DL_class
学堂在线《深度学习》实验课代码+报告(其中实验1和实验6有配套PPT),授课老师为胡晓林老师。课程链接:https://www.xuetangx.com/training/DP080910033751/619488?channel=i.area.manual_search。
持续更新中。
所有代码为作者所写,并非最后的“标准答案”,只有实验6被扣了1分,其余皆是满分。仓库链接:https://github.com/W-caner/DL_classs。 此外,欢迎关注我的CSDN:https://blog.csdn.net/Can__er?type=blog。
部分数据集由于过大无法上传,我会在博客中给出下载链接。如果对代码有疑问,有更好的思路等,也非常欢迎在评论区与我交流~
实验3:PyTorch实战——CIFAR图像分类
多层感知机(MLP)
详细介绍所使用的模型及其结果,至少包括超参数选取,损失函数、准确率及其曲线;
- 模型构成:MLP由简单的【线性变化+激活函数+损失函数】构成。根据实验二,此处选取relu作为激活函数,CrossEntropyLoss作为损失函数。
- 隐含层结点:根据以下经验性指导将隐含层结点数量控制于
[ log3072,50000/2*(3072)]和[log50,50000/2*(50)]两个区间左右,此处大致为300和100。

- 准确率曲线:见下文对比图,准确率不高,训练集达到60%左右,测试集达52%。
卷积网络(CNN)
详细介绍所使用的模型及其结果,至少包括超参数选取,损失函数、准确率及其曲线;
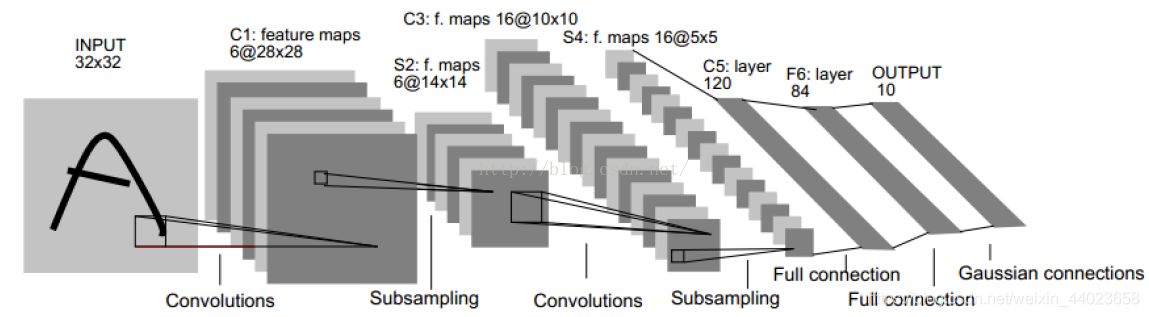
从上面的MLP演变过来,将线性连接层变成卷积层,激活函数变成最大池化,最后添加两个全连接层(线性+relu),仿照经典图像识别网络Letnet-5进行搭建,网络结构如下图所示。
定义网络并训练即可:
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=3,
out_channels=16,
kernel_size=5,
stride=1,
padding=0)
self.pool = torch.nn.MaxPool2d(kernel_size=2,
stride=2)
self.conv2 = torch.nn.Conv2d(16, 32, 5)
self.fc1 = torch.nn.Linear(32*5*5, 120)
self.fc2 = torch.nn.Linear(120, 84)
self.fc3 = torch.nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
