BloombergGPT: A Large Language Model for Finance
先上论文地址,
- paper:https://arxiv.org/abs/2303.17564
BloombergGPT 是彭博社从头自研的大模型,关键词有
- 基于BLOOM模型,70层
- 隐藏层维度7680,多头40
- 约50B参数,700B的token
- 64个AWS X 8块40GB X A100=训练53天
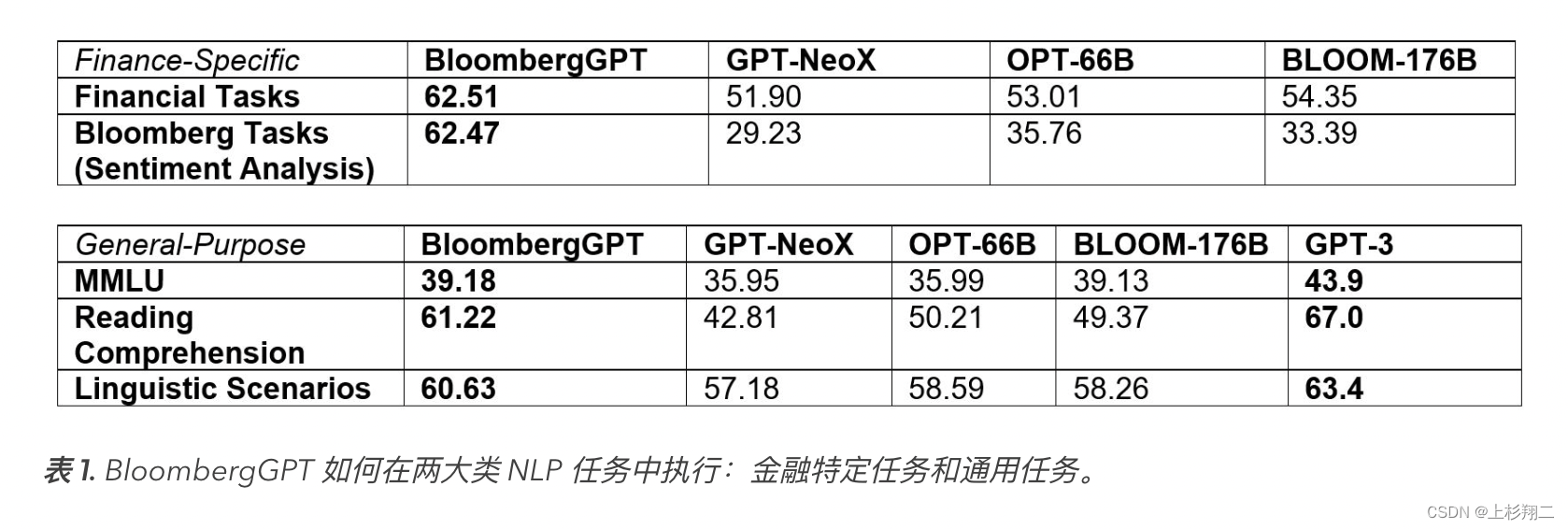
该模型的定位是将协助彭博社改进现有的金融 NLP 任务,例如情感分析、命名实体识别、新闻分类和问答等,以更好地帮助公司的客户。因此它能在通用任务和金融特定任务上都有较好的表现,如上图所示。
数据集
数据集由通用任务数据集和金融数据集一起构成,以创建一个拥有超过7000亿token的大型训练语料库。
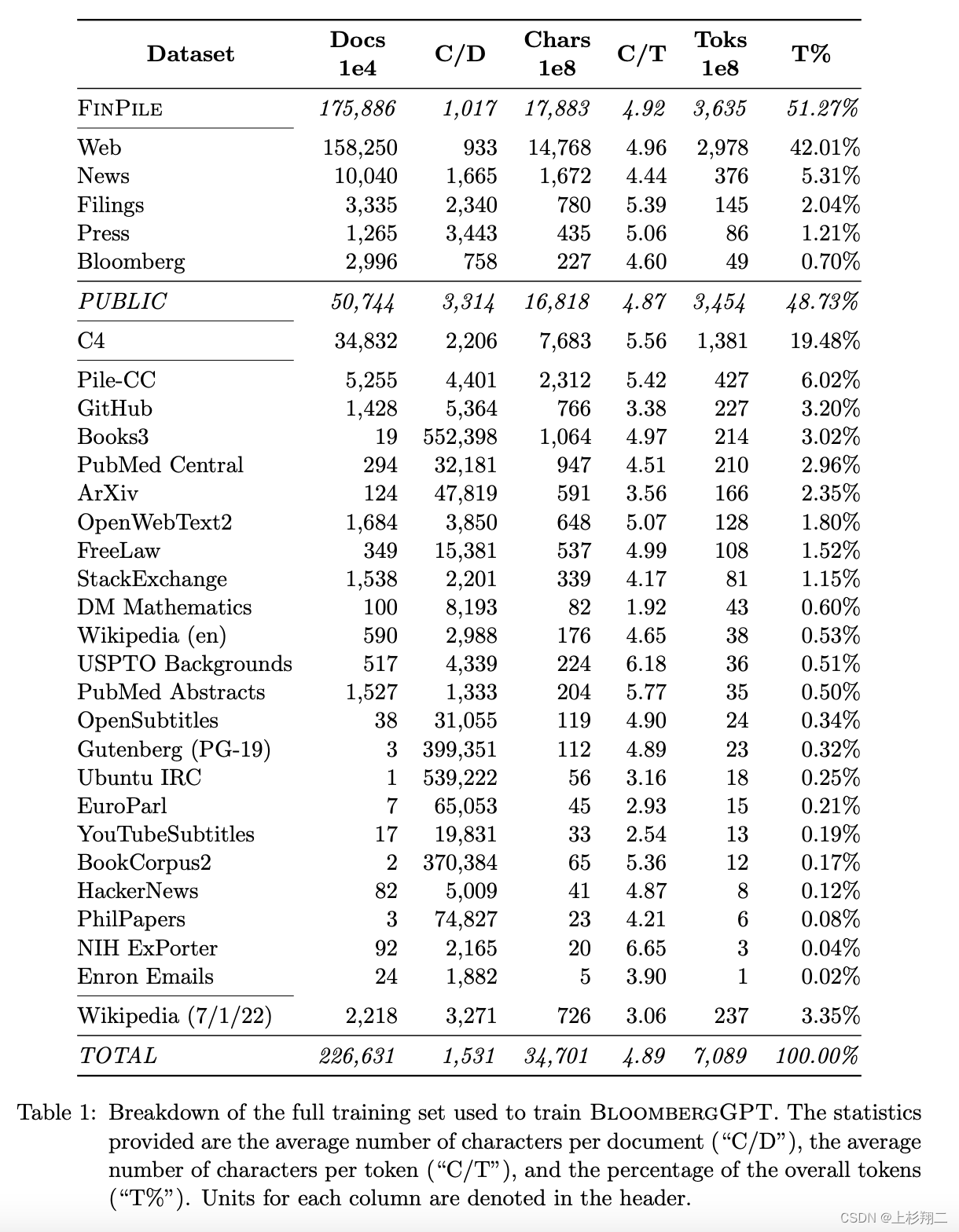
首先通用数据集共包含了3450亿个token,占总数据集token量的48.73%,如上图所示,占比比较大的数据集有:Pile-CC数据集, C4数据集等等等等,以保证模型对自然语言理解的通用能力。
为了打造目前最大的金融领域数据集,彭博社收集和整理了40多年的金融语言文档,其涵盖了一系列的主题,如新闻、档案、英文财经文档等等。这些金融领域数据集共包含了3630亿个token,占总数据集token量的54.2%,具体由以下几个部分构成:
