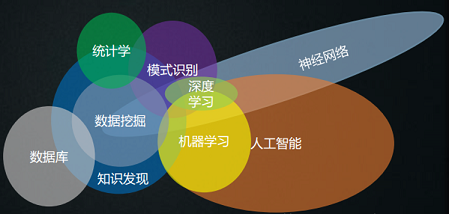
1、模式识别、机器学习的区别和联系
- 模式识别:自己建立模型刻画已有的特征,样本是用于估计模型中的参数。模式识别的落脚点是感知
- 机器学习:根据样本训练模型,如训练好的神经网络是一个针对特定分类问题的模型;重点在于“学习”,训练模型的过程就是学习;机器学习的落脚点是思考;
- 最主要的应用领域有:专家系统、认知模拟、规划和问题求解、数据挖掘、网络信息服务、图象识别、故障诊断、自然语言理解、机器人和博弈等领域。
区别与联系:
模式识别是根据已有的特征,通过参数或者非参数的方法给定模型中的参数,从而达到判别目的的;机器学习侧重于在特征不明确的情况下,用某种具有普适性的算法给定分类规则;学过多元统计的可以这样理解:模式识别的概念可以类比判别分析,是确定的,可检验的,有统计背景的(或者更进一步说有机理性基础理论背景),而机器学习的概念可以类比聚类分析(聚类本身就是一种典型的机器学习方法),对“类”的严格定义尚不明确,更谈不上检验;
针对市面上很多关于模式识别与机器学习的著作内容重合,应该这么看:
- ①算法是中性的,两个不同的学科领域关键看思维。如神经网络的应用,如果通过具体学科,如生物学的机理分析是明确了某种昆虫的基因型应该分为两类,同时确定了其差异性的基因是会表现在触角长和翅长两个表现型的话,那么构造两个(触角长,翅长)——(隐含层)——(A类,B类)的网络可以看作对已有学科知识的表达,只是通过网络刻画已有知识而已;而机器学习的思路是:采样,发现两类品种差异最大的特征是触角长和翅长(可能会用到诸如KS检验之类的方法),然后按照给定的类目:两类来构造神经网络进行分类;同一个算法,两个学科是两种思路;
②模式识别在人工智能上的前沿成果已经慢慢被机器学习取代,所以很多以AI为导向的模式识别书记包含了很多机器学习的算法也正常,毕竟很多新成果是机器学习做出的;
关于应用范围,机器学习目前是在狭义的人工智能领域走得比较快,但是广度还是模式识广,模式识别在很多经典领域,如信号处理,计算机图像与计算机视觉,自然语言分析等都不断有新发展;
从发展目标看,机器学习是要计算机学会思考,而模式识别是具体方法的自动化实现(不止计算机,还包括广义的控制系统),从立意上机器学习要高出一筹。至于现实中是否能实现,当前的机器学习热潮会不会陷入泡沫,都值得观察。
2、深度学习:一统江湖的架构
- 快进到今天,我们看到的是一个夺人眼球的技术---深度学习。而在深度学习的模型中,受宠爱最多的就是被用在大规模图像识别任务中的卷积神经网络(Convolutional Neural Nets,CNN),简称ConvNets。
- 深度学习强调的是你使用的模型(例如深度卷积多层神经网络),模型中的参数通过从数据中学习获得。然而,深度学习也带来了一些其他需要考虑的问题。因为你面对的是一个高维的模型(即庞大的网络),所以你需要大量的数据(大数据)和强大的运算能力(图形处理器,GPU)才能优化这个模型。卷积被广泛用于深度学习(尤其是计算机视觉应用中),而且它的架构往往都是非浅层的。
- 如果你要学习Deep Learning,那就得先复习下一些线性代数的基本知识,当然了,也得有编程基础。我强烈推荐Andrej Karpathy的博文:“ 神经网络的黑客指南 ”。另外,作为学习的开端,可以选择一个不用卷积操作的应用问题,然后自己实现基于CPU的反向传播算法。
3、数据挖掘
- 数据,例如图片,语音,数字数据,等等进行分类或者回归,得出规律的东西。
- 数据挖掘和机器学习的区别和联系,周志华有一篇很好的论述《机器学习与数据挖掘》可以帮助大家理解。数据挖掘受到很多学科领域的影响,其中数据库、机器学习、统计学无疑影响最大。简言之,对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。从数据分析的角度来看,绝大多数数据挖掘技术都来自机器学习领域,但机器学习研究往往并不把海量数据作为处理对象,因此,数据挖掘要对算法进行改造,使得算法性能和空间占用达到实用的地步。同时,数据挖掘还有自身独特的内容,即关联分析。
4、大数据(Big-data)
- 大数据是果,而模式识别是因。大数据解决的是所以然,而模式识别解决的是之所以然。之所以要掰扯这两个概念是因为很多公司并没有意识到这个问题,把两种混为一谈,或者把模式识别囊括到大数据中,这是错误的。只是收集数据的公司是没有什么未来的,因为你不能占有数据,而在模式识别上积累才能有未来。
思考
数据挖掘、机器学习、模式识别三者的关系,可以说是一脉相承。与数据挖掘、机器学习、模式识别相关的书籍很多,但其实讲的东西都是大同小异,换汤不换药。无非就是神经网络、支持向量机、各种分类、聚类、回归的算法,还有深度学习。人工智能是今年来关注度最高的话题,而具体的模式识别、机器学习、数据挖掘、大数据、云计算区别是什么,其实真的无关紧要,理论数学模型、数学算法并不限定所谓的领域,都是相同的。本来科学本来就没有什么明确的界限,也不必非要划定所谓的明确的边界线。