# 卷积结束后将多层图片平铺batchsize行16*5*5列,每行为一个sample,16*5*5个特征
x = x.view(-1, 32*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
模型对比
比较不同模型配置下的结果,至少从三个方面作比较和分析,例如层数、卷积核数目、激活函数类型、损失函数类型、优化器等。
-
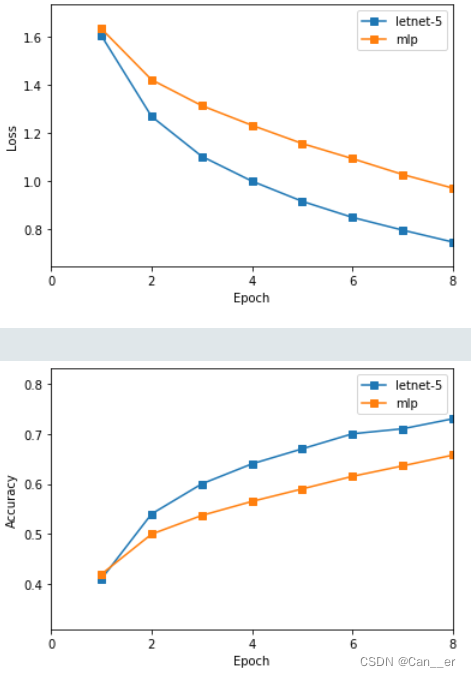
MLP和卷积:使用MLP和使用Letnet-5原始参数两个网络,训练8个周期,对比如下。卷积网络在准确率和收敛速度上都有着较好表现,最终测试集上准确率达到66.38%。
-
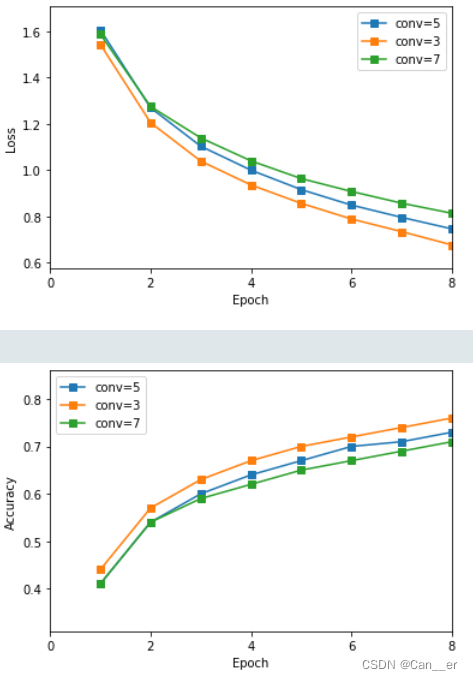
卷积核:将上述网络的卷积核分别改为3和7,进行更细致特征的提取尝试。其中,以3为例,经过两层卷积后的图片大小分别为
32-3+1=30,30/2=15,15-4+1=12,12/2=6。结论为,卷积核小而深的网络要比大而浅的网络有着更好表现。
-
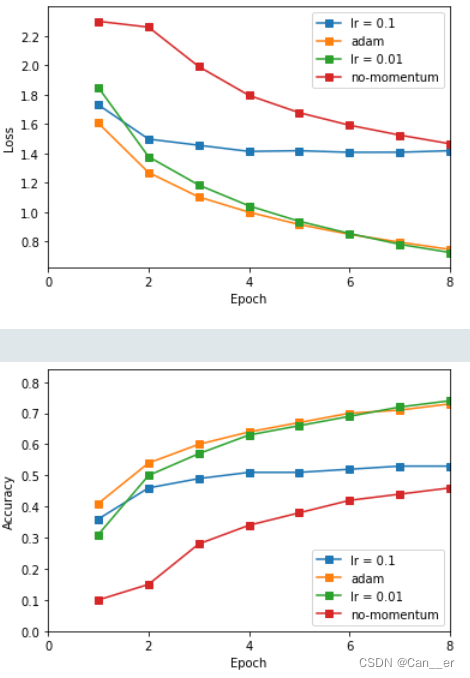
优化器:此处尝试3种优化器,一种是普通的SGD,一种是加入动量(0.9)的SGD,最后一种结合了动量和RMSProp的Adam算法,可以自动调整学习率以抑制震荡。实验结果如下图所示。可以发现,动量的引入大幅度提高了收敛速率,而过大的学习率将会导致后期不断震荡,选取0.01或更小的学习率,或使用Adam算法为较好的选择。
-
损失函数:因为是多分类问题,且标签之间不存在距离问题,所以此处使用交叉熵损失,不再尝试其它。
-
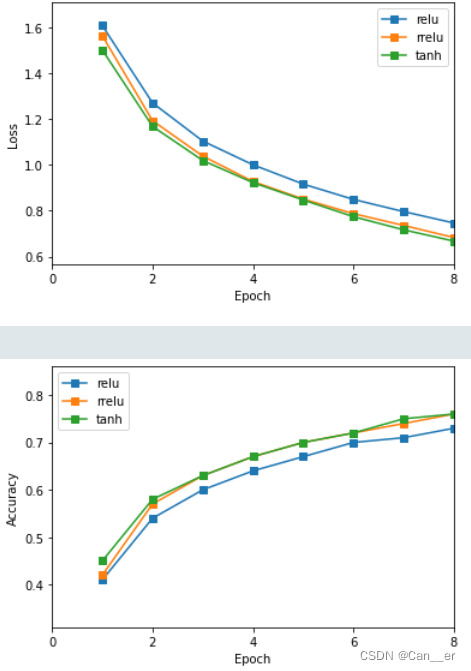
激活函数:分别使用relu,rrelu(负梯度也可以传播),sigmoid和tanh四种激活函数。sigmoid在多层深度网络中表现较差,出现明显断层(20%准确率),不再分析。rrelu和tanh有着不相上下的表现。
-
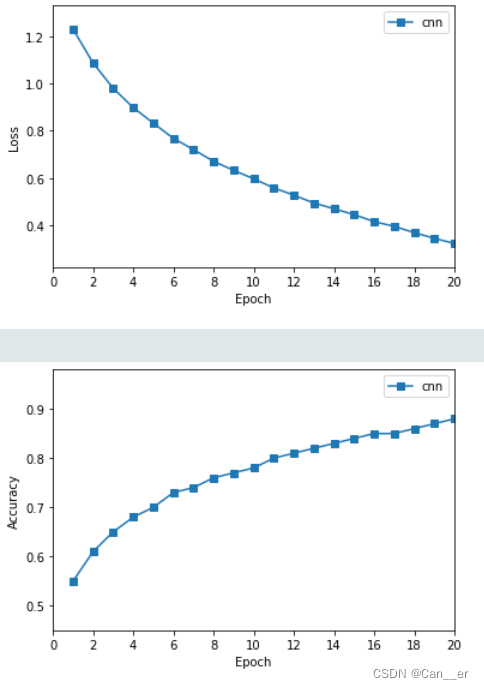
层数:根据实验二可以知道,有两个隐含层的网络结构无论在准确率和收敛性上都明显优于单层网络。同时,随着层数的增加,能够提取到的特征就越明晰,网络的表达能力也会提高,见下图为增加了一层卷积后的效果,最终训练集上准确率可以达到88%,测试集上可以达到72%。此外,随着网络层数的增加,伴随梯度消失的问题,可以搭建ResNet-18残差网络,进行尝试训练。本机算力较差,没有跑出结果过来。