- Web:金融领域相关网页,2978亿token,占比42.01%
- News:金融领域知名新闻源,376亿token,占比5.31%
- Filings:公司财报,145亿token,占比2.04%
- Press:金融相关公司的出版物,86亿token,占比1.21%
- Bloomberg,49亿token,占比0.7%
因为包含一部分收费和私有数据,所以这份数据集不会被公开(emmmmm)。
模型优化
为了减少训练BlumbergGPT在云实例上占用的内存,使用了一系列优化方法:
- ZeRO Optimization (stage 3)。ZeRO优化会在一组gpu中分散训练状态(模型参数、梯度和优化器状态)。BloombergGPT在训练的时候,在128个gpu上分割模型,在训练期间有4个模型的副本。
- MiCS。目标减少云训练集群的训练通信开销和内存需求,MiCS包括分层通信(hierarchical communication)、2跳梯度更新(2-hop gradient update)、尺度感知模型分割(scale-aware model partitioning)。
- Activation Checkpointing。通过消除在反向传递过程中的额外计算为代价,最小化训练内存消耗。当一个层启用了激活检查点时,只有该层的输入和输出在向前传递后被保留在内存中,而任何中间张量都将从内存中被丢弃。在反向传递过程中,这些中间张量可以被重新计算。其中,每个Transformer都会使用Activation Checkpointing。
