Boosting简介
分类中通常使用将多个弱分类器组合成强分类器进行分类的方法,统称为集成分类方法(Ensemble Method)。比较简单的如在Boosting之前出现Bagging的方法,首先从从整体样本集合中抽样采取不同的训练集训练弱分类器,然后使用多个弱分类器进行voting,最终的结果是分类器投票的优胜结果。这种简单的voting策略通常难以有很好的效果。直到后来的Boosting方法问世,组合弱分类器的威力才被发挥出来。Boosting意为加强、提升,也就是说将弱分类器提升为强分类器。而我们常听到的AdaBoost是Boosting发展到后来最为代表性的一类。所谓AdaBoost,即Adaptive Boosting,是指弱分类器根据学习的结果反馈Adaptively调整假设的错误率,所以也不需要任何的先验知识就可以自主训练。Breiman在他的论文里赞扬AdaBoost是最好的off-the-shelf方法。
两类Discrete AdaBoos算法流程
AdaBoosting方法大致有:Discrete Adaboost, Real AdaBoost, LogitBoost, 和Gentle AdaBoost。所有的方法训练的框架的都是相似的。以Discrete Adaboost为例,其训练流程如下:

首先初始化每个样本相同的权重(步骤2);之后使用加权的样本训练每个弱分类器 (步骤3.1);分类后得到加权的训练错误率和比例因子 (步骤3.2);将被错误分类的样本的权重加大,并将修改后的权重再次归一化(步骤3.3);循环训练过程,最终使用比例因子 组合组合弱分类器构成最终的强分类器。
下面看一个更形象的图,多个弱分类器的组合过程和结果大致为:
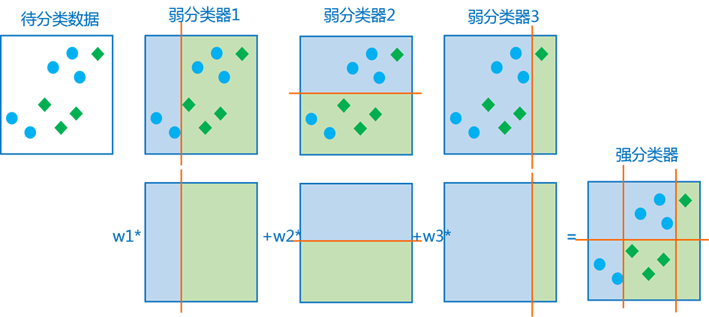
训练的循环过程,加重被错误分类的样本的权重是一种有效的加速训练的方法。由于训练中正确率高的弱分类器权重较大,新一轮的训练中正确分类的样本会越来越多,权重较小的训练样本对在新一轮的训练中起作用较小,也就是,每一轮新的训练都着重训练被错误分类的样本。
实际训练中弱分类器是一样的,但弱分类器实际使用的训练数据不同,通常使用特征向量的每一维分别构成一个弱分类器。而后来大名鼎鼎的Haar+Adaboost人脸检测方法是使用每种Haar特征构成一个弱分类器,基于Block的Haar特征比简单的基于pixel的特征有带有更多的信息,通常能得到更好的检测效果,而积分图Integral的方法使其在计算速度上也有很大优势。有兴趣可参考《基于Adaboost和Haar-like特征人脸识别》。
Real AdaBoost和Gentle AdaBoost