- 混合精度训练(Mixed Precision Training)。为了减少内存需求,在BF16中进行正向和向后传递,同时以全精度存储和更新参数(FP32)。我们还使用FP32来计算注意块中的softmax(BF16)。最后在FP32中计算了损失函数中的softmax。
- 内核融合(fused kernels)。将多个操作的组合组合成一个GPU操作。这既可以通过避免在计算图中存储中间结果来减少峰值内存的使用,也有助于提高速度。所以作者们在SMP的自注意模块中使用了一个masked-causal-softmax融合核。在实践中,可以观察到4-5个TFLOPs对速度的提高,并在其余的配置中避免了内存不足的错误。
训练过程
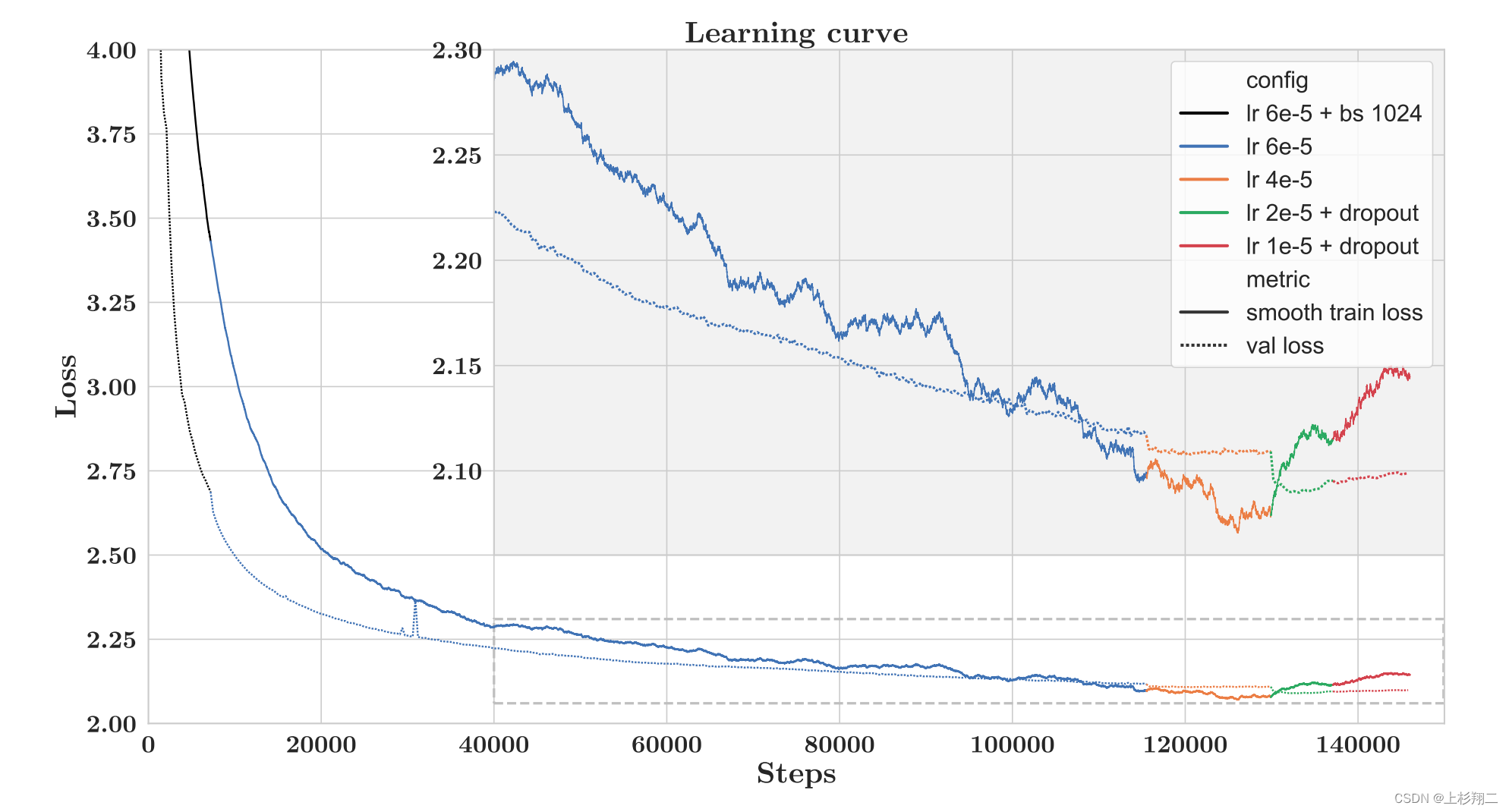
如上图实线表示训练集损失,虚线表示验证集损失,而线条颜色的变化表示一些不同的参数配置。
总共训练了139,200步(~ 53天),并通过训练数据(709B个token中的569B)完成0.8个epoch后结束了模型训练,原因是验证集上的损失已经不再继续下降,甚至反增。
初始训练的batch size大小为1024,warm-up过程持续了7200步,随后将batch size修改为2048。由图可以看到,
- 115,500步之后(蓝变橙),验证集上的损失不再下降,然后将学习率缩小为原始的2/3;
- 129,900步之后(橙变绿),学习率缩小为之前的1/2,同时增加dropout;
- 137,100步之后(绿变红),学习率再次缩小为之前的1/2。
训练在146,000步结束,最后选取139,200这一步的模型作为最终使用的模型
评估
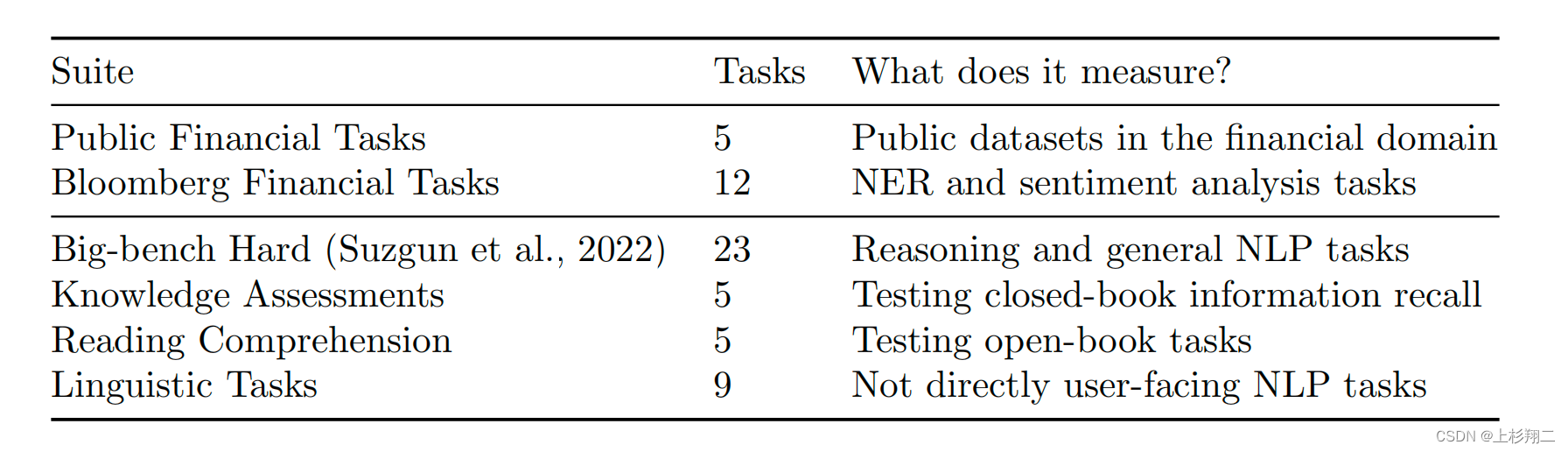
评估在通用和金融的数据集上都测,如上图所示,
- Public Financial Tasks。公共金融任务,5个任务。
- Bloomberg Financial Tasks。彭博金融任务,12任务,主要是NER和情绪分析。对于金融领域来说,情绪分析十分重要,如新闻标题的“公司裁员1万人”一般被认为是负面情绪,这些情绪可能导致股价或投资者信心增加。
- Big-bench Hard。23个任务,推理和一般NLP任务。
- Knowledge Assessments。5个闭卷考试任务。
- Reading Comprehension。5个开卷任务。
- Linguistic Tasks。9个不直接面向用户的NLP任务。
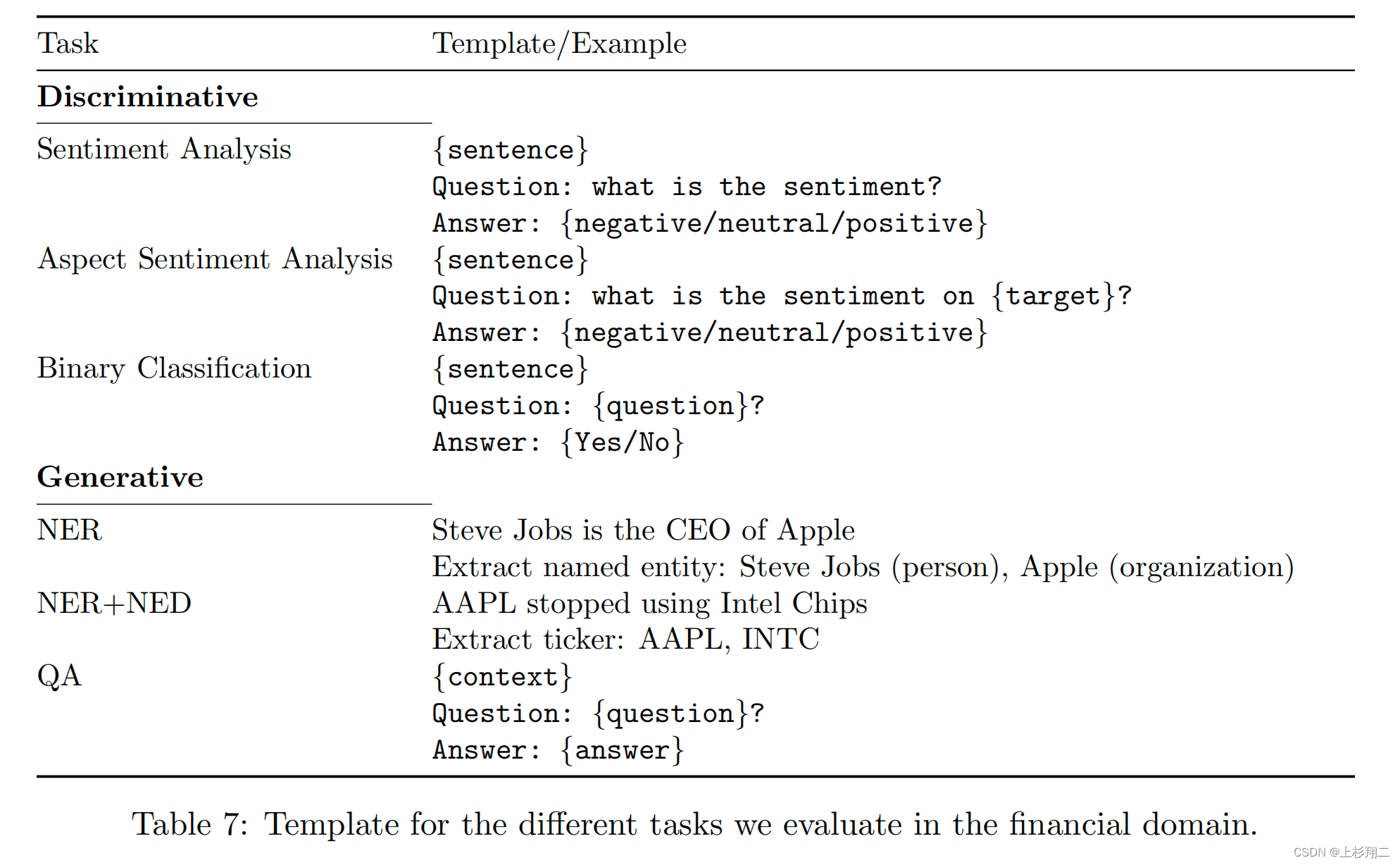
External Financial Tasks的评估主要使用了以下公开数据集,
- FPB。金融短语银行数据集,包括一个对金融新闻句子的情绪分类任务。
- FiQA SA。第二个情绪分析任务是预测英语金融新闻和微博标题中的特定方面的情绪,这些都是2018年金融时尚比赛数据集的一部分,包括金融问题回答和观点挖掘。
- Headline。是一个二元分类任务数据集,即黄金商品领域的新闻标题是否包含某些信息,其每篇新闻文章都带有以下标签的子集:“价格与否”、“价格上涨”、“价格下跌”、“价格稳定”、“过去价格”、“未来价格”、“过去一般”、“未来一般”、“资产比较” 。
- NER。实体识别任务,用于从向美国证券交易委员会提交的财务协议中收集信用风险评估。
- ConvFinQA。输入标准普尔500指数收益报告,其中包括文本和至少一个财务数据表,任务是回答需要对输入进行数字推理的会话问题。这个任务需要数值推理,以及需要对结构化数据和金融概念的理解。
Internal Task的评估是彭博社自己标注的数据集,主要围绕情绪。
- Equity News Sentiment。为了预测新闻报道中对一家公司所表达的特定方面的情绪。该数据集包括来自彭博社的英语新闻报道、付费新闻和网络内容。
- Equity Social Media Sentiment。这项任务类似于上一个任务,但这个使用的是与财务相关的英语社交媒体内容,而不是新闻。
- Equity Transcript Sentiment。同上一个任务类似,使用的是公司新闻发布会的文字记录,而不是新闻。
- ES News Sentiment。预测新闻报道中对一家公司(方面)所表达的特定方面的情绪,但目标并不是表明对投资者信心的影响。
- Country News Sentiment。这个任务不同于其他的情绪任务,因为其目标是预测新闻故事中表达的对一个国家的情绪。该数据集由来自Blo的英语新闻故事组成 嗯,高级,和网络内容。如果新闻报道暗示了该国经济的增长、萎缩或现状,那么这些报道将被标注为“积极”、“消极”或“中性”。
Exploratory Task的评估是彭博社自己标注的数据集,主要围绕NER。
- BN NER:这是一项针对 2017 年至 2020 年间出现在英文长篇彭博新闻内容(“BN wire”)中的实体的命名实体识别任务。
- BFW NER:与“BN NER”类似,但它使用的是 2018 年至 2020 年间“Bloomberg First Word”电报中的短篇故事,而不是使用长篇 BN 电报。
- Filings NER:此任务的目标是识别出现在公司提交的强制性财务披露中的实体。该数据集包含 2016 年至 2019 年期间采样的文件。
- Headlines NER:此任务的目标是识别出现在英文彭博新闻内容标题中的实体。该数据集包含 2016 年至 2020 年间采样的标题。
- Premium NER:此任务的目标是识别出现在彭博获取的第三方英文新闻内容子集中的实体。该数据集包含 2019 年至 2021 年之间采样的故事。
- Transcripts NER:此任务的目标是识别出现在公司新闻发布会笔录中的实体。该数据集包含 2019 年的数据。
- Social Media NER:此任务的目标是识别出现在英语财务相关社交媒体内容中的实体。 该数据集包含 2009 年至 2020 年间采样的社交媒体内容。
探索性任务: NER+NED(命名实体消歧),即不仅抽出实体,还要能链接实体到知识库或其他结构化信息源中的已知实体。在金融世界里,这种技术可以将公司的文本提及与它们的股票代码联系起来,以用来唯一地标识特定股票市场上公开交易的股票。